 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun-hui Liu
Simultaneous Estimation of Shape and Force along Highly Deformable Surgical Manipulators Using Sparse FBG Measurement
Apr 25, 2024
Recently, fiber optic sensors such as fiber Bragg gratings (FBGs) have been widely investigated for shape reconstruction and force estimation of flexible surgical robots. However, most existing approaches need precise model parameters of FBGs inside the fiber and their alignments with the flexible robots for accurate sensing results. Another challenge lies in online acquiring external forces at arbitrary locations along the flexible robots, which is highly required when with large deflections in robotic surgery. In this paper, we propose a novel data-driven paradigm for simultaneous estimation of shape and force along highly deformable flexible robots by using sparse strain measurement from a single-core FBG fiber. A thin-walled soft sensing tube helically embedded with FBG sensors is designed for a robotic-assisted flexible ureteroscope with large deflection up to 270 degrees and a bend radius under 10 mm. We introduce and study three learning models by incorporating spatial strain encoders, and compare their performances in both free space and constrained environments with contact forces at different locations. The experimental results in terms of dynamic shape-force sensing accuracy demonstrate the effectiveness and superiority of the proposed methods.
Speed Co-Augmentation for Unsupervised Audio-Visual Pre-training
Sep 25, 2023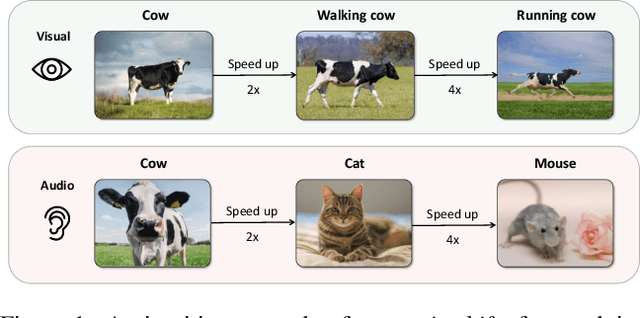
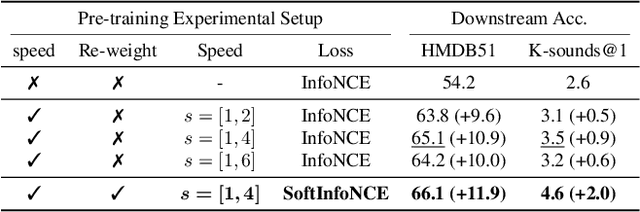
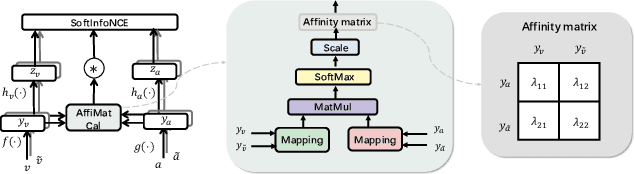
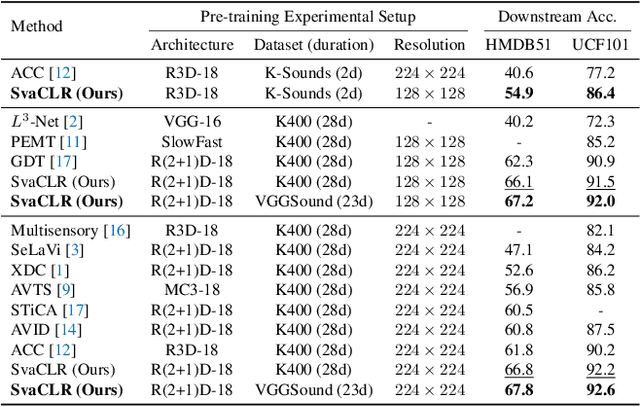
This work aims to improve unsupervised audio-visual pre-training. Inspired by the efficacy of data augmentation in visual contrastive learning, we propose a novel speed co-augmentation method that randomly changes the playback speeds of both audio and video data. Despite its simplicity, the speed co-augmentation method possesses two compelling attributes: (1) it increases the diversity of audio-visual pairs and doubles the size of negative pairs, resulting in a significant enhancement in the learned representations, and (2) it changes the strict correlation between audio-visual pairs but introduces a partial relationship between the augmented pairs, which is modeled by our proposed SoftInfoNCE loss to further boost the performance. Experimental results show that the proposed method significantly improves the learned representations when compared to vanilla audio-visual contrastive learning.
Autonomous Intelligent Navigation for Flexible Endoscopy Using Monocular Depth Guidance and 3-D Shape Planning
Feb 26, 2023



Recent advancements toward perception and decision-making of flexible endoscopes have shown great potential in computer-aided surgical interventions. However, owing to modeling uncertainty and inter-patient anatomical variation in flexible endoscopy, the challenge remains for efficient and safe navigation in patient-specific scenarios. This paper presents a novel data-driven framework with self-contained visual-shape fusion for autonomous intelligent navigation of flexible endoscopes requiring no priori knowledge of system models and global environments. A learning-based adaptive visual servoing controller is proposed to online update the eye-in-hand vision-motor configuration and steer the endoscope, which is guided by monocular depth estimation via a vision transformer (ViT). To prevent unnecessary and excessive interactions with surrounding anatomy, an energy-motivated shape planning algorithm is introduced through entire endoscope 3-D proprioception from embedded fiber Bragg grating (FBG) sensors. Furthermore, a model predictive control (MPC) strategy is developed to minimize the elastic potential energy flow and simultaneously optimize the steering policy. Dedicated navigation experiments on a robotic-assisted flexible endoscope with an FBG fiber in several phantom environments demonstrate the effectiveness and adaptability of the proposed framework.
Self-supervised Video Representation Learning by Uncovering Spatio-temporal Statistics
Aug 31, 2020
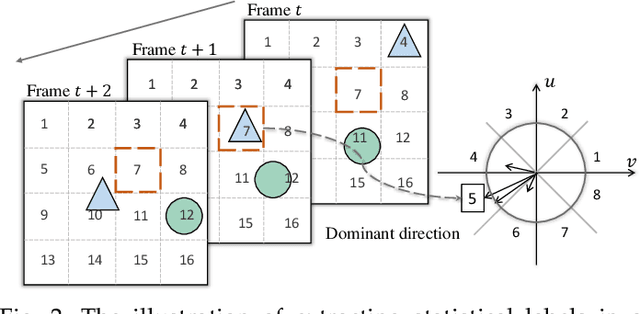
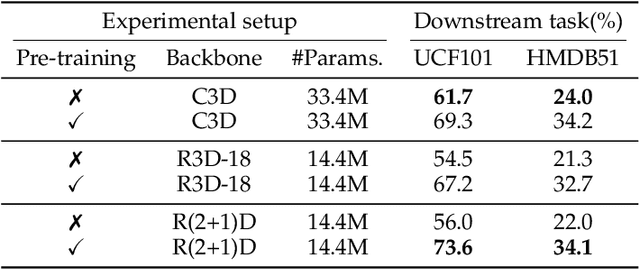

This paper proposes a novel pretext task to address the self-supervised video representation learning problem. Specifically, given an unlabeled video clip, we compute a series of spatio-temporal statistical summaries, such as the spatial location and dominant direction of the largest motion, the spatial location and dominant color of the largest color diversity along the temporal axis, etc. Then a neural network is built and trained to yield the statistical summaries given the video frames as inputs. In order to alleviate the learning difficulty, we employ several spatial partitioning patterns to encode rough spatial locations instead of exact spatial Cartesian coordinates. Our approach is inspired by the observation that human visual system is sensitive to rapidly changing contents in the visual field, and only needs impressions about rough spatial locations to understand the visual contents. To validate the effectiveness of the proposed approach, we conduct extensive experiments with several 3D backbone networks, i.e., C3D, 3D-ResNet and R(2+1)D. The results show that our approach outperforms the existing approaches across the three backbone networks on various downstream video analytic tasks including action recognition, video retrieval, dynamic scene recognition, and action similarity labeling. The source code is made publicly available at: https://github.com/laura-wang/video_repres_sts.