 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYulai Cong
Big Learning Expectation Maximization
Dec 19, 2023
Mixture models serve as one fundamental tool with versatile applications. However, their training techniques, like the popular Expectation Maximization (EM) algorithm, are notoriously sensitive to parameter initialization and often suffer from bad local optima that could be arbitrarily worse than the optimal. To address the long-lasting bad-local-optima challenge, we draw inspiration from the recent ground-breaking foundation models and propose to leverage their underlying big learning principle to upgrade the EM. Specifically, we present the Big Learning EM (BigLearn-EM), an EM upgrade that simultaneously performs joint, marginal, and orthogonally transformed marginal matchings between data and model distributions. Through simulated experiments, we empirically show that the BigLearn-EM is capable of delivering the optimal with high probability; comparisons on benchmark clustering datasets further demonstrate its effectiveness and advantages over existing techniques. The code is available at https://github.com/YulaiCong/Big-Learning-Expectation-Maximization.
Big Learning: A Universal Machine Learning Paradigm?
Jul 08, 2022



Recent breakthroughs based on big/foundation models reveal a vague avenue for artificial intelligence, that is, bid data, big/foundation models, big learning, $\cdots$. Following that avenue, here we elaborate on the newly introduced big learning. Specifically, big learning comprehensively exploits the available information inherent in large-scale complete/incomplete data, by simultaneously learning to model many-to-all joint/conditional/marginal data distributions (thus named big learning) with one universal foundation model. We reveal that big learning is what existing foundation models are implicitly doing; accordingly, our big learning provides high-level guidance for flexible design and improvements of foundation models, accelerating the true self-learning on the Internet. Besides, big learning ($i$) is equipped with marvelous flexibility for both training data and training-task customization; ($ii$) potentially delivers all joint/conditional/marginal data capabilities after training; ($iii$) significantly reduces the training-test gap with improved model generalization; and ($iv$) unifies conventional machine learning paradigms e.g. supervised learning, unsupervised learning, generative learning, etc. and enables their flexible cooperation, manifesting a universal learning paradigm.
Bridging Maximum Likelihood and Adversarial Learning via $α$-Divergence
Jul 13, 2020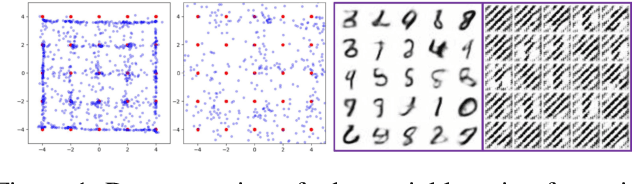


Maximum likelihood (ML) and adversarial learning are two popular approaches for training generative models, and from many perspectives these techniques are complementary. ML learning encourages the capture of all data modes, and it is typically characterized by stable training. However, ML learning tends to distribute probability mass diffusely over the data space, $e.g.$, yielding blurry synthetic images. Adversarial learning is well known to synthesize highly realistic natural images, despite practical challenges like mode dropping and delicate training. We propose an $\alpha$-Bridge to unify the advantages of ML and adversarial learning, enabling the smooth transfer from one to the other via the $\alpha$-divergence. We reveal that generalizations of the $\alpha$-Bridge are closely related to approaches developed recently to regularize adversarial learning, providing insights into that prior work, and further understanding of why the $\alpha$-Bridge performs well in practice.
GO Hessian for Expectation-Based Objectives
Jun 16, 2020



An unbiased low-variance gradient estimator, termed GO gradient, was proposed recently for expectation-based objectives $\mathbb{E}_{q_{\boldsymbol{\gamma}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, where the random variable (RV) $\boldsymbol{y}$ may be drawn from a stochastic computation graph with continuous (non-reparameterizable) internal nodes and continuous/discrete leaves. Upgrading the GO gradient, we present for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$ an unbiased low-variance Hessian estimator, named GO Hessian. Considering practical implementation, we reveal that GO Hessian is easy-to-use with auto-differentiation and Hessian-vector products, enabling efficient cheap exploitation of curvature information over stochastic computation graphs. As representative examples, we present the GO Hessian for non-reparameterizable gamma and negative binomial RVs/nodes. Based on the GO Hessian, we design a new second-order method for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, with rigorous experiments conducted to verify its effectiveness and efficiency.
Deep Autoencoding Topic Model with Scalable Hybrid Bayesian Inference
Jun 15, 2020
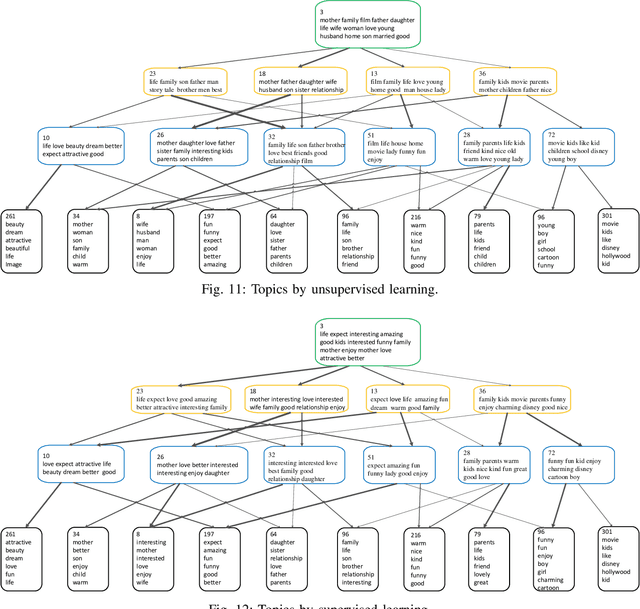
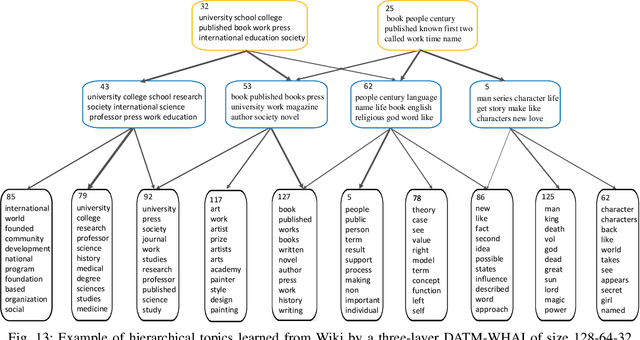
To build a flexible and interpretable model for document analysis, we develop deep autoencoding topic model (DATM) that uses a hierarchy of gamma distributions to construct its multi-stochastic-layer generative network. In order to provide scalable posterior inference for the parameters of the generative network, we develop topic-layer-adaptive stochastic gradient Riemannian MCMC that jointly learns simplex-constrained global parameters across all layers and topics, with topic and layer specific learning rates. Given a posterior sample of the global parameters, in order to efficiently infer the local latent representations of a document under DATM across all stochastic layers, we propose a Weibull upward-downward variational encoder that deterministically propagates information upward via a deep neural network, followed by a Weibull distribution based stochastic downward generative model. To jointly model documents and their associated labels, we further propose supervised DATM that enhances the discriminative power of its latent representations. The efficacy and scalability of our models are demonstrated on both unsupervised and supervised learning tasks on big corpora.
GAN Memory with No Forgetting
Jun 13, 2020



Seeking to address the fundamental issue of memory in lifelong learning, we propose a GAN memory that is capable of realistically remembering a stream of generative processes with \emph{no} forgetting. Our GAN memory is based on recognizing that one can modulate the ``style'' of a GAN model to form perceptually-distant targeted generation. Accordingly, we propose to do sequential style modulations atop a well-behaved base GAN model, to form sequential targeted generative models, while simultaneously benefiting from the transferred base knowledge. Experiments demonstrate the superiority of our method over existing approaches and its effectiveness in alleviating catastrophic forgetting for lifelong classification problems.
On Leveraging Pretrained GANs for Limited-Data Generation
Feb 26, 2020



Recent work has shown GANs can generate highly realistic images that are indistinguishable by human. Of particular interest here is the empirical observation that most generated images are not contained in training datasets, indicating potential generalization with GANs. That generalizability makes it appealing to exploit GANs to help applications with limited available data, e.g., augment training data to alleviate overfitting. To better facilitate training a GAN on limited data, we propose to leverage already-available GAN models pretrained on large-scale datasets (like ImageNet) to introduce additional common knowledge (which may not exist within the limited data) following the transfer learning idea. Specifically, exampled by natural image generation tasks, we reveal the fact that low-level filters (those close to observations) of both the generator and discriminator of pretrained GANs can be transferred to help the target limited-data generation. For better adaption of the transferred filters to the target domain, we introduce a new technique named adaptive filter modulation (AdaFM), which provides boosted performance over baseline methods. Unifying the transferred filters and the introduced techniques, we present our method and conduct extensive experiments to demonstrate its training efficiency and better performance on limited-data generation.
GO Gradient for Expectation-Based Objectives
Jan 17, 2019


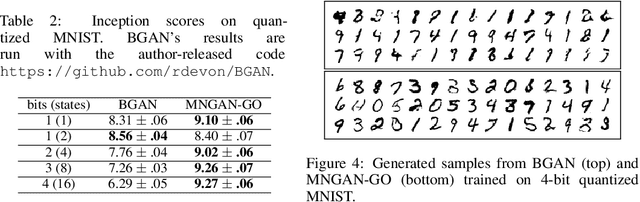
Within many machine learning algorithms, a fundamental problem concerns efficient calculation of an unbiased gradient wrt parameters $\gammav$ for expectation-based objectives $\Ebb_{q_{\gammav} (\yv)} [f(\yv)]$. Most existing methods either (i) suffer from high variance, seeking help from (often) complicated variance-reduction techniques; or (ii) they only apply to reparameterizable continuous random variables and employ a reparameterization trick. To address these limitations, we propose a General and One-sample (GO) gradient that (i) applies to many distributions associated with non-reparameterizable continuous or discrete random variables, and (ii) has the same low-variance as the reparameterization trick. We find that the GO gradient often works well in practice based on only one Monte Carlo sample (although one can of course use more samples if desired). Alongside the GO gradient, we develop a means of propagating the chain rule through distributions, yielding statistical back-propagation, coupling neural networks to common random variables.
Deep Latent Dirichlet Allocation with Topic-Layer-Adaptive Stochastic Gradient Riemannian MCMC
Jun 06, 2017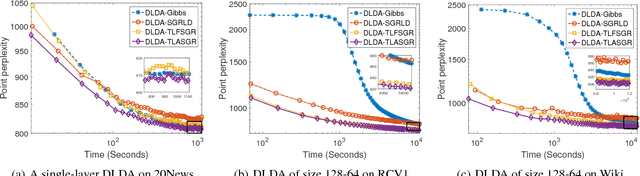

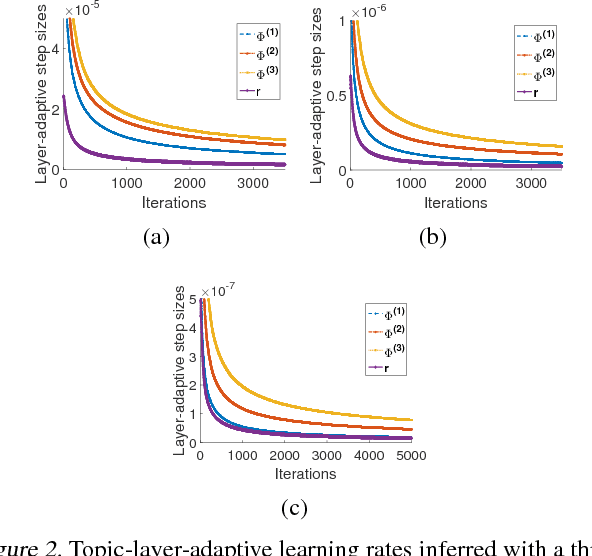
It is challenging to develop stochastic gradient based scalable inference for deep discrete latent variable models (LVMs), due to the difficulties in not only computing the gradients, but also adapting the step sizes to different latent factors and hidden layers. For the Poisson gamma belief network (PGBN), a recently proposed deep discrete LVM, we derive an alternative representation that is referred to as deep latent Dirichlet allocation (DLDA). Exploiting data augmentation and marginalization techniques, we derive a block-diagonal Fisher information matrix and its inverse for the simplex-constrained global model parameters of DLDA. Exploiting that Fisher information matrix with stochastic gradient MCMC, we present topic-layer-adaptive stochastic gradient Riemannian (TLASGR) MCMC that jointly learns simplex-constrained global parameters across all layers and topics, with topic and layer specific learning rates. State-of-the-art results are demonstrated on big data sets.
Gamma Belief Networks
Oct 06, 2016



To infer multilayer deep representations of high-dimensional discrete and nonnegative real vectors, we propose an augmentable gamma belief network (GBN) that factorizes each of its hidden layers into the product of a sparse connection weight matrix and the nonnegative real hidden units of the next layer. The GBN's hidden layers are jointly trained with an upward-downward Gibbs sampler that solves each layer with the same subroutine. The gamma-negative binomial process combined with a layer-wise training strategy allows inferring the width of each layer given a fixed budget on the width of the first layer. Example results illustrate interesting relationships between the width of the first layer and the inferred network structure, and demonstrate that the GBN can add more layers to improve its performance in both unsupervisedly extracting features and predicting heldout data. For exploratory data analysis, we extract trees and subnetworks from the learned deep network to visualize how the very specific factors discovered at the first hidden layer and the increasingly more general factors discovered at deeper hidden layers are related to each other, and we generate synthetic data by propagating random variables through the deep network from the top hidden layer back to the bottom data layer.
* 44 pages, 24 figures