 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiming Chen
CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Apr 23, 2024
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Apr 19, 2024The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
Autonomous Implicit Indoor Scene Reconstruction with Frontier Exploration
Apr 16, 2024



Implicit neural representations have demonstrated significant promise for 3D scene reconstruction. Recent works have extended their applications to autonomous implicit reconstruction through the Next Best View (NBV) based method. However, the NBV method cannot guarantee complete scene coverage and often necessitates extensive viewpoint sampling, particularly in complex scenes. In the paper, we propose to 1) incorporate frontier-based exploration tasks for global coverage with implicit surface uncertainty-based reconstruction tasks to achieve high-quality reconstruction. and 2) introduce a method to achieve implicit surface uncertainty using color uncertainty, which reduces the time needed for view selection. Further with these two tasks, we propose an adaptive strategy for switching modes in view path planning, to reduce time and maintain superior reconstruction quality. Our method exhibits the highest reconstruction quality among all planning methods and superior planning efficiency in methods involving reconstruction tasks. We deploy our method on a UAV and the results show that our method can plan multi-task views and reconstruct a scene with high quality.
* 7 pages
MESEN: Exploit Multimodal Data to Design Unimodal Human Activity Recognition with Few Labels
Apr 02, 2024Human activity recognition (HAR) will be an essential function of various emerging applications. However, HAR typically encounters challenges related to modality limitations and label scarcity, leading to an application gap between current solutions and real-world requirements. In this work, we propose MESEN, a multimodal-empowered unimodal sensing framework, to utilize unlabeled multimodal data available during the HAR model design phase for unimodal HAR enhancement during the deployment phase. From a study on the impact of supervised multimodal fusion on unimodal feature extraction, MESEN is designed to feature a multi-task mechanism during the multimodal-aided pre-training stage. With the proposed mechanism integrating cross-modal feature contrastive learning and multimodal pseudo-classification aligning, MESEN exploits unlabeled multimodal data to extract effective unimodal features for each modality. Subsequently, MESEN can adapt to downstream unimodal HAR with only a few labeled samples. Extensive experiments on eight public multimodal datasets demonstrate that MESEN achieves significant performance improvements over state-of-the-art baselines in enhancing unimodal HAR by exploiting multimodal data.
Context-Aware Integration of Language and Visual References for Natural Language Tracking
Mar 29, 2024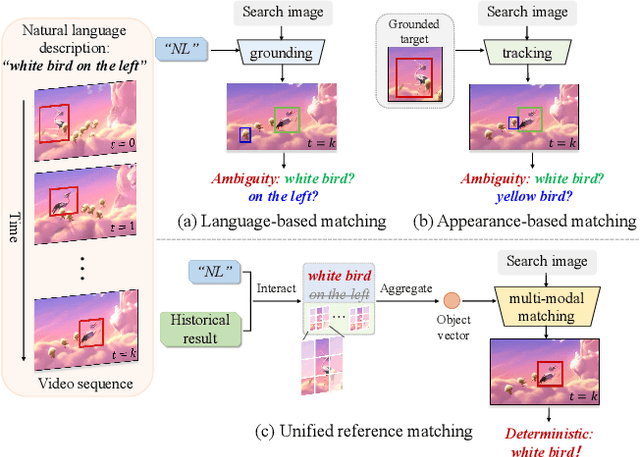

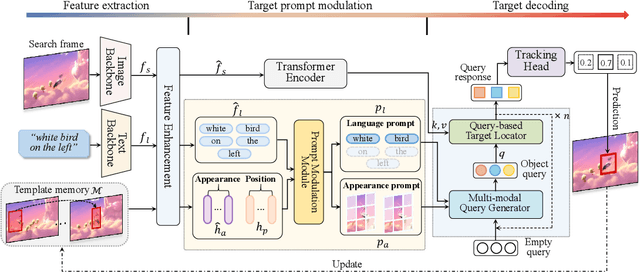
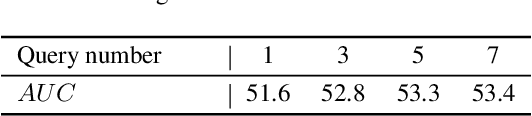
Tracking by natural language specification (TNL) aims to consistently localize a target in a video sequence given a linguistic description in the initial frame. Existing methodologies perform language-based and template-based matching for target reasoning separately and merge the matching results from two sources, which suffer from tracking drift when language and visual templates miss-align with the dynamic target state and ambiguity in the later merging stage. To tackle the issues, we propose a joint multi-modal tracking framework with 1) a prompt modulation module to leverage the complementarity between temporal visual templates and language expressions, enabling precise and context-aware appearance and linguistic cues, and 2) a unified target decoding module to integrate the multi-modal reference cues and executes the integrated queries on the search image to predict the target location in an end-to-end manner directly. This design ensures spatio-temporal consistency by leveraging historical visual information and introduces an integrated solution, generating predictions in a single step. Extensive experiments conducted on TNL2K, OTB-Lang, LaSOT, and RefCOCOg validate the efficacy of our proposed approach. The results demonstrate competitive performance against state-of-the-art methods for both tracking and grounding.
Intention-aware Denoising Diffusion Model for Trajectory Prediction
Mar 14, 2024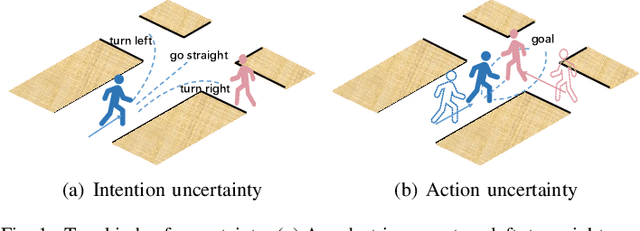

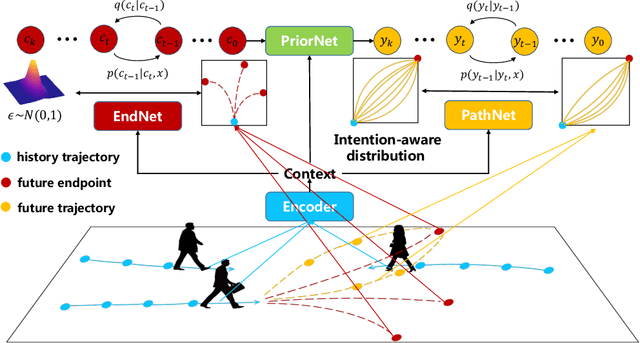

Trajectory prediction is an essential component in autonomous driving, particularly for collision avoidance systems. Considering the inherent uncertainty of the task, numerous studies have utilized generative models to produce multiple plausible future trajectories for each agent. However, most of them suffer from restricted representation ability or unstable training issues. To overcome these limitations, we propose utilizing the diffusion model to generate the distribution of future trajectories. Two cruxes are to be settled to realize such an idea. First, the diversity of intention is intertwined with the uncertain surroundings, making the true distribution hard to parameterize. Second, the diffusion process is time-consuming during the inference phase, rendering it unrealistic to implement in a real-time driving system. We propose an Intention-aware denoising Diffusion Model (IDM), which tackles the above two problems. We decouple the original uncertainty into intention uncertainty and action uncertainty and model them with two dependent diffusion processes. To decrease the inference time, we reduce the variable dimensions in the intention-aware diffusion process and restrict the initial distribution of the action-aware diffusion process, which leads to fewer diffusion steps. To validate our approach, we conduct experiments on the Stanford Drone Dataset (SDD) and ETH/UCY dataset. Our methods achieve state-of-the-art results, with an FDE of 13.83 pixels on the SDD dataset and 0.36 meters on the ETH/UCY dataset. Compared with the original diffusion model, IDM reduces inference time by two-thirds. Interestingly, our experiments further reveal that introducing intention information is beneficial in modeling the diffusion process of fewer steps.
SAM-PD: How Far Can SAM Take Us in Tracking and Segmenting Anything in Videos by Prompt Denoising
Mar 07, 2024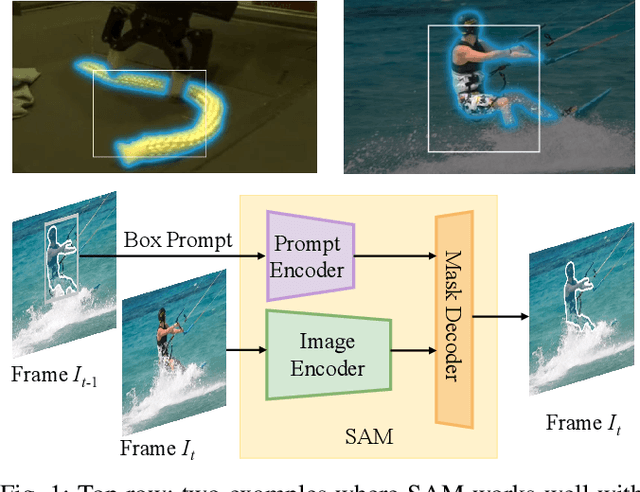
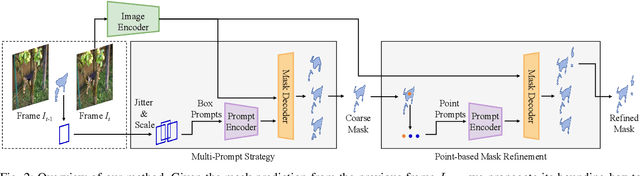
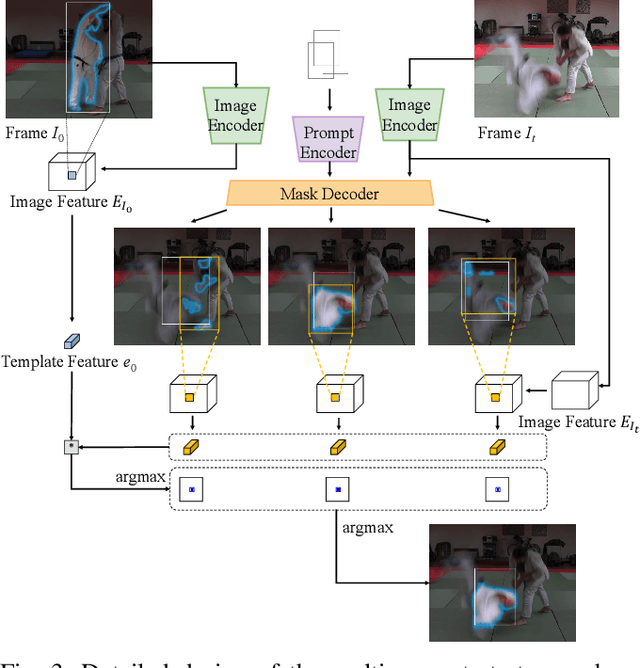

Recently, promptable segmentation models, such as the Segment Anything Model (SAM), have demonstrated robust zero-shot generalization capabilities on static images. These promptable models exhibit denoising abilities for imprecise prompt inputs, such as imprecise bounding boxes. In this paper, we explore the potential of applying SAM to track and segment objects in videos where we recognize the tracking task as a prompt denoising task. Specifically, we iteratively propagate the bounding box of each object's mask in the preceding frame as the prompt for the next frame. Furthermore, to enhance SAM's denoising capability against position and size variations, we propose a multi-prompt strategy where we provide multiple jittered and scaled box prompts for each object and preserve the mask prediction with the highest semantic similarity to the template mask. We also introduce a point-based refinement stage to handle occlusions and reduce cumulative errors. Without involving tracking modules, our approach demonstrates comparable performance in video object/instance segmentation tasks on three datasets: DAVIS2017, YouTubeVOS2018, and UVO, serving as a concise baseline and endowing SAM-based downstream applications with tracking capabilities.
Consistent and Asymptotically Statistically-Efficient Solution to Camera Motion Estimation
Mar 02, 2024
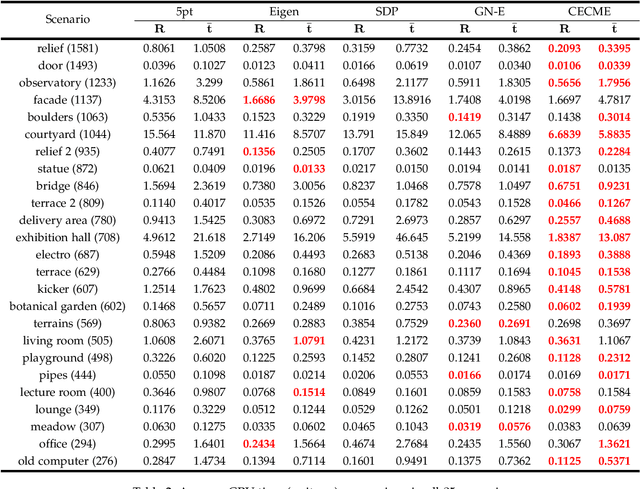
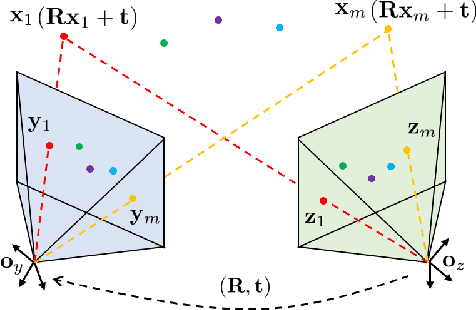
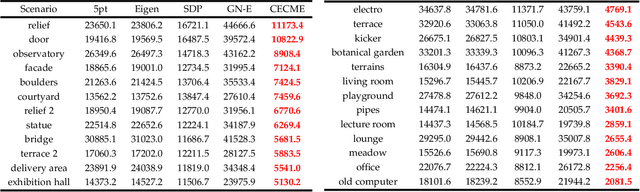
Given 2D point correspondences between an image pair, inferring the camera motion is a fundamental issue in the computer vision community. The existing works generally set out from the epipolar constraint and estimate the essential matrix, which is not optimal in the maximum likelihood (ML) sense. In this paper, we dive into the original measurement model with respect to the rotation matrix and normalized translation vector and formulate the ML problem. We then propose a two-step algorithm to solve it: In the first step, we estimate the variance of measurement noises and devise a consistent estimator based on bias elimination; In the second step, we execute a one-step Gauss-Newton iteration on manifold to refine the consistent estimate. We prove that the proposed estimate owns the same asymptotic statistical properties as the ML estimate: The first is consistency, i.e., the estimate converges to the ground truth as the point number increases; The second is asymptotic efficiency, i.e., the mean squared error of the estimate converges to the theoretical lower bound -- Cramer-Rao bound. In addition, we show that our algorithm has linear time complexity. These appealing characteristics endow our estimator with a great advantage in the case of dense point correspondences. Experiments on both synthetic data and real images demonstrate that when the point number reaches the order of hundreds, our estimator outperforms the state-of-the-art ones in terms of estimation accuracy and CPU time.
Online Time-Optimal Trajectory Generation for Two Quadrotors with Multi-Waypoints Constraints
Feb 28, 2024The autonomous quadrotor's flying speed has kept increasing in the past 5 years, especially in the field of autonomous drone racing. However, the majority of the research mainly focuses on the aggressive flight of a single quadrotor. In this letter, we propose a novel method called Pairwise Model Predictive Control (PMPC) that can guide two quadrotors online to fly through the waypoints with minimum time without collisions. The flight task is first modeled as a nonlinear optimization problem and then an efficient two-step mass point velocity search method is used to provide initial values and references to improve the solving efficiency so that the method can run online with a frequency of 50 Hz and can handle dynamic waypoints. The simulation and real-world experiments validate the feasibility of the proposed method and in the real-world experiments, the two quadrotors can achieve a top speed of 8.1m/s in a 6-waypoint racing track in a compact flying arena of 6m*4m*2m.
Imitation Learning-Based Online Time-Optimal Control with Multiple-Waypoint Constraints for Quadrotors
Feb 18, 2024Over the past decade, there has been a remarkable surge in utilizing quadrotors for various purposes due to their simple structure and aggressive maneuverability, such as search and rescue, delivery and autonomous drone racing, etc. One of the key challenges preventing quadrotors from being widely used in these scenarios is online waypoint-constrained time-optimal trajectory generation and control technique. This letter proposes an imitation learning-based online solution to efficiently navigate the quadrotor through multiple waypoints with time-optimal performance. The neural networks (WN&CNets) are trained to learn the control law from the dataset generated by the time-consuming CPC algorithm and then deployed to generate the optimal control commands online to guide the quadrotors. To address the challenge of limited training data and the hover maneuver at the final waypoint, we propose a transition phase strategy that utilizes polynomials to help the quadrotor 'jump over' the stop-and-go maneuver when switching waypoints. Our method is demonstrated in both simulation and real-world experiments, achieving a maximum speed of 7 m/s while navigating through 7 waypoints in a confined space of 6.0 m * 4.0 m * 2.0 m. The results show that with a slight loss in optimality, the WN&CNets significantly reduce the processing time and enable online optimal control for multiple-waypoint-constrained flight tasks.