 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuexi Du
SIFT-DBT: Self-supervised Initialization and Fine-Tuning for Imbalanced Digital Breast Tomosynthesis Image Classification
Mar 19, 2024
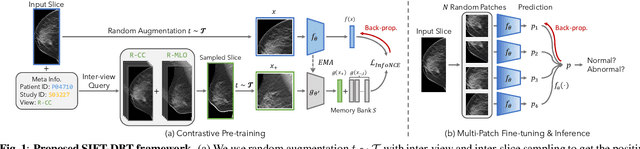
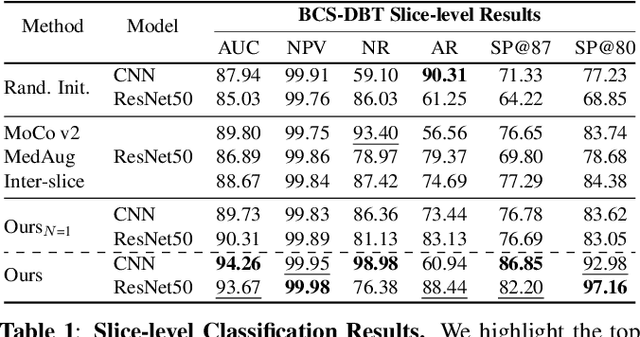
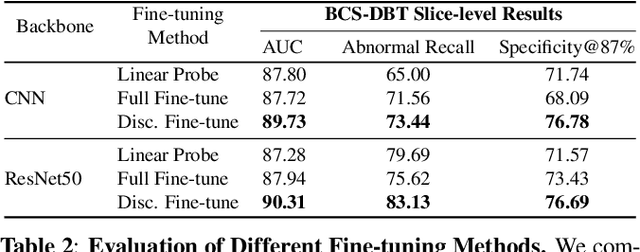
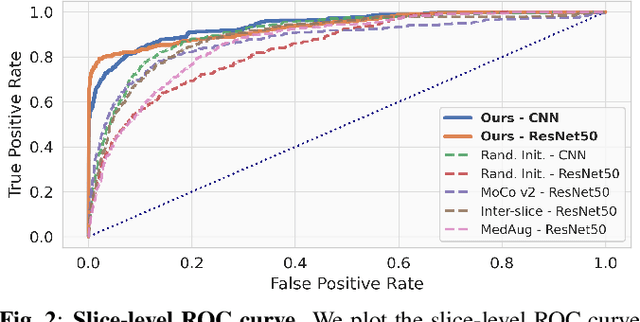
Digital Breast Tomosynthesis (DBT) is a widely used medical imaging modality for breast cancer screening and diagnosis, offering higher spatial resolution and greater detail through its 3D-like breast volume imaging capability. However, the increased data volume also introduces pronounced data imbalance challenges, where only a small fraction of the volume contains suspicious tissue. This further exacerbates the data imbalance due to the case-level distribution in real-world data and leads to learning a trivial classification model that only predicts the majority class. To address this, we propose a novel method using view-level contrastive Self-supervised Initialization and Fine-Tuning for identifying abnormal DBT images, namely SIFT-DBT. We further introduce a patch-level multi-instance learning method to preserve spatial resolution. The proposed method achieves 92.69% volume-wise AUC on an evaluation of 970 unique studies.
Conditional Generation of Audio from Video via Foley Analogies
Apr 17, 2023

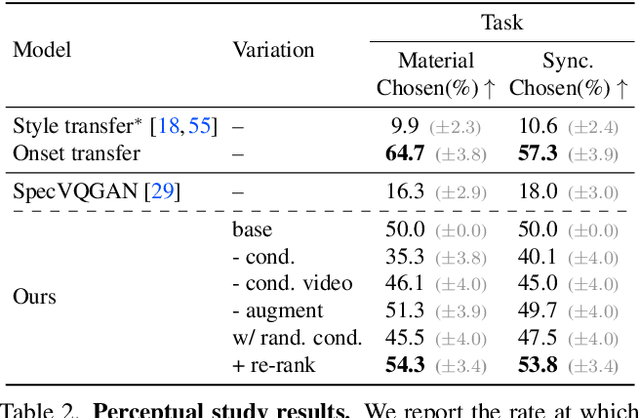
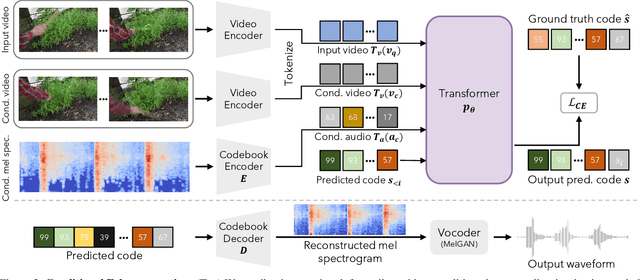
The sound effects that designers add to videos are designed to convey a particular artistic effect and, thus, may be quite different from a scene's true sound. Inspired by the challenges of creating a soundtrack for a video that differs from its true sound, but that nonetheless matches the actions occurring on screen, we propose the problem of conditional Foley. We present the following contributions to address this problem. First, we propose a pretext task for training our model to predict sound for an input video clip using a conditional audio-visual clip sampled from another time within the same source video. Second, we propose a model for generating a soundtrack for a silent input video, given a user-supplied example that specifies what the video should "sound like". We show through human studies and automated evaluation metrics that our model successfully generates sound from video, while varying its output according to the content of a supplied example. Project site: https://xypb.github.io/CondFoleyGen/