 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFangming Liu
TrimCaching: Parameter-sharing AI Model Caching in Wireless Edge Networks
May 07, 2024
Next-generation mobile networks are expected to facilitate fast AI model downloading to end users. By caching models on edge servers, mobile networks can deliver models to end users with low latency, resulting in a paradigm called edge model caching. In this paper, we develop a novel model placement scheme, called parameter-sharing model caching (TrimCaching). TrimCaching exploits the key observation that a wide range of AI models, such as convolutional neural networks or large language models, can share a significant proportion of parameter blocks containing reusable knowledge, thereby improving storage efficiency. To this end, we formulate a parameter-sharing model placement problem to maximize the cache hit ratio in multi-edge wireless networks by balancing the fundamental tradeoff between storage efficiency and service latency. We show that the formulated problem is a submodular maximization problem with submodular constraints, for which no polynomial-time approximation algorithm exists. To overcome this challenge, we study an important special case, where a small fixed number of parameter blocks are shared across models, which often holds in practice. In such a case, a polynomial-time algorithm with $\left(1-\epsilon\right)/2$-approximation guarantee is developed. Subsequently, we address the original problem for the general case by developing a greedy algorithm. Simulation results demonstrate that the proposed TrimCaching framework significantly improves the cache hit ratio compared with state-of-the-art content caching without exploiting shared parameters in AI models.
Opara: Exploiting Operator Parallelism for Expediting DNN Inference on GPUs
Dec 16, 2023GPUs have become the defacto hardware devices to accelerate Deep Neural Network (DNN) inference in deep learning(DL) frameworks. However, the conventional sequential execution mode of DNN operators in mainstream DL frameworks cannot fully utilize GPU resources, due to the increasing complexity of DNN model structures and the progressively smaller computational sizes of DNN operators. Moreover, the inadequate operator launch order in parallelized execution scenarios can lead to GPU resource wastage and unexpected performance interference among operators. To address such performance issues above, we propose Opara, a resource- and interference-aware DNN Operator parallel scheduling framework to accelerate the execution of DNN inference on GPUs. Specifically, Opara first employs CUDA Streams and CUDA Graph to automatically parallelize the execution of multiple DNN operators. It further leverages the resource demands of DNN operators to judiciously adjust the operator launch order on GPUs by overlapping the execution of compute-intensive and memory-intensive operators, so as to expedite DNN inference. We implement and open source a prototype of Opara based on PyTorch in a non-intrusive manner. Extensive prototype experiments with representative DNN and Transformer-based models demonstrate that Opara outperforms the default sequential CUDA Graph in PyTorch and the state-of-the-art DNN operator parallelism systems by up to 1.68$\times$ and 1.29$\times$, respectively, yet with acceptable runtime overhead.
On-edge Multi-task Transfer Learning: Model and Practice with Data-driven Task Allocation
Jul 06, 2021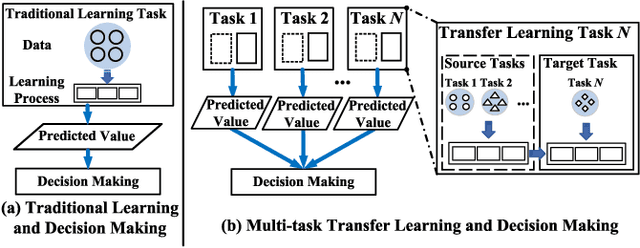

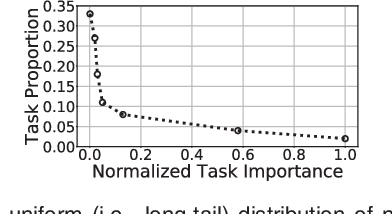

On edge devices, data scarcity occurs as a common problem where transfer learning serves as a widely-suggested remedy. Nevertheless, transfer learning imposes a heavy computation burden to resource-constrained edge devices. Existing task allocation works usually assume all submitted tasks are equally important, leading to inefficient resource allocation at a task level when directly applied in Multi-task Transfer Learning (MTL). To address these issues, we first reveal that it is crucial to measure the impact of tasks on overall decision performance improvement and quantify \emph{task importance}. We then show that task allocation with task importance for MTL (TATIM) is a variant of the NP-complete Knapsack problem, where the complicated computation to solve this problem needs to be conducted repeatedly under varying contexts. To solve TATIM with high computational efficiency, we propose a Data-driven Cooperative Task Allocation (DCTA) approach. Finally, we evaluate the performance of DCTA by not only a trace-driven simulation, but also a new comprehensive real-world AIOps case study that bridges model and practice via a new architecture and main components design within the AIOps system. Extensive experiments show that our DCTA reduces 3.24 times of processing time, and saves 48.4\% energy consumption compared with the state-of-the-art when solving TATIM.
* 15 pages, published in IEEE TRANSACTIONS ON Parallel and Distributed Systems, VOL. 31, NO. 6, JUNE 2020