 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunduan Cui
Effective Multi-Agent Deep Reinforcement Learning Control with Relative Entropy Regularization
Sep 26, 2023
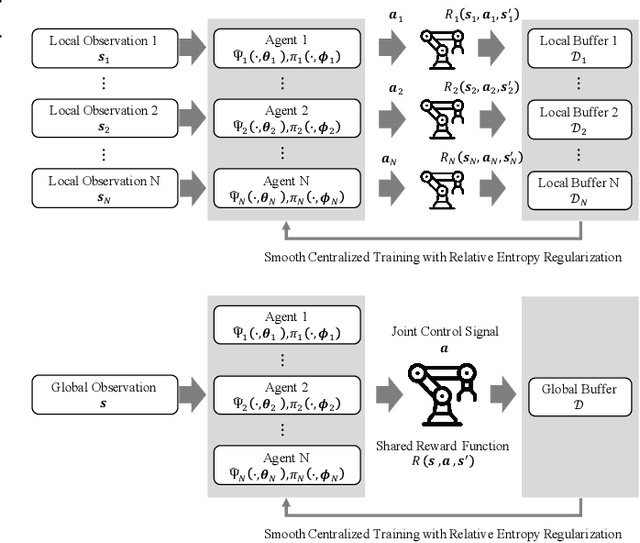
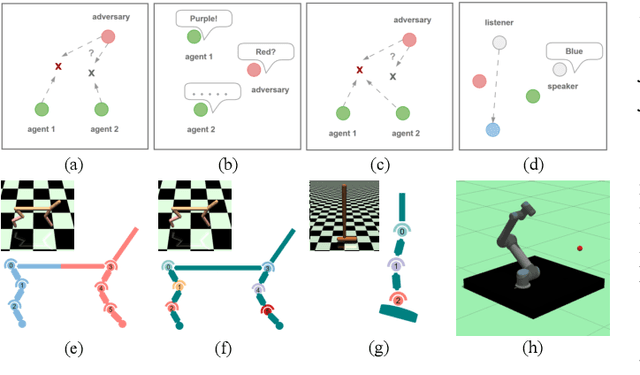
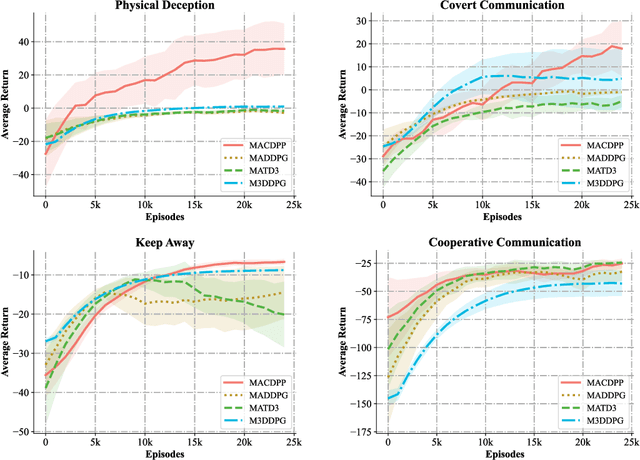
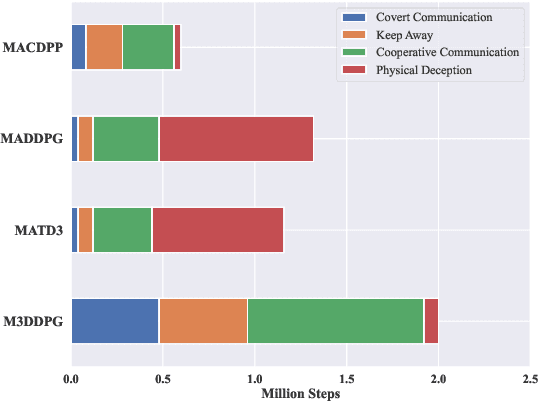
In this paper, a novel Multi-agent Reinforcement Learning (MARL) approach, Multi-Agent Continuous Dynamic Policy Gradient (MACDPP) was proposed to tackle the issues of limited capability and sample efficiency in various scenarios controlled by multiple agents. It alleviates the inconsistency of multiple agents' policy updates by introducing the relative entropy regularization to the Centralized Training with Decentralized Execution (CTDE) framework with the Actor-Critic (AC) structure. Evaluated by multi-agent cooperation and competition tasks and traditional control tasks including OpenAI benchmarks and robot arm manipulation, MACDPP demonstrates significant superiority in learning capability and sample efficiency compared with both related multi-agent and widely implemented signal-agent baselines and therefore expands the potential of MARL in effectively learning challenging control scenarios.
Practical Probabilistic Model-based Deep Reinforcement Learning by Integrating Dropout Uncertainty and Trajectory Sampling
Sep 20, 2023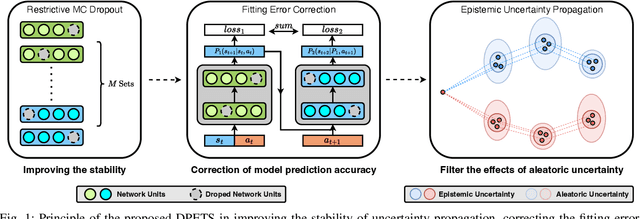
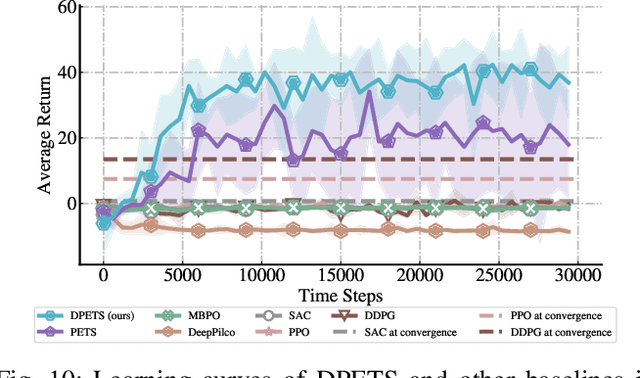
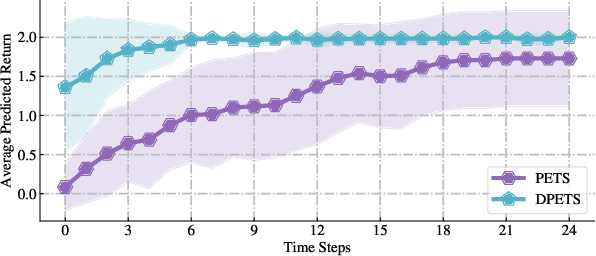
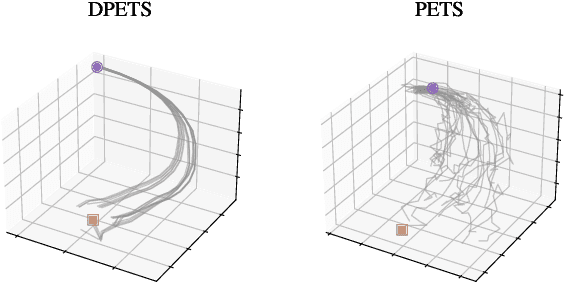
This paper addresses the prediction stability, prediction accuracy and control capability of the current probabilistic model-based reinforcement learning (MBRL) built on neural networks. A novel approach dropout-based probabilistic ensembles with trajectory sampling (DPETS) is proposed where the system uncertainty is stably predicted by combining the Monte-Carlo dropout and trajectory sampling in one framework. Its loss function is designed to correct the fitting error of neural networks for more accurate prediction of probabilistic models. The state propagation in its policy is extended to filter the aleatoric uncertainty for superior control capability. Evaluated by several Mujoco benchmark control tasks under additional disturbances and one practical robot arm manipulation task, DPETS outperforms related MBRL approaches in both average return and convergence velocity while achieving superior performance than well-known model-free baselines with significant sample efficiency. The open source code of DPETS is available at https://github.com/mrjun123/DPETS.
Uncertainty-aware Contact-safe Model-based Reinforcement Learning
Oct 16, 2020



This paper presents contact-safe Model-based Reinforcement Learning (MBRL) for robot applications that achieves contact-safe behaviors in the learning process. In typical MBRL, we cannot expect the data-driven model to generate accurate and reliable policies to the intended robotic tasks during the learning process due to data scarcity. Operating these unreliable policies in a contact-rich environment could cause damage to the robot and its surroundings. To alleviate the risk of causing damage through unexpected intensive physical contacts, we present the contact-safe MBRL that associates the probabilistic Model Predictive Control's (pMPC) control limits with the model uncertainty so that the allowed acceleration of controlled behavior is adjusted according to learning progress. Control planning with such uncertainty-aware control limits is formulated as a deterministic MPC problem using a computationally-efficient approximated GP dynamics and an approximated inference technique. Our approach's effectiveness is evaluated through bowl mixing tasks with simulated and real robots, scooping tasks with a real robot as examples of contact-rich manipulation skills. (video: https://youtu.be/8uTDYYUKeFM)