 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Jiang
End-to-End $n$-ary Relation Extraction for Combination Drug Therapies
Mar 29, 2023
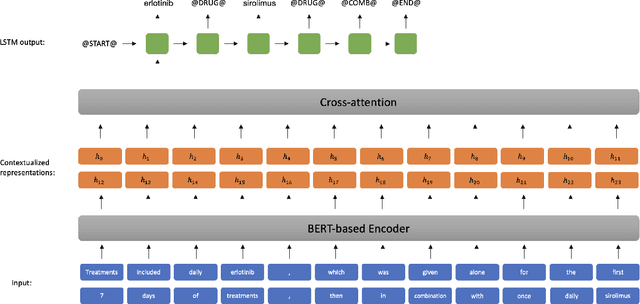


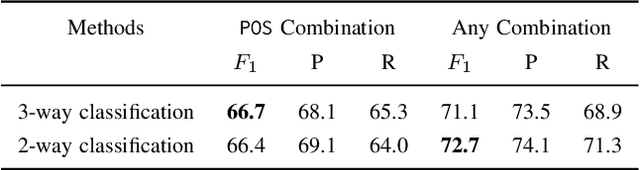
Combination drug therapies are treatment regimens that involve two or more drugs, administered more commonly for patients with cancer, HIV, malaria, or tuberculosis. Currently there are over 350K articles in PubMed that use the "combination drug therapy" MeSH heading with at least 10K articles published per year over the past two decades. Extracting combination therapies from scientific literature inherently constitutes an $n$-ary relation extraction problem. Unlike in the general $n$-ary setting where $n$ is fixed (e.g., drug-gene-mutation relations where $n=3$), extracting combination therapies is a special setting where $n \geq 2$ is dynamic, depending on each instance. Recently, Tiktinsky et al. (NAACL 2022) introduced a first of its kind dataset, CombDrugExt, for extracting such therapies from literature. Here, we use a sequence-to-sequence style end-to-end extraction method to achieve an F1-Score of $66.7\%$ on the CombDrugExt test set for positive (or effective) combinations. This is an absolute $\approx 5\%$ F1-score improvement even over the prior best relation classification score with spotted drug entities (hence, not end-to-end). Thus our effort introduces a state-of-the-art first model for end-to-end extraction that is already superior to the best prior non end-to-end model for this task. Our model seamlessly extracts all drug entities and relations in a single pass and is highly suitable for dynamic $n$-ary extraction scenarios.
COVID-19 event extraction from Twitter via extractive question answering with continuous prompts
Mar 22, 2023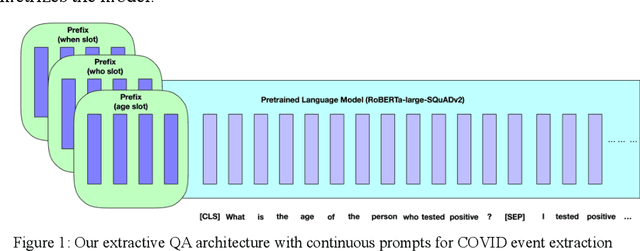
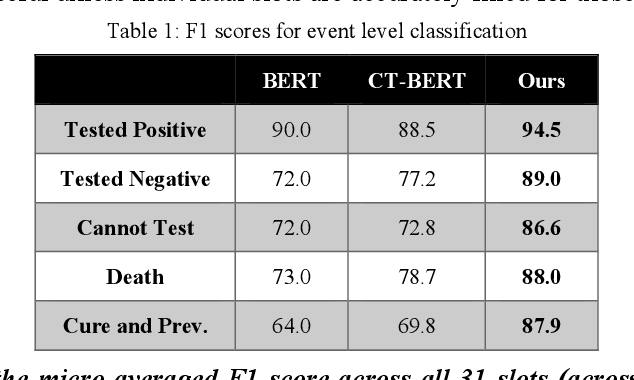
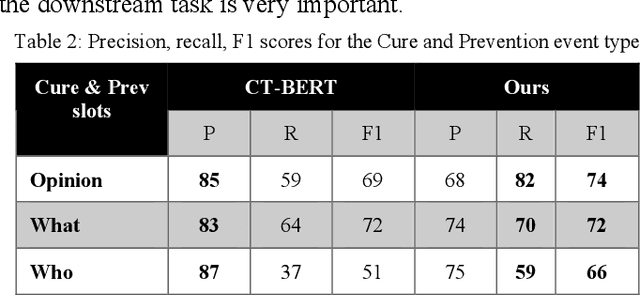
As COVID-19 ravages the world, social media analytics could augment traditional surveys in assessing how the pandemic evolves and capturing consumer chatter that could help healthcare agencies in addressing it. This typically involves mining disclosure events that mention testing positive for the disease or discussions surrounding perceptions and beliefs in preventative or treatment options. The 2020 shared task on COVID-19 event extraction (conducted as part of the W-NUT workshop during the EMNLP conference) introduced a new Twitter dataset for benchmarking event extraction from COVID-19 tweets. In this paper, we cast the problem of event extraction as extractive question answering using recent advances in continuous prompting in language models. On the shared task test dataset, our approach leads to over 5% absolute micro-averaged F1-score improvement over prior best results, across all COVID-19 event slots. Our ablation study shows that continuous prompts have a major impact on the eventual performance.
Near-Optimal Regret Bounds for Multi-batch Reinforcement Learning
Oct 15, 2022
In this paper, we study the episodic reinforcement learning (RL) problem modeled by finite-horizon Markov Decision Processes (MDPs) with constraint on the number of batches. The multi-batch reinforcement learning framework, where the agent is required to provide a time schedule to update policy before everything, which is particularly suitable for the scenarios where the agent suffers extensively from changing the policy adaptively. Given a finite-horizon MDP with $S$ states, $A$ actions and planning horizon $H$, we design a computational efficient algorithm to achieve near-optimal regret of $\tilde{O}(\sqrt{SAH^3K\ln(1/\delta)})$\footnote{$\tilde{O}(\cdot)$ hides logarithmic terms of $(S,A,H,K)$} in $K$ episodes using $O\left(H+\log_2\log_2(K) \right)$ batches with confidence parameter $\delta$. To our best of knowledge, it is the first $\tilde{O}(\sqrt{SAH^3K})$ regret bound with $O(H+\log_2\log_2(K))$ batch complexity. Meanwhile, we show that to achieve $\tilde{O}(\mathrm{poly}(S,A,H)\sqrt{K})$ regret, the number of batches is at least $\Omega\left(H/\log_A(K)+ \log_2\log_2(K) \right)$, which matches our upper bound up to logarithmic terms. Our technical contribution are two-fold: 1) a near-optimal design scheme to explore over the unlearned states; 2) an computational efficient algorithm to explore certain directions with an approximated transition model.
Improved lightweight identification of agricultural diseases based on MobileNetV3
Jul 19, 2022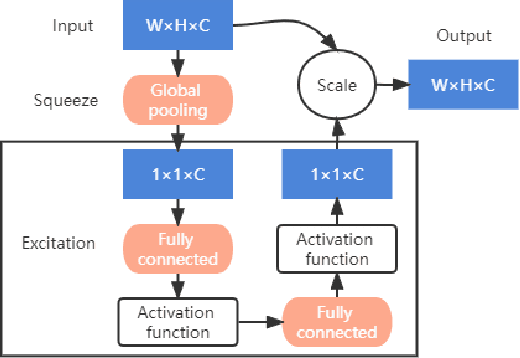
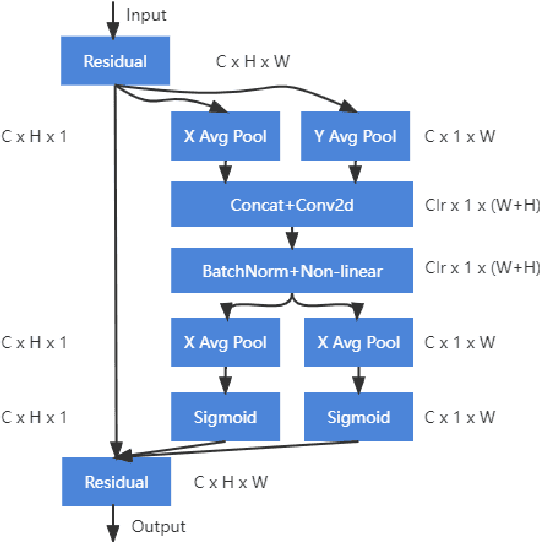
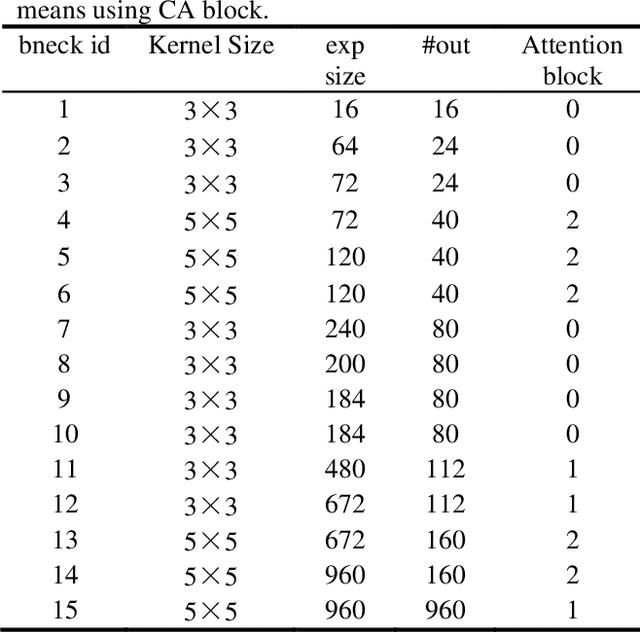

At present, the identification of agricultural pests and diseases has the problem that the model is not lightweight enough and difficult to apply. Based on MobileNetV3, this paper introduces the Coordinate Attention block. The parameters of MobileNetV3-large are reduced by 22%, the model size is reduced by 19.7%, and the accuracy is improved by 0.92%. The parameters of MobileNetV3-small are reduced by 23.4%, the model size is reduced by 18.3%, and the accuracy is increased by 0.40%. In addition, the improved MobileNetV3-small was migrated to Jetson Nano for testing. The accuracy increased by 2.48% to 98.31%, and the inference speed increased by 7.5%. It provides a reference for deploying the agricultural pest identification model to embedded devices.
Wasserstein Unsupervised Reinforcement Learning
Oct 15, 2021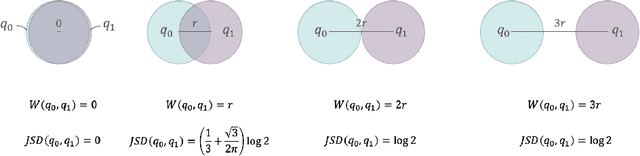
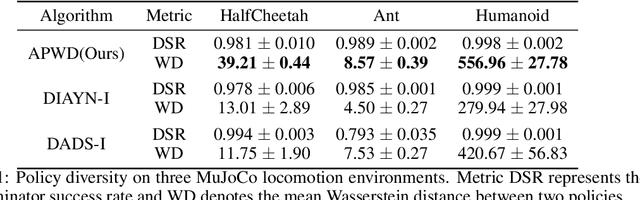
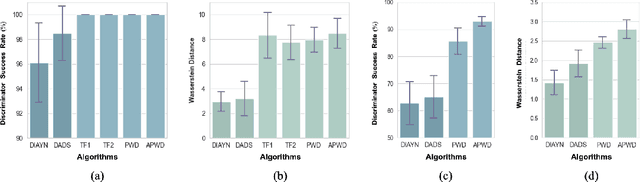

Unsupervised reinforcement learning aims to train agents to learn a handful of policies or skills in environments without external reward. These pre-trained policies can accelerate learning when endowed with external reward, and can also be used as primitive options in hierarchical reinforcement learning. Conventional approaches of unsupervised skill discovery feed a latent variable to the agent and shed its empowerment on agent's behavior by mutual information (MI) maximization. However, the policies learned by MI-based methods cannot sufficiently explore the state space, despite they can be successfully identified from each other. Therefore we propose a new framework Wasserstein unsupervised reinforcement learning (WURL) where we directly maximize the distance of state distributions induced by different policies. Additionally, we overcome difficulties in simultaneously training N(N >2) policies, and amortizing the overall reward to each step. Experiments show policies learned by our approach outperform MI-based methods on the metric of Wasserstein distance while keeping high discriminability. Furthermore, the agents trained by WURL can sufficiently explore the state space in mazes and MuJoCo tasks and the pre-trained policies can be applied to downstream tasks by hierarchical learning.
Reducing Conservativeness Oriented Offline Reinforcement Learning
Feb 27, 2021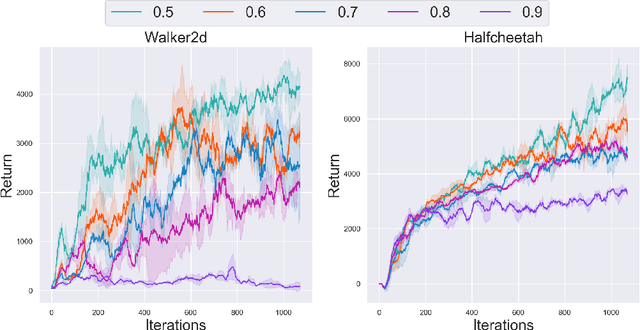
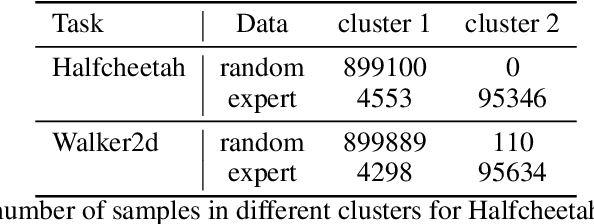
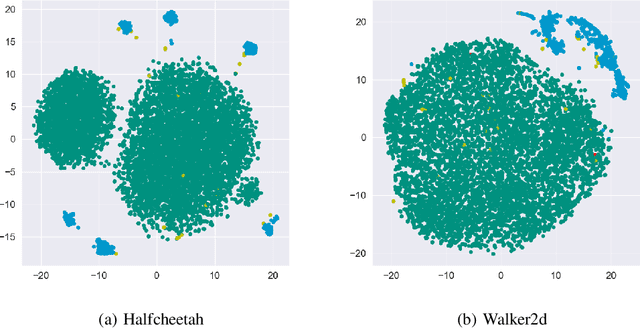
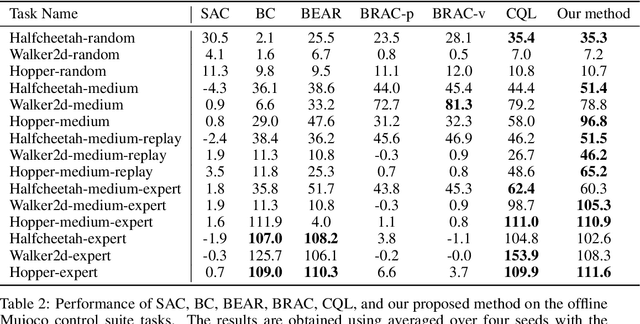
In offline reinforcement learning, a policy learns to maximize cumulative rewards with a fixed collection of data. Towards conservative strategy, current methods choose to regularize the behavior policy or learn a lower bound of the value function. However, exorbitant conservation tends to impair the policy's generalization ability and degrade its performance, especially for the mixed datasets. In this paper, we propose the method of reducing conservativeness oriented reinforcement learning. On the one hand, the policy is trained to pay more attention to the minority samples in the static dataset to address the data imbalance problem. On the other hand, we give a tighter lower bound of value function than previous methods to discover potential optimal actions. Consequently, our proposed method is able to tackle the skewed distribution of the provided dataset and derive a value function closer to the expected value function. Experimental results demonstrate that our proposed method outperforms the state-of-the-art methods in D4RL offline reinforcement learning evaluation tasks and our own designed mixed datasets.
Credit Assignment with Meta-Policy Gradient for Multi-Agent Reinforcement Learning
Feb 24, 2021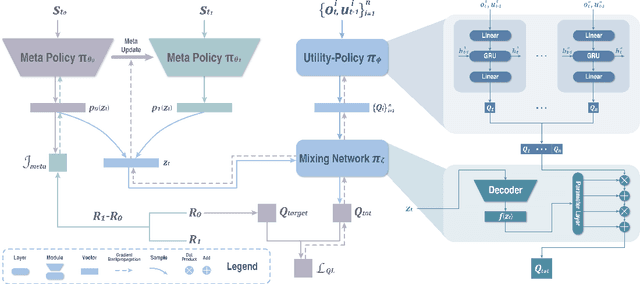
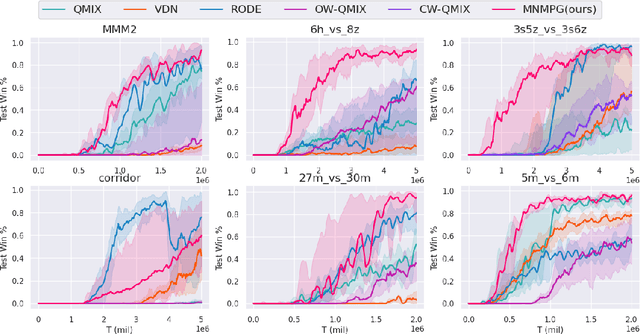

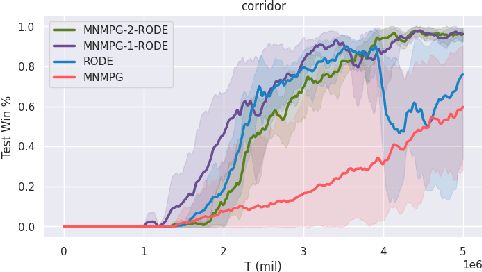
Reward decomposition is a critical problem in centralized training with decentralized execution~(CTDE) paradigm for multi-agent reinforcement learning. To take full advantage of global information, which exploits the states from all agents and the related environment for decomposing Q values into individual credits, we propose a general meta-learning-based Mixing Network with Meta Policy Gradient~(MNMPG) framework to distill the global hierarchy for delicate reward decomposition. The excitation signal for learning global hierarchy is deduced from the episode reward difference between before and after "exercise updates" through the utility network. Our method is generally applicable to the CTDE method using a monotonic mixing network. Experiments on the StarCraft II micromanagement benchmark demonstrate that our method just with a simple utility network is able to outperform the current state-of-the-art MARL algorithms on 4 of 5 super hard scenarios. Better performance can be further achieved when combined with a role-based utility network.
PFRL: Pose-Free Reinforcement Learning for 6D Pose Estimation
Feb 24, 2021
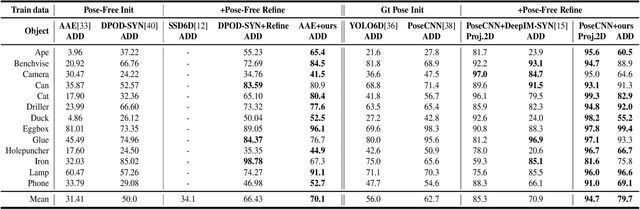
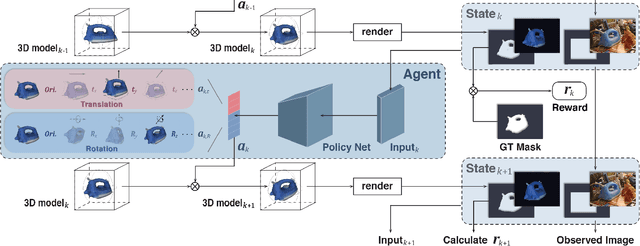
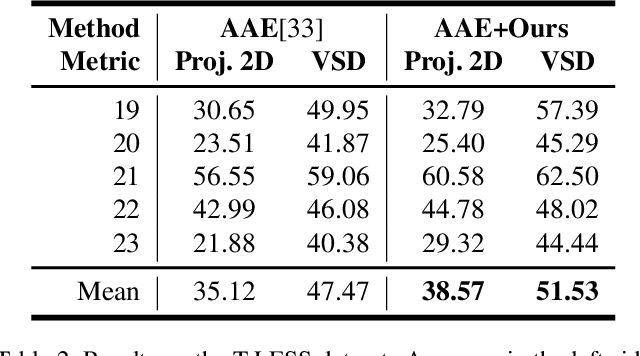
6D pose estimation from a single RGB image is a challenging and vital task in computer vision. The current mainstream deep model methods resort to 2D images annotated with real-world ground-truth 6D object poses, whose collection is fairly cumbersome and expensive, even unavailable in many cases. In this work, to get rid of the burden of 6D annotations, we formulate the 6D pose refinement as a Markov Decision Process and impose on the reinforcement learning approach with only 2D image annotations as weakly-supervised 6D pose information, via a delicate reward definition and a composite reinforced optimization method for efficient and effective policy training. Experiments on LINEMOD and T-LESS datasets demonstrate that our Pose-Free approach is able to achieve state-of-the-art performance compared with the methods without using real-world ground-truth 6D pose labels.
Deep learning for video game genre classification
Nov 21, 2020

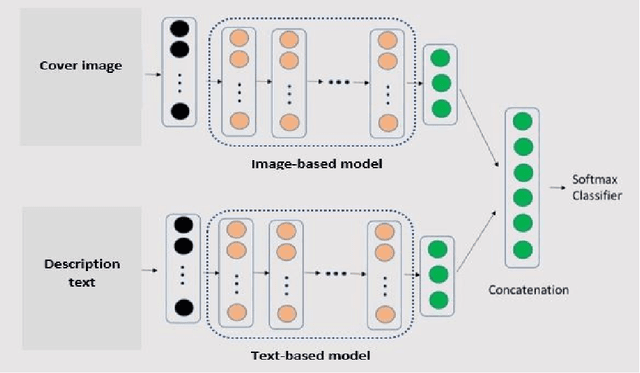
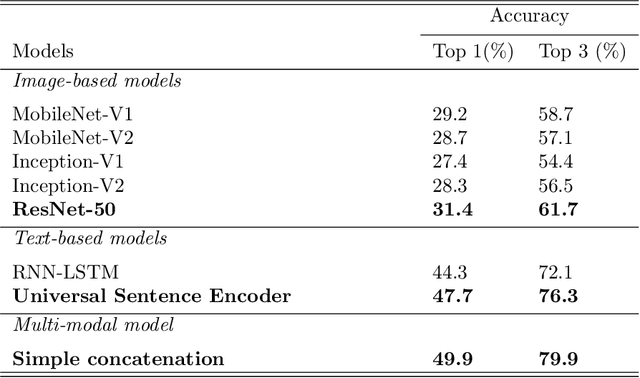
Video game genre classification based on its cover and textual description would be utterly beneficial to many modern identification, collocation, and retrieval systems. At the same time, it is also an extremely challenging task due to the following reasons: First, there exists a wide variety of video game genres, many of which are not concretely defined. Second, video game covers vary in many different ways such as colors, styles, textual information, etc, even for games of the same genre. Third, cover designs and textual descriptions may vary due to many external factors such as country, culture, target reader populations, etc. With the growing competitiveness in the video game industry, the cover designers and typographers push the cover designs to its limit in the hope of attracting sales. The computer-based automatic video game genre classification systems become a particularly exciting research topic in recent years. In this paper, we propose a multi-modal deep learning framework to solve this problem. The contribution of this paper is four-fold. First, we compiles a large dataset consisting of 50,000 video games from 21 genres made of cover images, description text, and title text and the genre information. Second, image-based and text-based, state-of-the-art models are evaluated thoroughly for the task of genre classification for video games. Third, we developed an efficient and salable multi-modal framework based on both images and texts. Fourth, a thorough analysis of the experimental results is given and future works to improve the performance is suggested. The results show that the multi-modal framework outperforms the current state-of-the-art image-based or text-based models. Several challenges are outlined for this task. More efforts and resources are needed for this classification task in order to reach a satisfactory level.
Hardware-aware One-Shot Neural Architecture Search in Coordinate Ascent Framework
Oct 25, 2019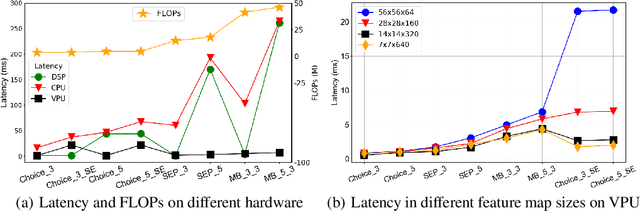
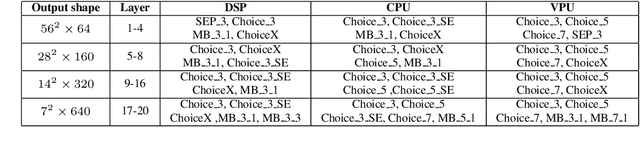
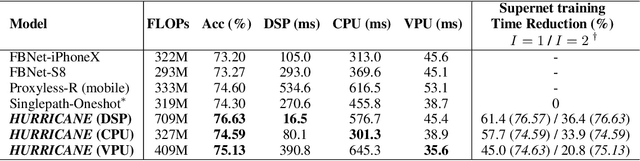
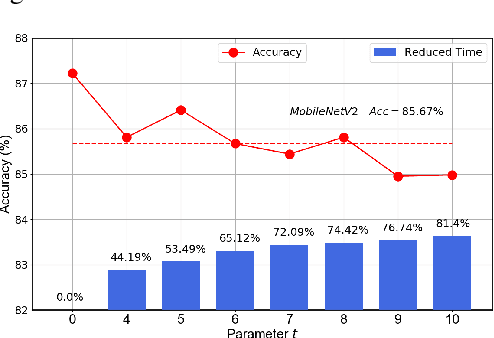
Designing accurate and efficient convolutional neural architectures for vast amount of hardware is challenging because hardware designs are complex and diverse. This paper addresses the hardware diversity challenge in Neural Architecture Search (NAS). Unlike previous approaches that apply search algorithms on a small, human-designed search space without considering hardware diversity, we propose HURRICANE that explores the automatic hardware-aware search over a much larger search space and a multistep search scheme in coordinate ascent framework, to generate tailored models for different types of hardware. Extensive experiments on ImageNet show that our algorithm consistently achieves a much lower inference latency with a similar or better accuracy than state-of-the-art NAS methods on three types of hardware. Remarkably, HURRICANE achieves a 76.63% top-1 accuracy on ImageNet with a inference latency of only 16.5 ms for DSP, which is a 3.4% higher accuracy and a 6.35x inference speedup than FBNet-iPhoneX. For VPU, HURRICANE achieves a 0.53% higher top-1 accuracy than Proxyless-mobile with a 1.49x speedup. Even for well-studied mobile CPU, HURRICANE achieves a 1.63% higher top-1 accuracy than FBNet-iPhoneX with a comparable inference latency. HURRICANE also reduces the training time by 54.7% on average compared to SinglePath-Oneshot.