 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuchi Huo
CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Apr 23, 2024
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
2L3: Lifting Imperfect Generated 2D Images into Accurate 3D
Jan 29, 2024Reconstructing 3D objects from a single image is an intriguing but challenging problem. One promising solution is to utilize multi-view (MV) 3D reconstruction to fuse generated MV images into consistent 3D objects. However, the generated images usually suffer from inconsistent lighting, misaligned geometry, and sparse views, leading to poor reconstruction quality. To cope with these problems, we present a novel 3D reconstruction framework that leverages intrinsic decomposition guidance, transient-mono prior guidance, and view augmentation to cope with the three issues, respectively. Specifically, we first leverage to decouple the shading information from the generated images to reduce the impact of inconsistent lighting; then, we introduce mono prior with view-dependent transient encoding to enhance the reconstructed normal; and finally, we design a view augmentation fusion strategy that minimizes pixel-level loss in generated sparse views and semantic loss in augmented random views, resulting in view-consistent geometry and detailed textures. Our approach, therefore, enables the integration of a pre-trained MV image generator and a neural network-based volumetric signed distance function (SDF) representation for a single image to 3D object reconstruction. We evaluate our framework on various datasets and demonstrate its superior performance in both quantitative and qualitative assessments, signifying a significant advancement in 3D object reconstruction. Compared with the latest state-of-the-art method Syncdreamer~\cite{liu2023syncdreamer}, we reduce the Chamfer Distance error by about 36\% and improve PSNR by about 30\% .
In-Hand 3D Object Reconstruction from a Monocular RGB Video
Dec 27, 2023Our work aims to reconstruct a 3D object that is held and rotated by a hand in front of a static RGB camera. Previous methods that use implicit neural representations to recover the geometry of a generic hand-held object from multi-view images achieved compelling results in the visible part of the object. However, these methods falter in accurately capturing the shape within the hand-object contact region due to occlusion. In this paper, we propose a novel method that deals with surface reconstruction under occlusion by incorporating priors of 2D occlusion elucidation and physical contact constraints. For the former, we introduce an object amodal completion network to infer the 2D complete mask of objects under occlusion. To ensure the accuracy and view consistency of the predicted 2D amodal masks, we devise a joint optimization method for both amodal mask refinement and 3D reconstruction. For the latter, we impose penetration and attraction constraints on the local geometry in contact regions. We evaluate our approach on HO3D and HOD datasets and demonstrate that it outperforms the state-of-the-art methods in terms of reconstruction surface quality, with an improvement of $52\%$ on HO3D and $20\%$ on HOD. Project webpage: https://east-j.github.io/ihor.
Holistic Inverse Rendering of Complex Facade via Aerial 3D Scanning
Nov 20, 2023In this work, we use multi-view aerial images to reconstruct the geometry, lighting, and material of facades using neural signed distance fields (SDFs). Without the requirement of complex equipment, our method only takes simple RGB images captured by a drone as inputs to enable physically based and photorealistic novel-view rendering, relighting, and editing. However, a real-world facade usually has complex appearances ranging from diffuse rocks with subtle details to large-area glass windows with specular reflections, making it hard to attend to everything. As a result, previous methods can preserve the geometry details but fail to reconstruct smooth glass windows or verse vise. In order to address this challenge, we introduce three spatial- and semantic-adaptive optimization strategies, including a semantic regularization approach based on zero-shot segmentation techniques to improve material consistency, a frequency-aware geometry regularization to balance surface smoothness and details in different surfaces, and a visibility probe-based scheme to enable efficient modeling of the local lighting in large-scale outdoor environments. In addition, we capture a real-world facade aerial 3D scanning image set and corresponding point clouds for training and benchmarking. The experiment demonstrates the superior quality of our method on facade holistic inverse rendering, novel view synthesis, and scene editing compared to state-of-the-art baselines.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Oct 15, 2023The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in $4 \times 4$ and even challenging $8 \times 8$ upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.
Topological RANSAC for instance verification and retrieval without fine-tuning
Oct 10, 2023



This paper presents an innovative approach to enhancing explainable image retrieval, particularly in situations where a fine-tuning set is unavailable. The widely-used SPatial verification (SP) method, despite its efficacy, relies on a spatial model and the hypothesis-testing strategy for instance recognition, leading to inherent limitations, including the assumption of planar structures and neglect of topological relations among features. To address these shortcomings, we introduce a pioneering technique that replaces the spatial model with a topological one within the RANSAC process. We propose bio-inspired saccade and fovea functions to verify the topological consistency among features, effectively circumventing the issues associated with SP's spatial model. Our experimental results demonstrate that our method significantly outperforms SP, achieving state-of-the-art performance in non-fine-tuning retrieval. Furthermore, our approach can enhance performance when used in conjunction with fine-tuned features. Importantly, our method retains high explainability and is lightweight, offering a practical and adaptable solution for a variety of real-world applications.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023



This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.
Seal-3D: Interactive Pixel-Level Editing for Neural Radiance Fields
Jul 27, 2023
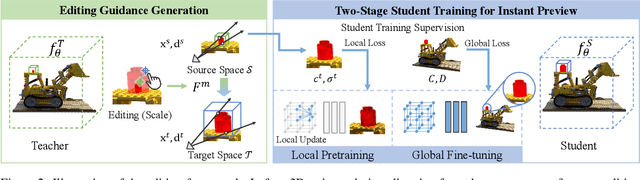
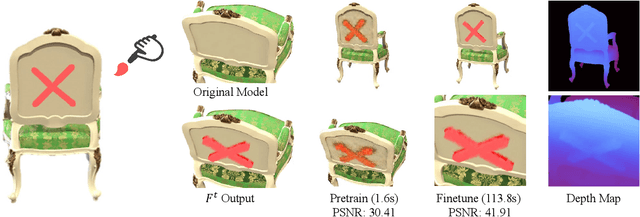
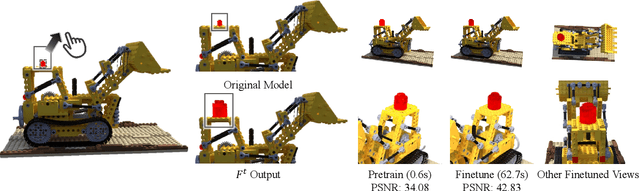
With the popularity of implicit neural representations, or neural radiance fields (NeRF), there is a pressing need for editing methods to interact with the implicit 3D models for tasks like post-processing reconstructed scenes and 3D content creation. While previous works have explored NeRF editing from various perspectives, they are restricted in editing flexibility, quality, and speed, failing to offer direct editing response and instant preview. The key challenge is to conceive a locally editable neural representation that can directly reflect the editing instructions and update instantly. To bridge the gap, we propose a new interactive editing method and system for implicit representations, called Seal-3D, which allows users to edit NeRF models in a pixel-level and free manner with a wide range of NeRF-like backbone and preview the editing effects instantly. To achieve the effects, the challenges are addressed by our proposed proxy function mapping the editing instructions to the original space of NeRF models and a teacher-student training strategy with local pretraining and global finetuning. A NeRF editing system is built to showcase various editing types. Our system can achieve compelling editing effects with an interactive speed of about 1 second.
I$^2$-SDF: Intrinsic Indoor Scene Reconstruction and Editing via Raytracing in Neural SDFs
Mar 29, 2023
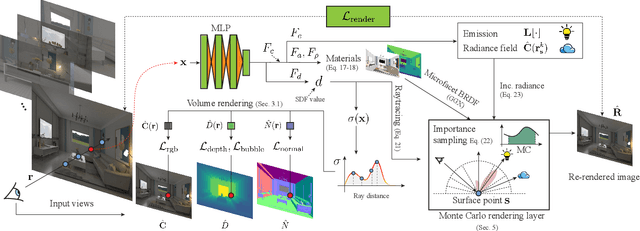
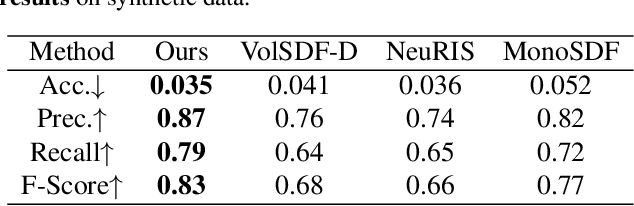
In this work, we present I$^2$-SDF, a new method for intrinsic indoor scene reconstruction and editing using differentiable Monte Carlo raytracing on neural signed distance fields (SDFs). Our holistic neural SDF-based framework jointly recovers the underlying shapes, incident radiance and materials from multi-view images. We introduce a novel bubble loss for fine-grained small objects and error-guided adaptive sampling scheme to largely improve the reconstruction quality on large-scale indoor scenes. Further, we propose to decompose the neural radiance field into spatially-varying material of the scene as a neural field through surface-based, differentiable Monte Carlo raytracing and emitter semantic segmentations, which enables physically based and photorealistic scene relighting and editing applications. Through a number of qualitative and quantitative experiments, we demonstrate the superior quality of our method on indoor scene reconstruction, novel view synthesis, and scene editing compared to state-of-the-art baselines.
Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022



Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.