 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoshimasa Tsuruoka
Enhancing Cross-lingual Sentence Embedding for Low-resource Languages with Word Alignment
Apr 03, 2024
The field of cross-lingual sentence embeddings has recently experienced significant advancements, but research concerning low-resource languages has lagged due to the scarcity of parallel corpora. This paper shows that cross-lingual word representation in low-resource languages is notably under-aligned with that in high-resource languages in current models. To address this, we introduce a novel framework that explicitly aligns words between English and eight low-resource languages, utilizing off-the-shelf word alignment models. This framework incorporates three primary training objectives: aligned word prediction and word translation ranking, along with the widely used translation ranking. We evaluate our approach through experiments on the bitext retrieval task, which demonstrate substantial improvements on sentence embeddings in low-resource languages. In addition, the competitive performance of the proposed model across a broader range of tasks in high-resource languages underscores its practicality.
Leveraging Multi-lingual Positive Instances in Contrastive Learning to Improve Sentence Embedding
Sep 16, 2023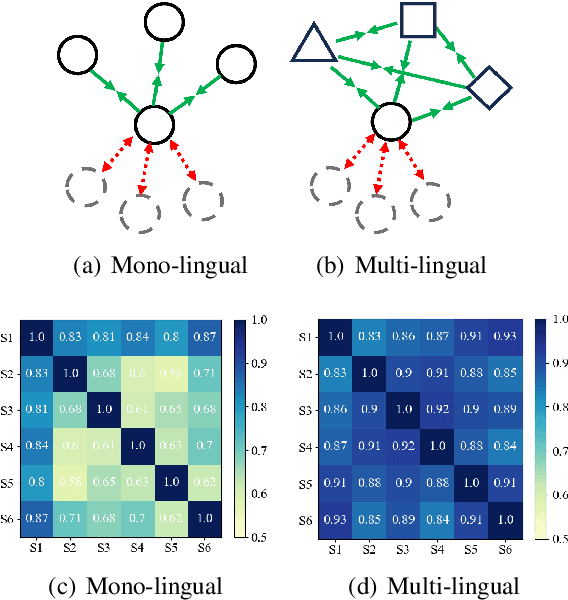
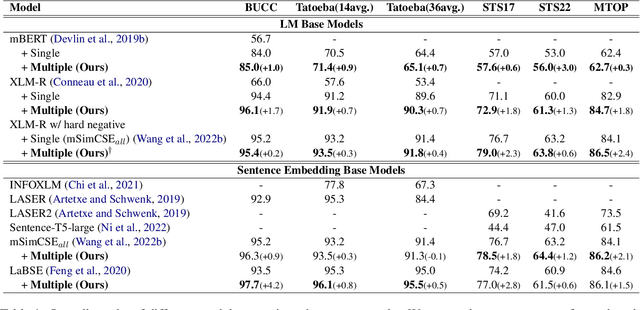
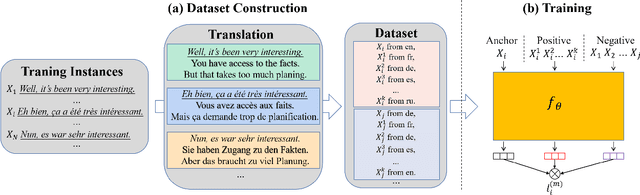
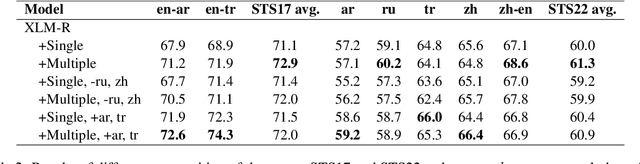
Learning multi-lingual sentence embeddings is a fundamental and significant task in natural language processing. Recent trends of learning both mono-lingual and multi-lingual sentence embeddings are mainly based on contrastive learning (CL) with an anchor, one positive, and multiple negative instances. In this work, we argue that leveraging multiple positives should be considered for multi-lingual sentence embeddings because (1) positives in a diverse set of languages can benefit cross-lingual learning, and (2) transitive similarity across multiple positives can provide reliable structural information to learn. In order to investigate the impact of CL with multiple positives, we propose a novel approach MPCL to effectively utilize multiple positive instances to improve learning multi-lingual sentence embeddings. Our experimental results on various backbone models and downstream tasks support that compared with conventional CL, MPCL leads to better retrieval, semantic similarity, and classification performances. We also observe that on unseen languages, sentence embedding models trained on multiple positives have better cross-lingual transferring performance than models trained on a single positive instance.
WSPAlign: Word Alignment Pre-training via Large-Scale Weakly Supervised Span Prediction
Jun 09, 2023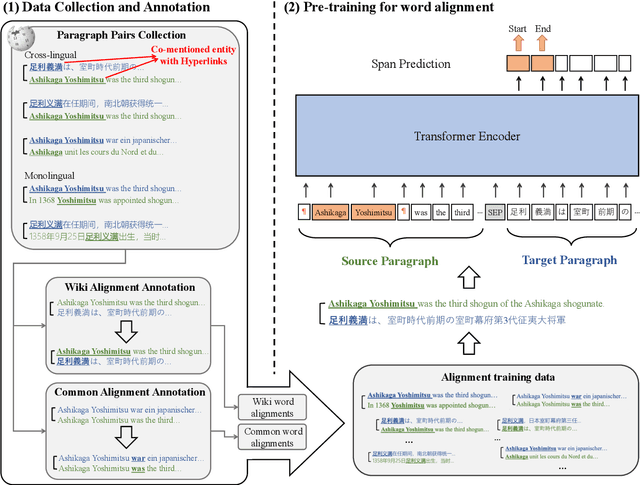
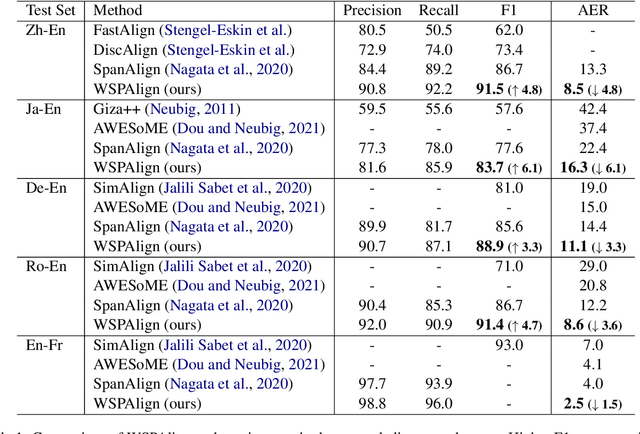
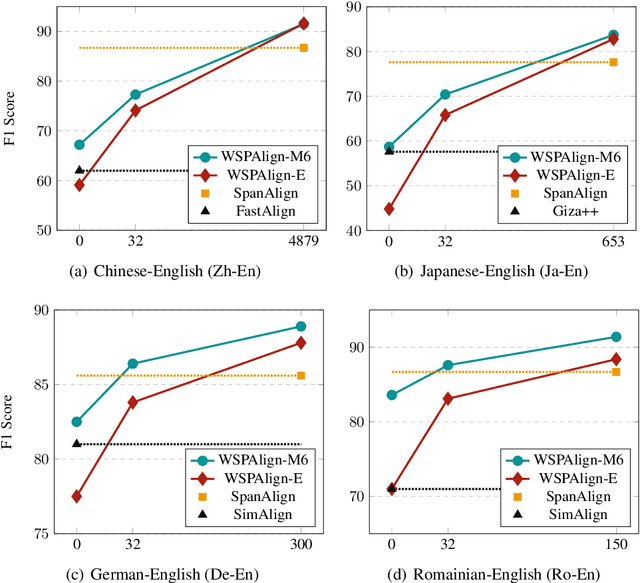
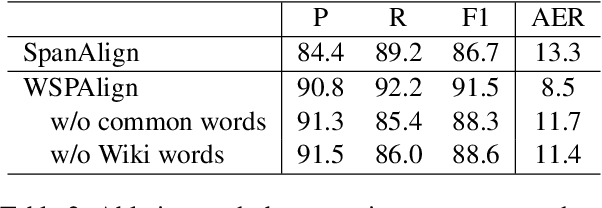
Most existing word alignment methods rely on manual alignment datasets or parallel corpora, which limits their usefulness. Here, to mitigate the dependence on manual data, we broaden the source of supervision by relaxing the requirement for correct, fully-aligned, and parallel sentences. Specifically, we make noisy, partially aligned, and non-parallel paragraphs. We then use such a large-scale weakly-supervised dataset for word alignment pre-training via span prediction. Extensive experiments with various settings empirically demonstrate that our approach, which is named WSPAlign, is an effective and scalable way to pre-train word aligners without manual data. When fine-tuned on standard benchmarks, WSPAlign has set a new state-of-the-art by improving upon the best-supervised baseline by 3.3~6.1 points in F1 and 1.5~6.1 points in AER. Furthermore, WSPAlign also achieves competitive performance compared with the corresponding baselines in few-shot, zero-shot and cross-lingual tests, which demonstrates that WSPAlign is potentially more practical for low-resource languages than existing methods.
Unsupervised Discovery of Continuous Skills on a Sphere
May 25, 2023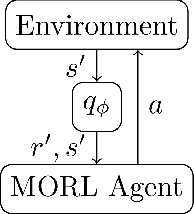


Recently, methods for learning diverse skills to generate various behaviors without external rewards have been actively studied as a form of unsupervised reinforcement learning. However, most of the existing methods learn a finite number of discrete skills, and thus the variety of behaviors that can be exhibited with the learned skills is limited. In this paper, we propose a novel method for learning potentially an infinite number of different skills, which is named discovery of continuous skills on a sphere (DISCS). In DISCS, skills are learned by maximizing mutual information between skills and states, and each skill corresponds to a continuous value on a sphere. Because the representations of skills in DISCS are continuous, infinitely diverse skills could be learned. We examine existing methods and DISCS in the MuJoCo Ant robot control environments and show that DISCS can learn much more diverse skills than the other methods.
Which Experiences Are Influential for Your Agent? Policy Iteration with Turn-over Dropout
Jan 26, 2023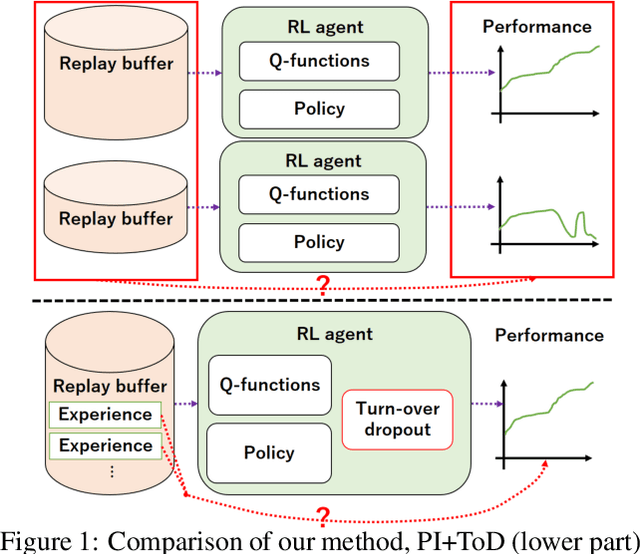
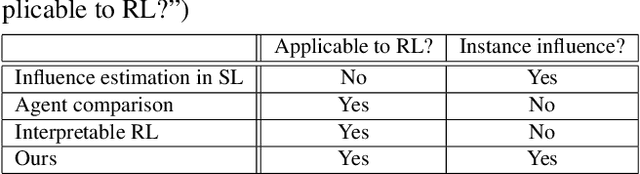
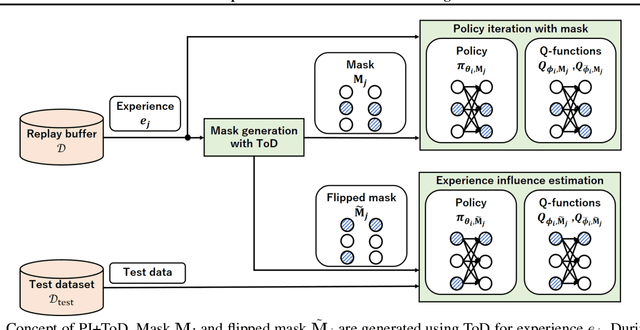
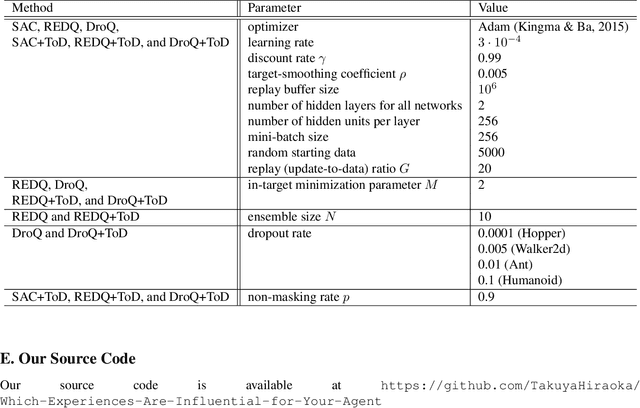
In reinforcement learning (RL) with experience replay, experiences stored in a replay buffer influence the RL agent's performance. Information about the influence is valuable for various purposes, including experience cleansing and analysis. One method for estimating the influence of individual experiences is agent comparison, but it is prohibitively expensive when there is a large number of experiences. In this paper, we present PI+ToD as a method for efficiently estimating the influence of experiences. PI+ToD is a policy iteration that efficiently estimates the influence of experiences by utilizing turn-over dropout. We demonstrate the efficiency of PI+ToD with experiments in MuJoCo environments.
Soft Sensors and Process Control using AI and Dynamic Simulation
Aug 08, 2022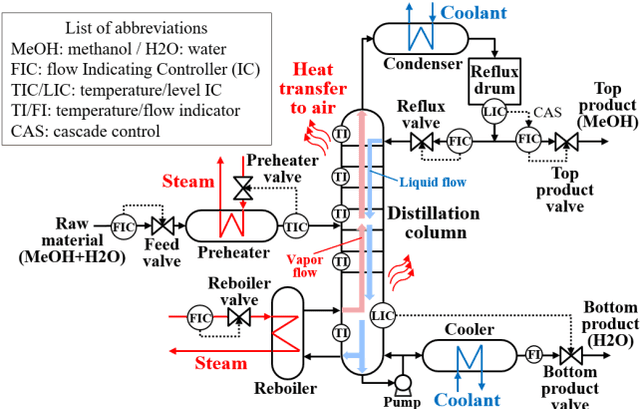
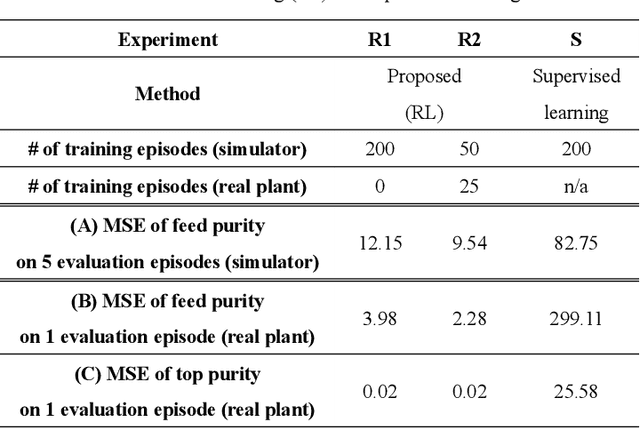
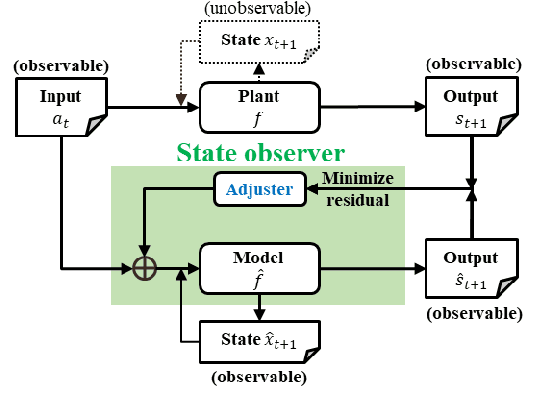
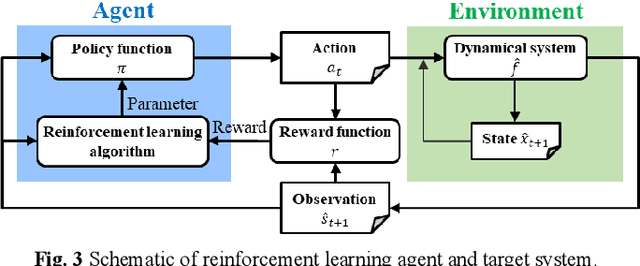
During the operation of a chemical plant, product quality must be consistently maintained, and the production of off-specification products should be minimized. Accordingly, process variables related to the product quality, such as the temperature and composition of materials at various parts of the plant must be measured, and appropriate operations (that is, control) must be performed based on the measurements. Some process variables, such as temperature and flow rate, can be measured continuously and instantaneously. However, other variables, such as composition and viscosity, can only be obtained through time-consuming analysis after sampling substances from the plant. Soft sensors have been proposed for estimating process variables that cannot be obtained in real time from easily measurable variables. However, the estimation accuracy of conventional statistical soft sensors, which are constructed from recorded measurements, can be very poor in unrecorded situations (extrapolation). In this study, we estimate the internal state variables of a plant by using a dynamic simulator that can estimate and predict even unrecorded situations on the basis of chemical engineering knowledge and an artificial intelligence (AI) technology called reinforcement learning, and propose to use the estimated internal state variables of a plant as soft sensors. In addition, we describe the prospects for plant operation and control using such soft sensors and the methodology to obtain the necessary prediction models (i.e., simulators) for the proposed system.
* This is an English version of the research paper in Japanese translated by the original authors. The original paper is published in Kagaku Kogaku Ronbunsyu by the Society of Chemical Engineers, Japan (SCEJ) on July 20th, 2022 (DOI: 10.1252/kakoronbunshu.48.141)
EASE: Entity-Aware Contrastive Learning of Sentence Embedding
May 09, 2022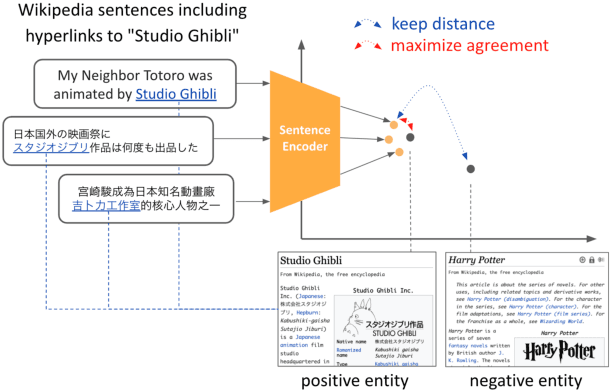
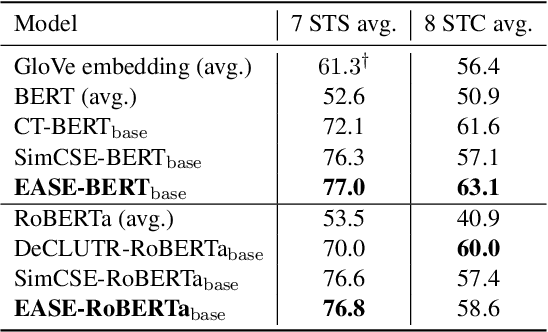

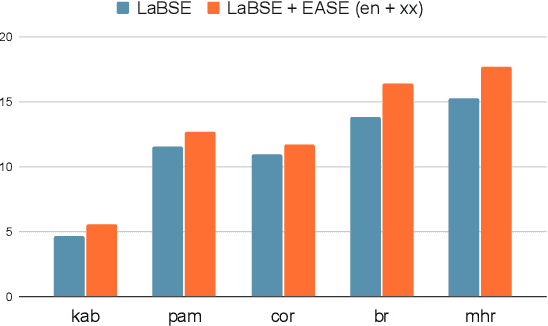
We present EASE, a novel method for learning sentence embeddings via contrastive learning between sentences and their related entities. The advantage of using entity supervision is twofold: (1) entities have been shown to be a strong indicator of text semantics and thus should provide rich training signals for sentence embeddings; (2) entities are defined independently of languages and thus offer useful cross-lingual alignment supervision. We evaluate EASE against other unsupervised models both in monolingual and multilingual settings. We show that EASE exhibits competitive or better performance in English semantic textual similarity (STS) and short text clustering (STC) tasks and it significantly outperforms baseline methods in multilingual settings on a variety of tasks. Our source code, pre-trained models, and newly constructed multilingual STC dataset are available at https://github.com/studio-ousia/ease.
Pretraining with Artificial Language: Studying Transferable Knowledge in Language Models
Mar 22, 2022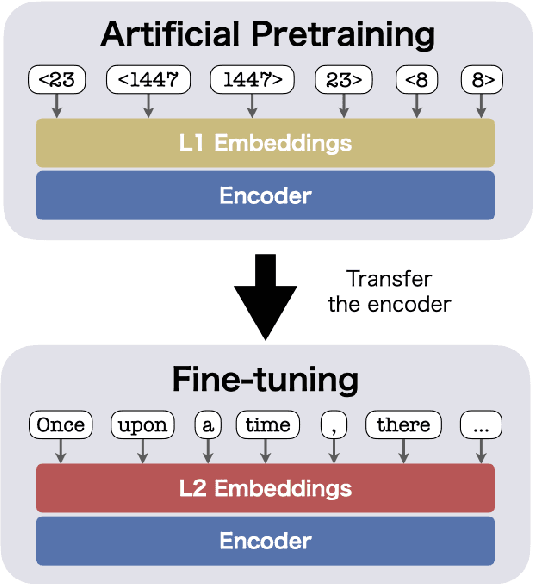

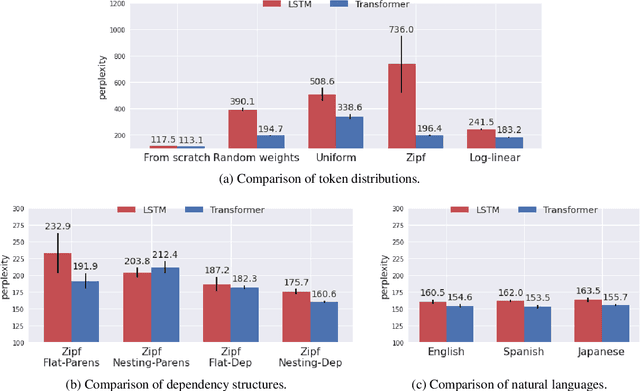

We investigate what kind of structural knowledge learned in neural network encoders is transferable to processing natural language. We design artificial languages with structural properties that mimic natural language, pretrain encoders on the data, and see how much performance the encoder exhibits on downstream tasks in natural language. Our experimental results show that pretraining with an artificial language with a nesting dependency structure provides some knowledge transferable to natural language. A follow-up probing analysis indicates that its success in the transfer is related to the amount of encoded contextual information and what is transferred is the knowledge of position-aware context dependence of language. Our results provide insights into how neural network encoders process human languages and the source of cross-lingual transferability of recent multilingual language models.
Railway Operation Rescheduling System via Dynamic Simulation and Reinforcement Learning
Jan 17, 2022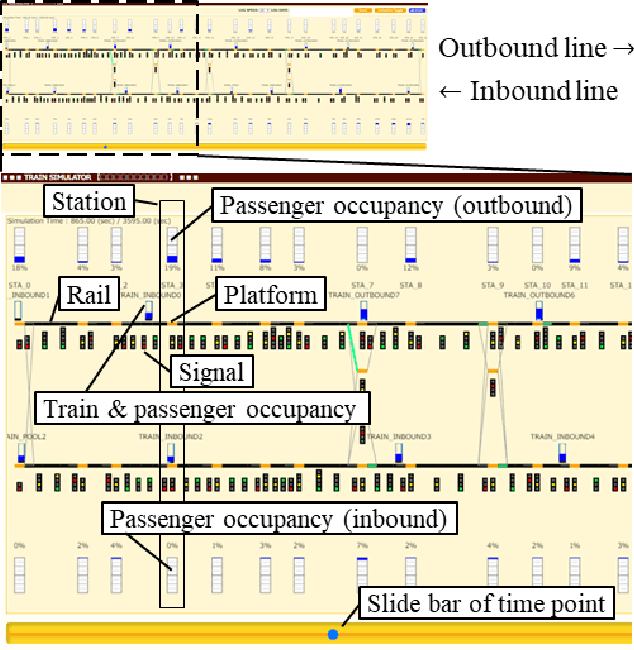
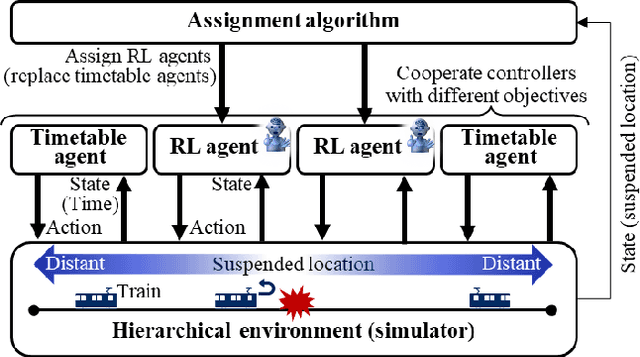
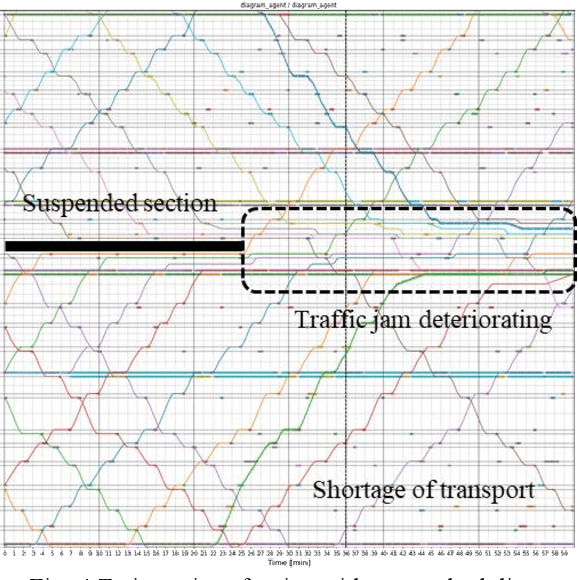
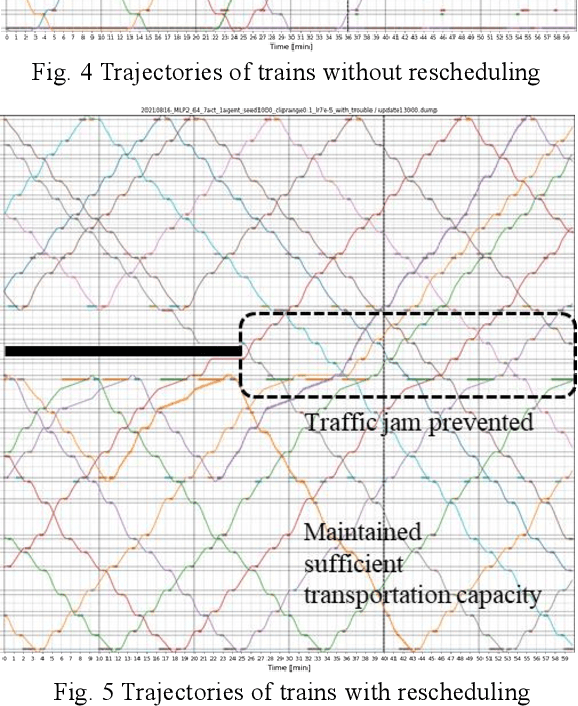
The number of railway service disruptions has been increasing owing to intensification of natural disasters. In addition, abrupt changes in social situations such as the COVID-19 pandemic require railway companies to modify the traffic schedule frequently. Therefore, automatic support for optimal scheduling is anticipated. In this study, an automatic railway scheduling system is presented. The system leverages reinforcement learning and a dynamic simulator that can simulate the railway traffic and passenger flow of a whole line. The proposed system enables rapid generation of the traffic schedule of a whole line because the optimization process is conducted in advance as the training. The system is evaluated using an interruption scenario, and the results demonstrate that the system can generate optimized schedules of the whole line in a few minutes.