 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan Dong
An Optimization Framework to Enforce Multi-View Consistency for Texturing 3D Meshes Using Pre-Trained Text-to-Image Models
Mar 22, 2024
A fundamental problem in the texturing of 3D meshes using pre-trained text-to-image models is to ensure multi-view consistency. State-of-the-art approaches typically use diffusion models to aggregate multi-view inputs, where common issues are the blurriness caused by the averaging operation in the aggregation step or inconsistencies in local features. This paper introduces an optimization framework that proceeds in four stages to achieve multi-view consistency. Specifically, the first stage generates an over-complete set of 2D textures from a predefined set of viewpoints using an MV-consistent diffusion process. The second stage selects a subset of views that are mutually consistent while covering the underlying 3D model. We show how to achieve this goal by solving semi-definite programs. The third stage performs non-rigid alignment to align the selected views across overlapping regions. The fourth stage solves an MRF problem to associate each mesh face with a selected view. In particular, the third and fourth stages are iterated, with the cuts obtained in the fourth stage encouraging non-rigid alignment in the third stage to focus on regions close to the cuts. Experimental results show that our approach significantly outperforms baseline approaches both qualitatively and quantitatively.
VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model
Mar 18, 2024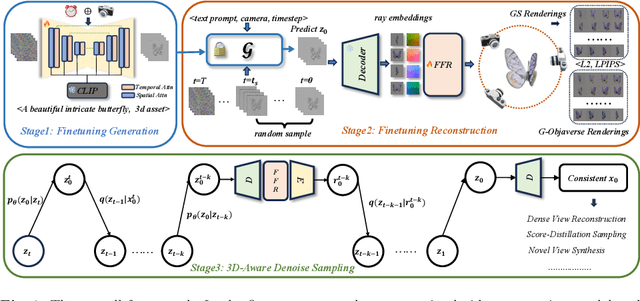
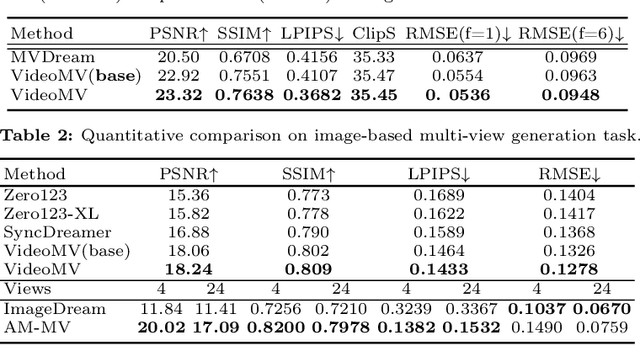


Generating multi-view images based on text or single-image prompts is a critical capability for the creation of 3D content. Two fundamental questions on this topic are what data we use for training and how to ensure multi-view consistency. This paper introduces a novel framework that makes fundamental contributions to both questions. Unlike leveraging images from 2D diffusion models for training, we propose a dense consistent multi-view generation model that is fine-tuned from off-the-shelf video generative models. Images from video generative models are more suitable for multi-view generation because the underlying network architecture that generates them employs a temporal module to enforce frame consistency. Moreover, the video data sets used to train these models are abundant and diverse, leading to a reduced train-finetuning domain gap. To enhance multi-view consistency, we introduce a 3D-Aware Denoising Sampling, which first employs a feed-forward reconstruction module to get an explicit global 3D model, and then adopts a sampling strategy that effectively involves images rendered from the global 3D model into the denoising sampling loop to improve the multi-view consistency of the final images. As a by-product, this module also provides a fast way to create 3D assets represented by 3D Gaussians within a few seconds. Our approach can generate 24 dense views and converges much faster in training than state-of-the-art approaches (4 GPU hours versus many thousand GPU hours) with comparable visual quality and consistency. By further fine-tuning, our approach outperforms existing state-of-the-art methods in both quantitative metrics and visual effects. Our project page is aigc3d.github.io/VideoMV.
URHand: Universal Relightable Hands
Jan 10, 2024Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
Opara: Exploiting Operator Parallelism for Expediting DNN Inference on GPUs
Dec 16, 2023GPUs have become the defacto hardware devices to accelerate Deep Neural Network (DNN) inference in deep learning(DL) frameworks. However, the conventional sequential execution mode of DNN operators in mainstream DL frameworks cannot fully utilize GPU resources, due to the increasing complexity of DNN model structures and the progressively smaller computational sizes of DNN operators. Moreover, the inadequate operator launch order in parallelized execution scenarios can lead to GPU resource wastage and unexpected performance interference among operators. To address such performance issues above, we propose Opara, a resource- and interference-aware DNN Operator parallel scheduling framework to accelerate the execution of DNN inference on GPUs. Specifically, Opara first employs CUDA Streams and CUDA Graph to automatically parallelize the execution of multiple DNN operators. It further leverages the resource demands of DNN operators to judiciously adjust the operator launch order on GPUs by overlapping the execution of compute-intensive and memory-intensive operators, so as to expedite DNN inference. We implement and open source a prototype of Opara based on PyTorch in a non-intrusive manner. Extensive prototype experiments with representative DNN and Transformer-based models demonstrate that Opara outperforms the default sequential CUDA Graph in PyTorch and the state-of-the-art DNN operator parallelism systems by up to 1.68$\times$ and 1.29$\times$, respectively, yet with acceptable runtime overhead.
Video-based Visible-Infrared Person Re-Identification with Auxiliary Samples
Nov 27, 2023Visible-infrared person re-identification (VI-ReID) aims to match persons captured by visible and infrared cameras, allowing person retrieval and tracking in 24-hour surveillance systems. Previous methods focus on learning from cross-modality person images in different cameras. However, temporal information and single-camera samples tend to be neglected. To crack this nut, in this paper, we first contribute a large-scale VI-ReID dataset named BUPTCampus. Different from most existing VI-ReID datasets, it 1) collects tracklets instead of images to introduce rich temporal information, 2) contains pixel-aligned cross-modality sample pairs for better modality-invariant learning, 3) provides one auxiliary set to help enhance the optimization, in which each identity only appears in a single camera. Based on our constructed dataset, we present a two-stream framework as baseline and apply Generative Adversarial Network (GAN) to narrow the gap between the two modalities. To exploit the advantages introduced by the auxiliary set, we propose a curriculum learning based strategy to jointly learn from both primary and auxiliary sets. Moreover, we design a novel temporal k-reciprocal re-ranking method to refine the ranking list with fine-grained temporal correlation cues. Experimental results demonstrate the effectiveness of the proposed methods. We also reproduce 9 state-of-the-art image-based and video-based VI-ReID methods on BUPTCampus and our methods show substantial superiority to them. The codes and dataset are available at: https://github.com/dyhBUPT/BUPTCampus.
PanoContext-Former: Panoramic Total Scene Understanding with a Transformer
May 21, 2023
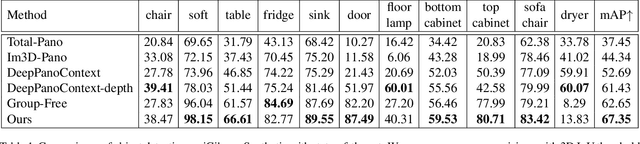
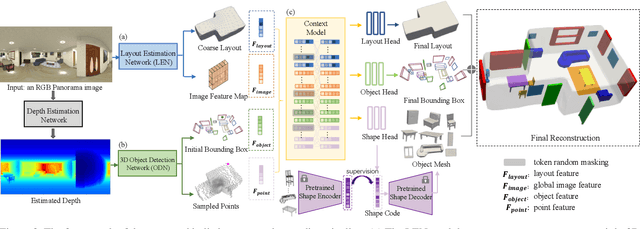

Panoramic image enables deeper understanding and more holistic perception of $360^\circ$ surrounding environment, which can naturally encode enriched scene context information compared to standard perspective image. Previous work has made lots of effort to solve the scene understanding task in a bottom-up form, thus each sub-task is processed separately and few correlations are explored in this procedure. In this paper, we propose a novel method using depth prior for holistic indoor scene understanding which recovers the objects' shapes, oriented bounding boxes and the 3D room layout simultaneously from a single panorama. In order to fully utilize the rich context information, we design a transformer-based context module to predict the representation and relationship among each component of the scene. In addition, we introduce a real-world dataset for scene understanding, including photo-realistic panoramas, high-fidelity depth images, accurately annotated room layouts, and oriented object bounding boxes and shapes. Experiments on the synthetic and real-world datasets demonstrate that our method outperforms previous panoramic scene understanding methods in terms of both layout estimation and 3D object detection.
PanoViT: Vision Transformer for Room Layout Estimation from a Single Panoramic Image
Dec 23, 2022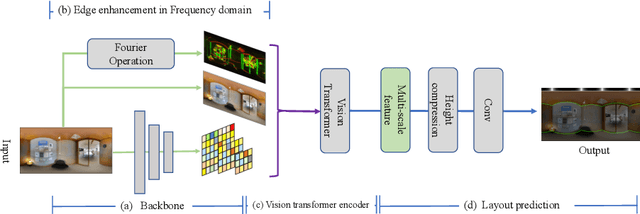
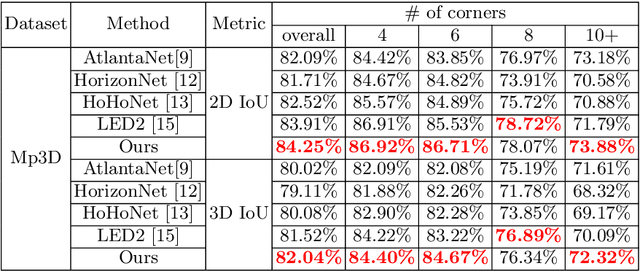
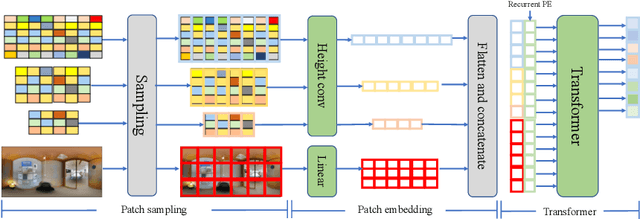
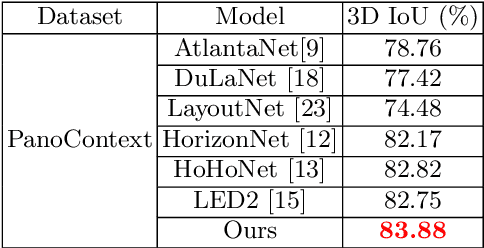
In this paper, we propose PanoViT, a panorama vision transformer to estimate the room layout from a single panoramic image. Compared to CNN models, our PanoViT is more proficient in learning global information from the panoramic image for the estimation of complex room layouts. Considering the difference between a perspective image and an equirectangular image, we design a novel recurrent position embedding and a patch sampling method for the processing of panoramic images. In addition to extracting global information, PanoViT also includes a frequency-domain edge enhancement module and a 3D loss to extract local geometric features in a panoramic image. Experimental results on several datasets demonstrate that our method outperforms state-of-the-art solutions in room layout prediction accuracy.
Caption Feature Space Regularization for Audio Captioning
Apr 18, 2022
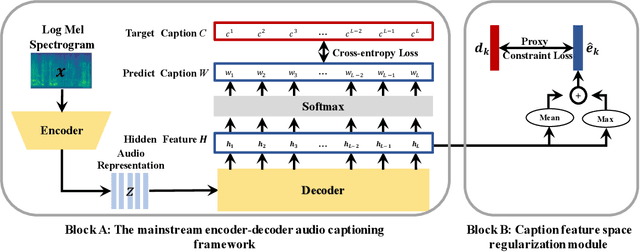
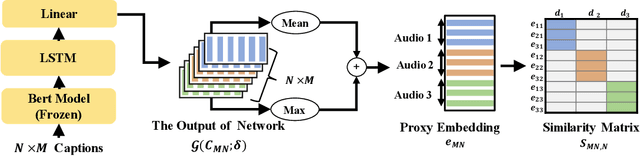
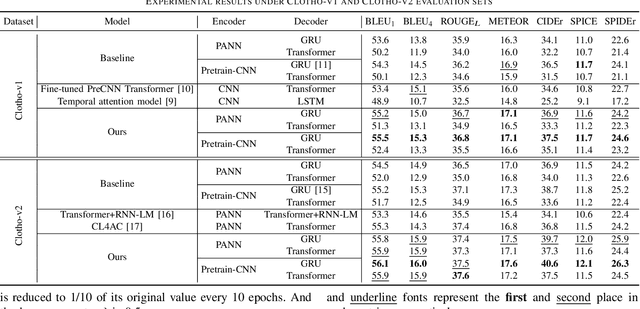
Audio captioning aims at describing the content of audio clips with human language. Due to the ambiguity of audio, different people may perceive the same audio differently, resulting in caption disparities (i.e., one audio may correlate to several captions with diverse semantics). For that, general audio captioning models achieve the one-to-many training by randomly selecting a correlated caption as the ground truth for each audio. However, it leads to a significant variation in the optimization directions and weakens the model stability. To eliminate this negative effect, in this paper, we propose a two-stage framework for audio captioning: (i) in the first stage, via the contrastive learning, we construct a proxy feature space to reduce the distances between captions correlated to the same audio, and (ii) in the second stage, the proxy feature space is utilized as additional supervision to encourage the model to be optimized in the direction that benefits all the correlated captions. We conducted extensive experiments on two datasets using four commonly used encoder and decoder architectures. Experimental results demonstrate the effectiveness of the proposed method. The code is available at https://github.com/PRIS-CV/Caption-Feature-Space-Regularization.
Explicit Clothing Modeling for an Animatable Full-Body Avatar
Jun 30, 2021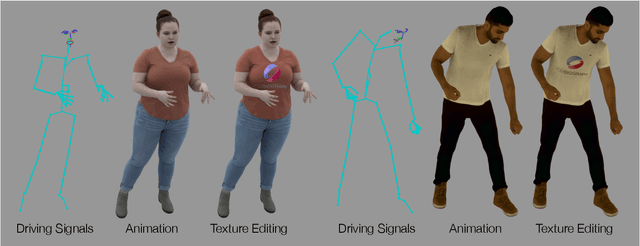
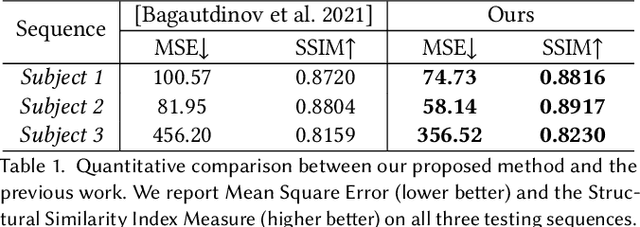

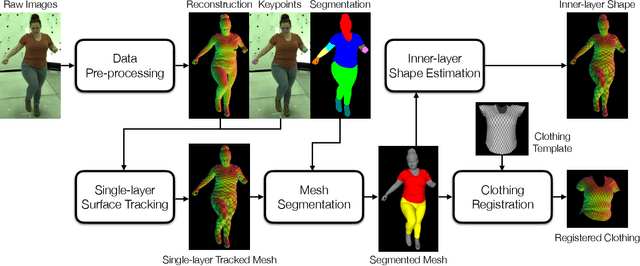
Recent work has shown great progress in building photorealistic animatable full-body codec avatars, but these avatars still face difficulties in generating high-fidelity animation of clothing. To address the difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to separately register the 3D scans with templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over single-layer avatars in the previous work. We also show the benefit of an explicit clothing model which allows the clothing texture to be edited in the animation output.