 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhan Wu
Temporal Convolutional Explorer Helps Understand 1D-CNN's Learning Behavior in Time Series Classification from Frequency Domain
Oct 09, 2023
While one-dimensional convolutional neural networks (1D-CNNs) have been empirically proven effective in time series classification tasks, we find that there remain undesirable outcomes that could arise in their application, motivating us to further investigate and understand their underlying mechanisms. In this work, we propose a Temporal Convolutional Explorer (TCE) to empirically explore the learning behavior of 1D-CNNs from the perspective of the frequency domain. Our TCE analysis highlights that deeper 1D-CNNs tend to distract the focus from the low-frequency components leading to the accuracy degradation phenomenon, and the disturbing convolution is the driving factor. Then, we leverage our findings to the practical application and propose a regulatory framework, which can easily be integrated into existing 1D-CNNs. It aims to rectify the suboptimal learning behavior by enabling the network to selectively bypass the specified disturbing convolutions. Finally, through comprehensive experiments on widely-used UCR, UEA, and UCI benchmarks, we demonstrate that 1) TCE's insight into 1D-CNN's learning behavior; 2) our regulatory framework enables state-of-the-art 1D-CNNs to get improved performances with less consumption of memory and computational overhead.
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
Oct 01, 2023
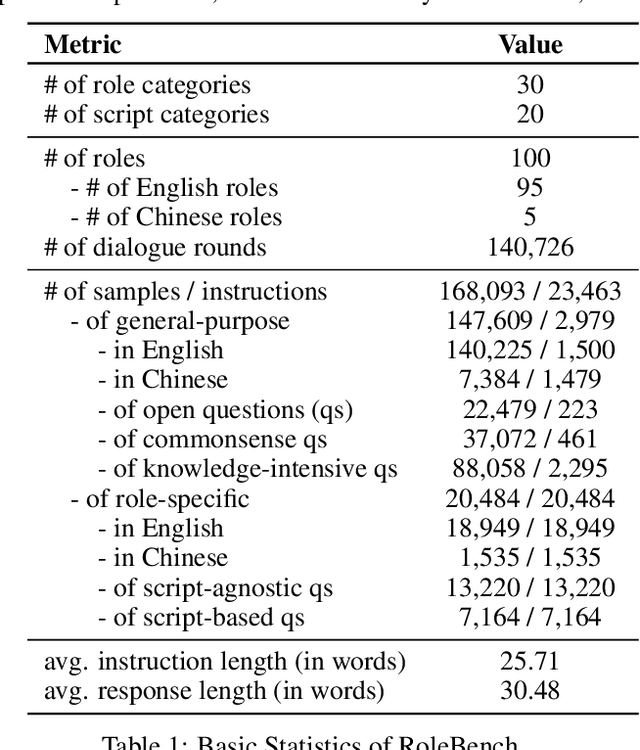
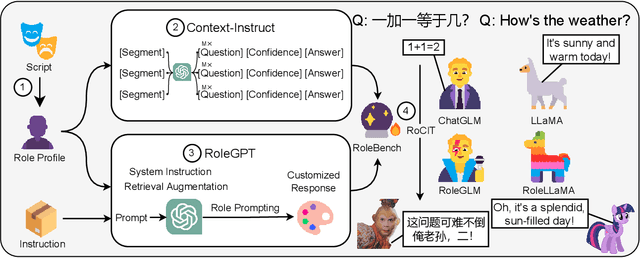
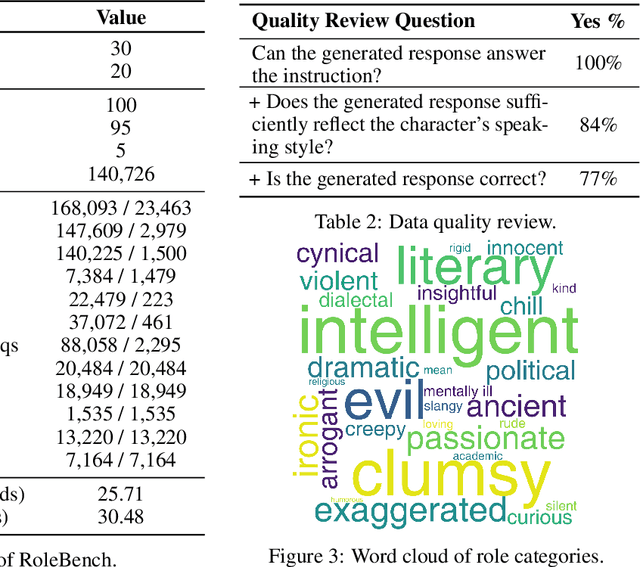
The advent of Large Language Models (LLMs) has paved the way for complex tasks such as role-playing, which enhances user interactions by enabling models to imitate various characters. However, the closed-source nature of state-of-the-art LLMs and their general-purpose training limit role-playing optimization. In this paper, we introduce RoleLLM, a framework to benchmark, elicit, and enhance role-playing abilities in LLMs. RoleLLM comprises four stages: (1) Role Profile Construction for 100 roles; (2) Context-Based Instruction Generation (Context-Instruct) for role-specific knowledge extraction; (3) Role Prompting using GPT (RoleGPT) for speaking style imitation; and (4) Role-Conditioned Instruction Tuning (RoCIT) for fine-tuning open-source models along with role customization. By Context-Instruct and RoleGPT, we create RoleBench, the first systematic and fine-grained character-level benchmark dataset for role-playing with 168,093 samples. Moreover, RoCIT on RoleBench yields RoleLLaMA (English) and RoleGLM (Chinese), significantly enhancing role-playing abilities and even achieving comparable results with RoleGPT (using GPT-4).
Query2GMM: Learning Representation with Gaussian Mixture Model for Reasoning over Knowledge Graphs
Jun 17, 2023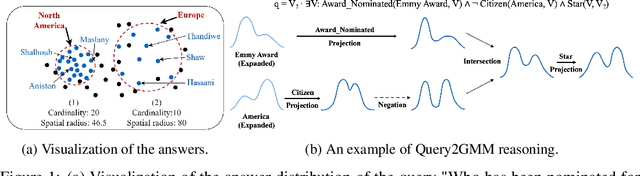
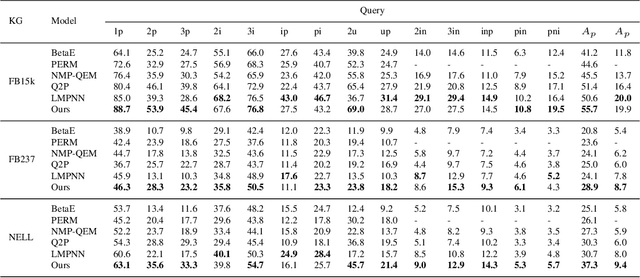

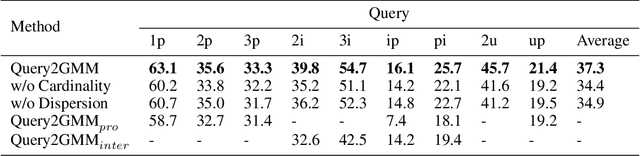
Logical query answering over Knowledge Graphs (KGs) is a fundamental yet complex task. A promising approach to achieve this is to embed queries and entities jointly into the same embedding space. Research along this line suggests that using multi-modal distribution to represent answer entities is more suitable than uni-modal distribution, as a single query may contain multiple disjoint answer subsets due to the compositional nature of multi-hop queries and the varying latent semantics of relations. However, existing methods based on multi-modal distribution roughly represent each subset without capturing its accurate cardinality, or even degenerate into uni-modal distribution learning during the reasoning process due to the lack of an effective similarity measure. To better model queries with diversified answers, we propose Query2GMM for answering logical queries over knowledge graphs. In Query2GMM, we present the GMM embedding to represent each query using a univariate Gaussian Mixture Model (GMM). Each subset of a query is encoded by its cardinality, semantic center and dispersion degree, allowing for precise representation of multiple subsets. Then we design specific neural networks for each operator to handle the inherent complexity that comes with multi-modal distribution while alleviating the cascading errors. Last, we define a new similarity measure to assess the relationships between an entity and a query's multi-answer subsets, enabling effective multi-modal distribution learning for reasoning. Comprehensive experimental results show that Query2GMM outperforms the best competitor by an absolute average of $5.5\%$. The source code is available at \url{https://anonymous.4open.science/r/Query2GMM-C42F}.
DiaASQ : A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis
Nov 20, 2022
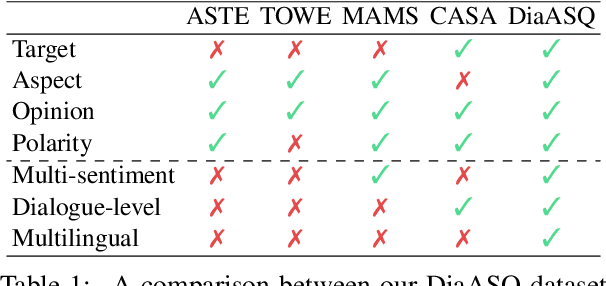
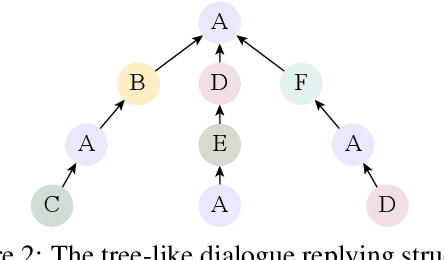
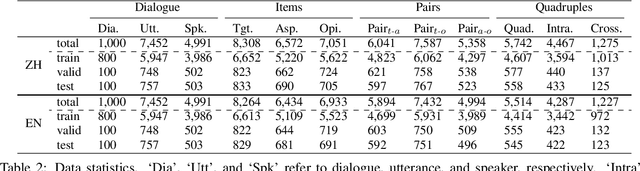
The rapid development of aspect-based sentiment analysis (ABSA) within recent decades shows great potential for real-world society. The current ABSA works, however, are mostly limited to the scenario of a single text piece, leaving the study in dialogue contexts unexplored. In this work, we introduce a novel task of conversational aspect-based sentiment quadruple analysis, namely DiaASQ, aiming to detect the sentiment quadruple of \emph{target-aspect-opinion-sentiment} in a dialogue. DiaASQ bridges the gap between fine-grained sentiment analysis and conversational opinion mining. We manually construct a large-scale high-quality DiaASQ dataset in both Chinese and English languages. We deliberately develop a neural model to benchmark the task, which advances in effectively performing end-to-end quadruple prediction, and manages to incorporate rich dialogue-specific and discourse feature representations for better cross-utterance quadruple extraction. We finally point out several potential future works to facilitate the follow-up research of this new task.