 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Nishiyama
Short-Term Wind-Speed Forecasting Using Kernel Spectral Hidden Markov Models
Nov 15, 2018
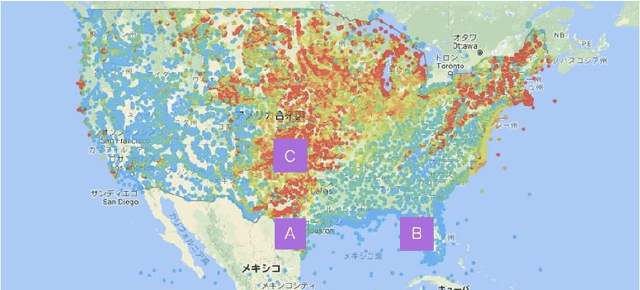
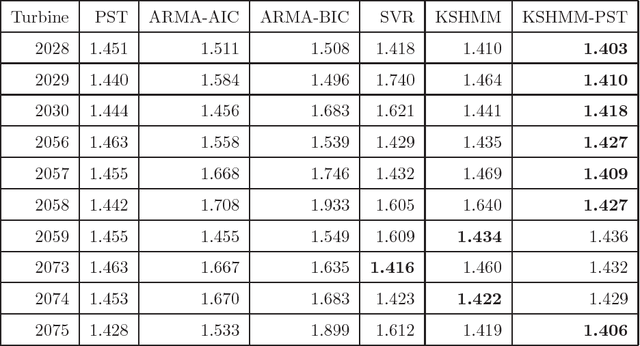
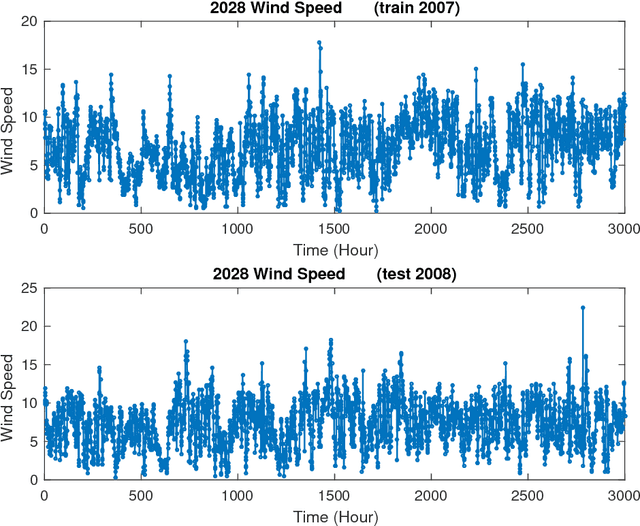
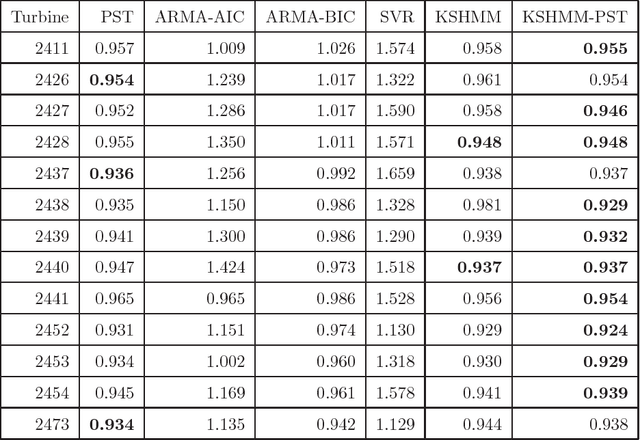
In machine learning, a nonparametric forecasting algorithm for time series data has been proposed, called the kernel spectral hidden Markov model (KSHMM). In this paper, we propose a technique for short-term wind-speed prediction based on KSHMM. We numerically compared the performance of our KSHMM-based forecasting technique to other techniques with machine learning, using wind-speed data offered by the National Renewable Energy Laboratory. Our results demonstrate that, compared to these methods, the proposed technique offers comparable or better performance.
Model-based Kernel Sum Rule: Kernel Bayesian Inference with Probabilistic Models
Apr 05, 2018
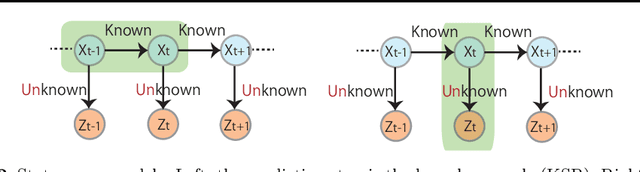
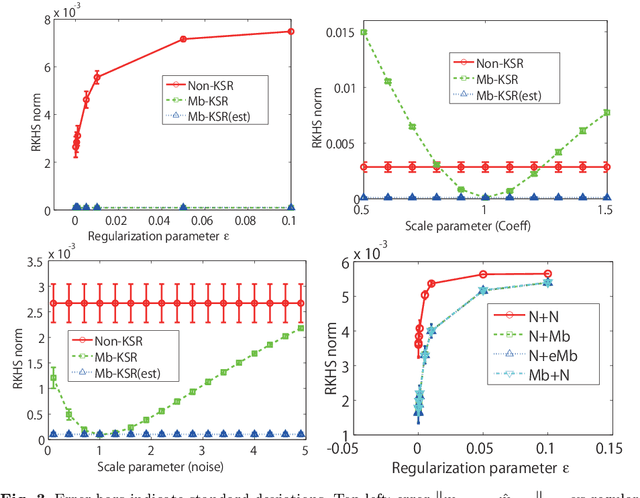
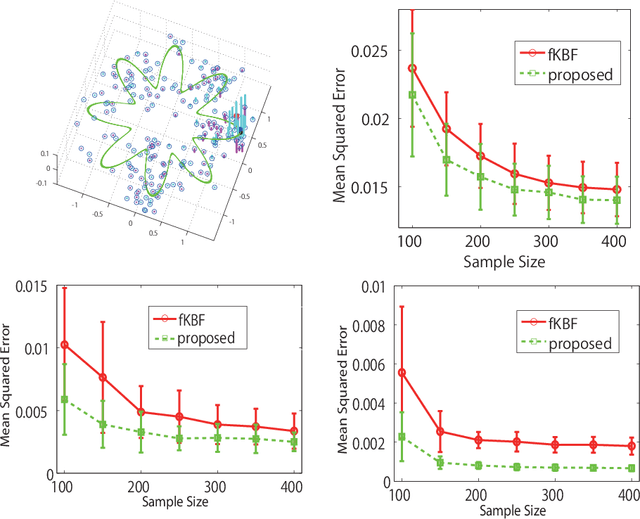
Kernel Bayesian inference is a powerful nonparametric approach to performing Bayesian inference in reproducing kernel Hilbert spaces or feature spaces. In this approach, kernel means are estimated instead of probability distributions, and these estimates can be used for subsequent probabilistic operations (as for inference in graphical models) or in computing the expectations of smooth functions, for instance. Various algorithms for kernel Bayesian inference have been obtained by combining basic rules such as the kernel sum rule (KSR), kernel chain rule, kernel product rule and kernel Bayes' rule. However, the current framework only deals with fully nonparametric inference (i.e., all conditional relations are learned nonparametrically), and it does not allow for flexible combinations of nonparametric and parametric inference, which are practically important. Our contribution is in providing a novel technique to realize such combinations. We introduce a new KSR referred to as the model-based KSR (Mb-KSR), which employs the sum rule in feature spaces under a parametric setting. Incorporating the Mb-KSR into existing kernel Bayesian framework provides a richer framework for hybrid (nonparametric and parametric) kernel Bayesian inference. As a practical application, we propose a novel filtering algorithm for state space models based on the Mb-KSR, which combines the nonparametric learning of an observation process using kernel mean embedding and the additive Gaussian noise model for a state transition process. While we focus on additive Gaussian noise models in this study, the idea can be extended to other noise models, such as the Cauchy and alpha-stable noise models.
Characteristic Kernels and Infinitely Divisible Distributions
Oct 25, 2016We connect shift-invariant characteristic kernels to infinitely divisible distributions on $\mathbb{R}^{d}$. Characteristic kernels play an important role in machine learning applications with their kernel means to distinguish any two probability measures. The contribution of this paper is two-fold. First, we show, using the L\'evy-Khintchine formula, that any shift-invariant kernel given by a bounded, continuous and symmetric probability density function (pdf) of an infinitely divisible distribution on $\mathbb{R}^d$ is characteristic. We also present some closure property of such characteristic kernels under addition, pointwise product, and convolution. Second, in developing various kernel mean algorithms, it is fundamental to compute the following values: (i) kernel mean values $m_P(x)$, $x \in \mathcal{X}$, and (ii) kernel mean RKHS inner products ${\left\langle m_P, m_Q \right\rangle_{\mathcal{H}}}$, for probability measures $P, Q$. If $P, Q$, and kernel $k$ are Gaussians, then computation (i) and (ii) results in Gaussian pdfs that is tractable. We generalize this Gaussian combination to more general cases in the class of infinitely divisible distributions. We then introduce a {\it conjugate} kernel and {\it convolution trick}, so that the above (i) and (ii) have the same pdf form, expecting tractable computation at least in some cases. As specific instances, we explore $\alpha$-stable distributions and a rich class of generalized hyperbolic distributions, where the Laplace, Cauchy and Student-t distributions are included.
Filtering with State-Observation Examples via Kernel Monte Carlo Filter
Oct 22, 2015This paper addresses the problem of filtering with a state-space model. Standard approaches for filtering assume that a probabilistic model for observations (i.e. the observation model) is given explicitly or at least parametrically. We consider a setting where this assumption is not satisfied; we assume that the knowledge of the observation model is only provided by examples of state-observation pairs. This setting is important and appears when state variables are defined as quantities that are very different from the observations. We propose Kernel Monte Carlo Filter, a novel filtering method that is focused on this setting. Our approach is based on the framework of kernel mean embeddings, which enables nonparametric posterior inference using the state-observation examples. The proposed method represents state distributions as weighted samples, propagates these samples by sampling, estimates the state posteriors by Kernel Bayes' Rule, and resamples by Kernel Herding. In particular, the sampling and resampling procedures are novel in being expressed using kernel mean embeddings, so we theoretically analyze their behaviors. We reveal the following properties, which are similar to those of corresponding procedures in particle methods: (1) the performance of sampling can degrade if the effective sample size of a weighted sample is small; (2) resampling improves the sampling performance by increasing the effective sample size. We first demonstrate these theoretical findings by synthetic experiments. Then we show the effectiveness of the proposed filter by artificial and real data experiments, which include vision-based mobile robot localization.
Hilbert Space Embeddings of POMDPs
Oct 16, 2012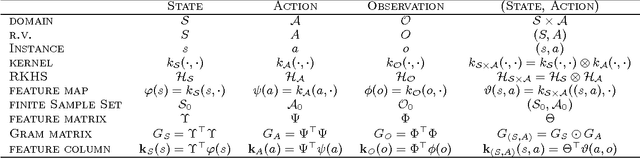
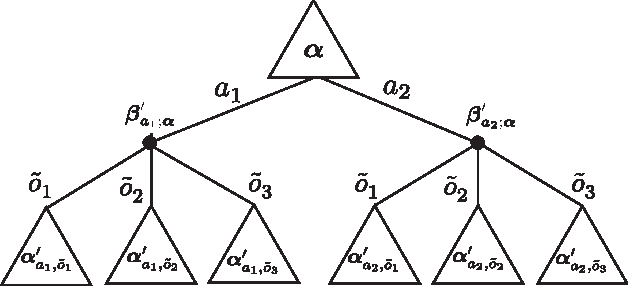
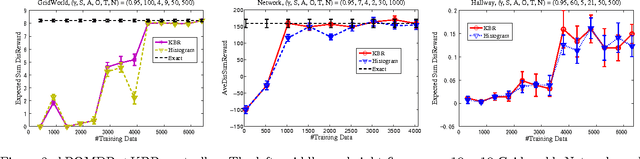

A nonparametric approach for policy learning for POMDPs is proposed. The approach represents distributions over the states, observations, and actions as embeddings in feature spaces, which are reproducing kernel Hilbert spaces. Distributions over states given the observations are obtained by applying the kernel Bayes' rule to these distribution embeddings. Policies and value functions are defined on the feature space over states, which leads to a feature space expression for the Bellman equation. Value iteration may then be used to estimate the optimal value function and associated policy. Experimental results confirm that the correct policy is learned using the feature space representation.