 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuchao Feng
Context-Aware Integration of Language and Visual References for Natural Language Tracking
Mar 29, 2024
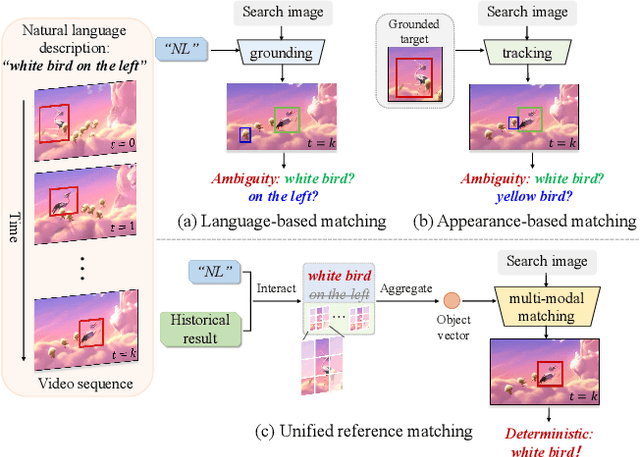

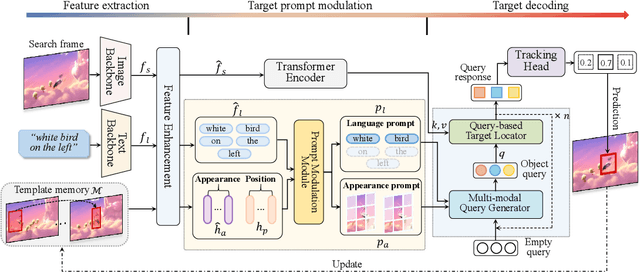
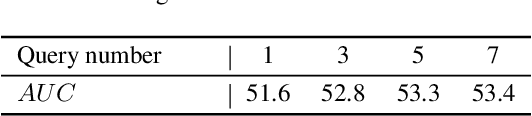
Tracking by natural language specification (TNL) aims to consistently localize a target in a video sequence given a linguistic description in the initial frame. Existing methodologies perform language-based and template-based matching for target reasoning separately and merge the matching results from two sources, which suffer from tracking drift when language and visual templates miss-align with the dynamic target state and ambiguity in the later merging stage. To tackle the issues, we propose a joint multi-modal tracking framework with 1) a prompt modulation module to leverage the complementarity between temporal visual templates and language expressions, enabling precise and context-aware appearance and linguistic cues, and 2) a unified target decoding module to integrate the multi-modal reference cues and executes the integrated queries on the search image to predict the target location in an end-to-end manner directly. This design ensures spatio-temporal consistency by leveraging historical visual information and introduces an integrated solution, generating predictions in a single step. Extensive experiments conducted on TNL2K, OTB-Lang, LaSOT, and RefCOCOg validate the efficacy of our proposed approach. The results demonstrate competitive performance against state-of-the-art methods for both tracking and grounding.
Adaptive-Mask Fusion Network for Segmentation of Drivable Road and Negative Obstacle With Untrustworthy Features
Apr 27, 2023



Segmentation of drivable roads and negative obstacles is critical to the safe driving of autonomous vehicles. Currently, many multi-modal fusion methods have been proposed to improve segmentation accuracy, such as fusing RGB and depth images. However, we find that when fusing two modals of data with untrustworthy features, the performance of multi-modal networks could be degraded, even lower than those using a single modality. In this paper, the untrustworthy features refer to those extracted from regions (e.g., far objects that are beyond the depth measurement range) with invalid depth data (i.e., 0 pixel value) in depth images. The untrustworthy features can confuse the segmentation results, and hence lead to inferior results. To provide a solution to this issue, we propose the Adaptive-Mask Fusion Network (AMFNet) by introducing adaptive-weight masks in the fusion module to fuse features from RGB and depth images with inconsistency. In addition, we release a large-scale RGB-depth dataset with manually-labeled ground truth based on the NPO dataset for drivable roads and negative obstacles segmentation. Extensive experimental results demonstrate that our network achieves state-of-the-art performance compared with other networks. Our code and dataset are available at: https://github.com/lab-sun/AMFNet.
GA-HQS: MRI reconstruction via a generically accelerated unfolding approach
Apr 06, 2023



Deep unfolding networks (DUNs) are the foremost methods in the realm of compressed sensing MRI, as they can employ learnable networks to facilitate interpretable forward-inference operators. However, several daunting issues still exist, including the heavy dependency on the first-order optimization algorithms, the insufficient information fusion mechanisms, and the limitation of capturing long-range relationships. To address the issues, we propose a Generically Accelerated Half-Quadratic Splitting (GA-HQS) algorithm that incorporates second-order gradient information and pyramid attention modules for the delicate fusion of inputs at the pixel level. Moreover, a multi-scale split transformer is also designed to enhance the global feature representation. Comprehensive experiments demonstrate that our method surpasses previous ones on single-coil MRI acceleration tasks.