 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuning Wu
Towards Human-Centered Construction Robotics: An RL-Driven Companion Robot For Contextually Assisting Carpentry Workers
Mar 29, 2024

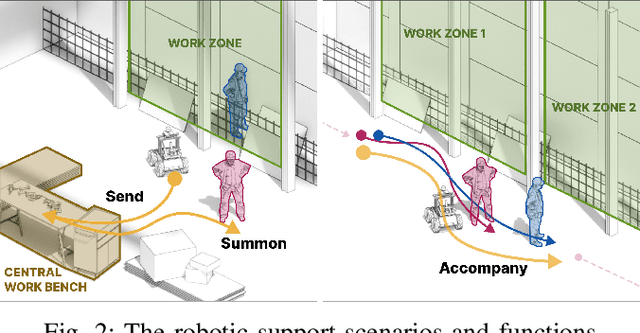
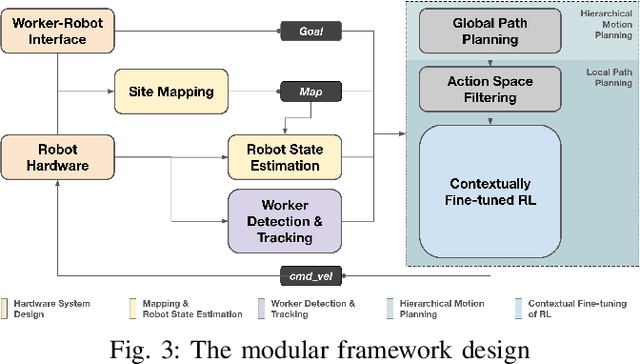

In the dynamic construction industry, traditional robotic integration has primarily focused on automating specific tasks, often overlooking the complexity and variability of human aspects in construction workflows. This paper introduces a human-centered approach with a "work companion rover" designed to assist construction workers within their existing practices, aiming to enhance safety and workflow fluency while respecting construction labor's skilled nature. We conduct an in-depth study on deploying a robotic system in carpentry formwork, showcasing a prototype that emphasizes mobility, safety, and comfortable worker-robot collaboration in dynamic environments through a contextual Reinforcement Learning (RL)-driven modular framework. Our research advances robotic applications in construction, advocating for collaborative models where adaptive robots support rather than replace humans, underscoring the potential for an interactive and collaborative human-robot workforce.
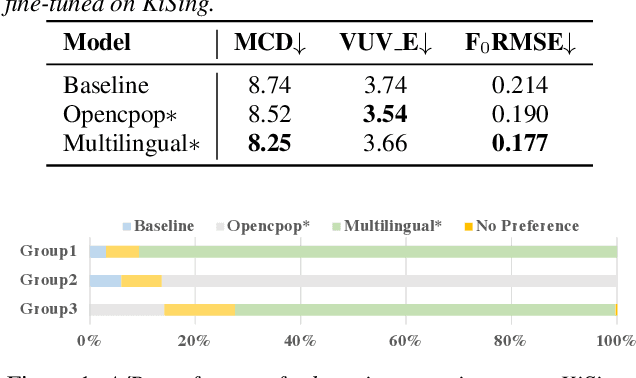
Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and KiSing-v2
Jan 31, 2024In singing voice synthesis (SVS), generating singing voices from musical scores faces challenges due to limited data availability, a constraint less common in text-to-speech (TTS). This study proposes a new approach to address this data scarcity. We utilize an existing singing voice synthesizer for data augmentation and apply precise manual tuning to reduce unnatural voice synthesis. Our development of two extensive singing voice corpora, ACE-Opencpop and KiSing-v2, facilitates large-scale, multi-singer voice synthesis. Utilizing pre-trained models derived from these corpora, we achieve notable improvements in voice quality, evident in both in-domain and out-of-domain scenarios. The corpora, pre-trained models, and their related training recipes are publicly available at Muskits-ESPnet (https://github.com/espnet/espnet).
A Systematic Exploration of Joint-training for Singing Voice Synthesis
Aug 05, 2023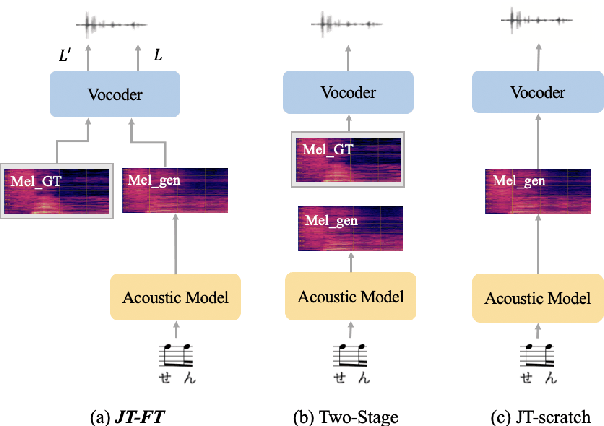
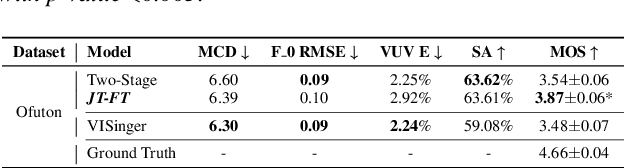
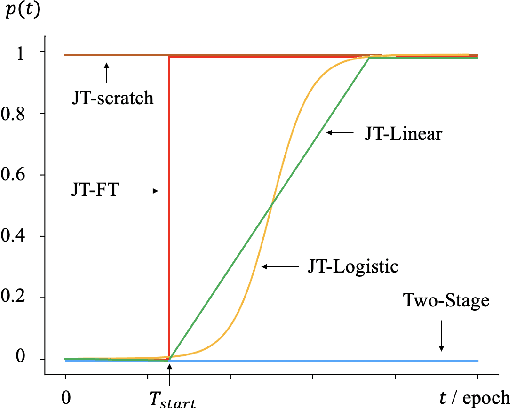
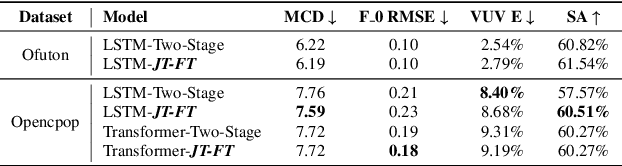
There has been a growing interest in using end-to-end acoustic models for singing voice synthesis (SVS). Typically, these models require an additional vocoder to transform the generated acoustic features into the final waveform. However, since the acoustic model and the vocoder are not jointly optimized, a gap can exist between the two models, leading to suboptimal performance. Although a similar problem has been addressed in the TTS systems by joint-training or by replacing acoustic features with a latent representation, adopting corresponding approaches to SVS is not an easy task. How to improve the joint-training of SVS systems has not been well explored. In this paper, we conduct a systematic investigation of how to better perform a joint-training of an acoustic model and a vocoder for SVS. We carry out extensive experiments and demonstrate that our joint-training strategy outperforms baselines, achieving more stable performance across different datasets while also increasing the interpretability of the entire framework.
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
Apr 25, 2023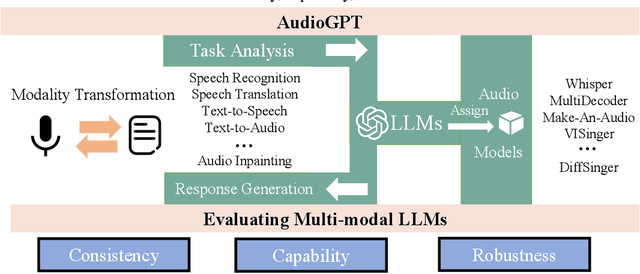
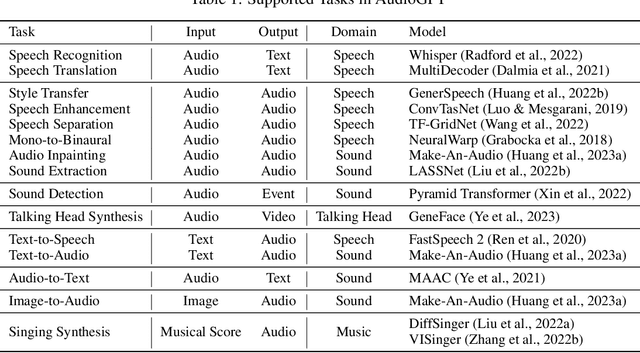
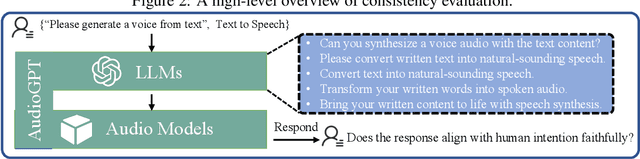

Large language models (LLMs) have exhibited remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Despite the recent success, current LLMs are not capable of processing complex audio information or conducting spoken conversations (like Siri or Alexa). In this work, we propose a multi-modal AI system named AudioGPT, which complements LLMs (i.e., ChatGPT) with 1) foundation models to process complex audio information and solve numerous understanding and generation tasks; and 2) the input/output interface (ASR, TTS) to support spoken dialogue. With an increasing demand to evaluate multi-modal LLMs of human intention understanding and cooperation with foundation models, we outline the principles and processes and test AudioGPT in terms of consistency, capability, and robustness. Experimental results demonstrate the capabilities of AudioGPT in solving AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease. Our system is publicly available at \url{https://github.com/AIGC-Audio/AudioGPT}.
PHONEix: Acoustic Feature Processing Strategy for Enhanced Singing Pronunciation with Phoneme Distribution Predictor
Mar 15, 2023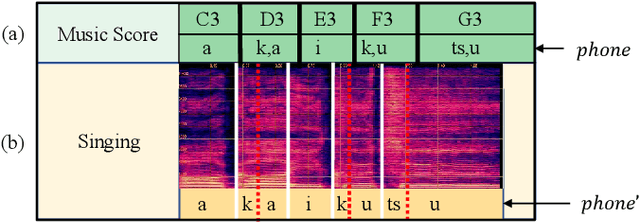
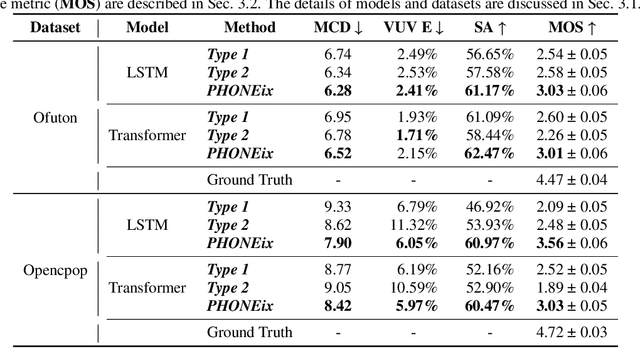
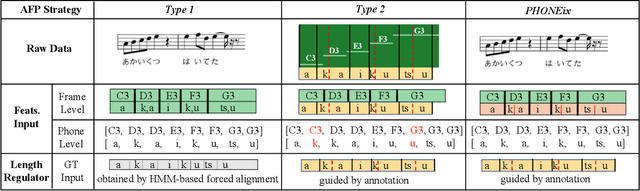
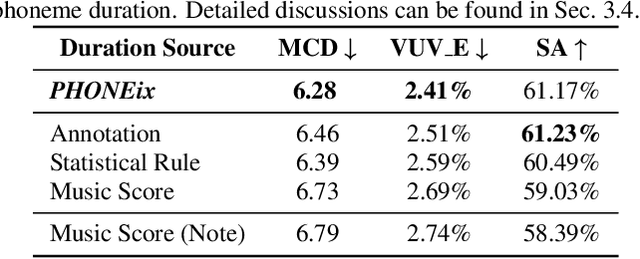
Singing voice synthesis (SVS), as a specific task for generating the vocal singing voice from a music score, has drawn much attention in recent years. SVS faces the challenge that the singing has various pronunciation flexibility conditioned on the same music score. Most of the previous works of SVS can not well handle the misalignment between the music score and actual singing. In this paper, we propose an acoustic feature processing strategy, named PHONEix, with a phoneme distribution predictor, to alleviate the gap between the music score and the singing voice, which can be easily adopted in different SVS systems. Extensive experiments in various settings demonstrate the effectiveness of our PHONEix in both objective and subjective evaluations.
Learning Dense Reward with Temporal Variant Self-Supervision
May 26, 2022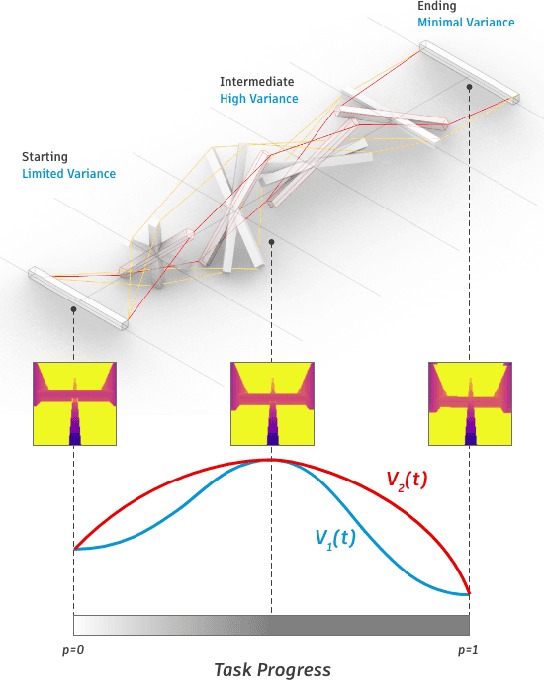
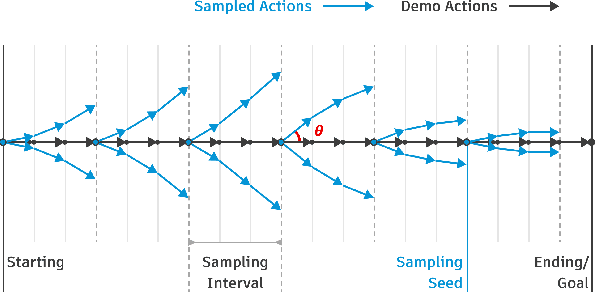
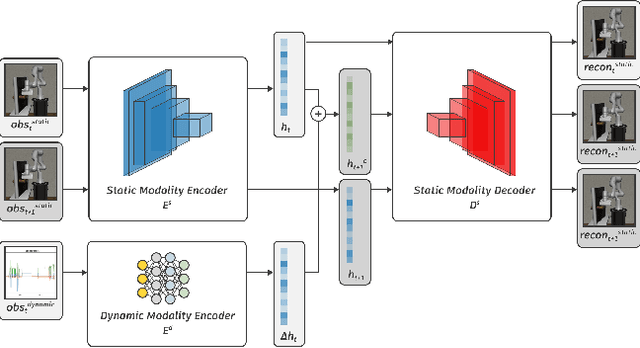
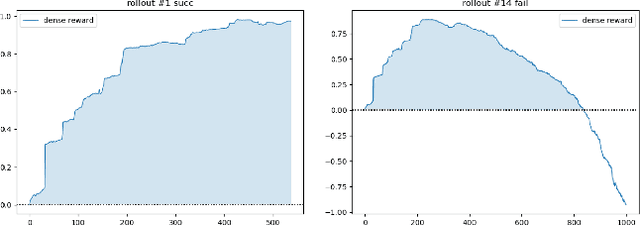
Rewards play an essential role in reinforcement learning. In contrast to rule-based game environments with well-defined reward functions, complex real-world robotic applications, such as contact-rich manipulation, lack explicit and informative descriptions that can directly be used as a reward. Previous effort has shown that it is possible to algorithmically extract dense rewards directly from multimodal observations. In this paper, we aim to extend this effort by proposing a more efficient and robust way of sampling and learning. In particular, our sampling approach utilizes temporal variance to simulate the fluctuating state and action distribution of a manipulation task. We then proposed a network architecture for self-supervised learning to better incorporate temporal information in latent representations. We tested our approach in two experimental setups, namely joint-assembly and door-opening. Preliminary results show that our approach is effective and efficient in learning dense rewards, and the learned rewards lead to faster convergence than baselines.
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022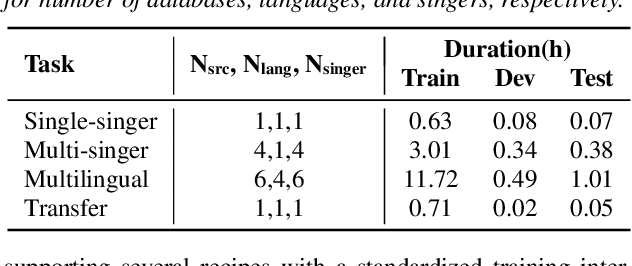
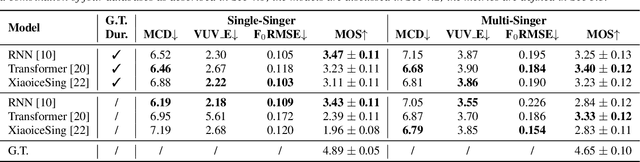
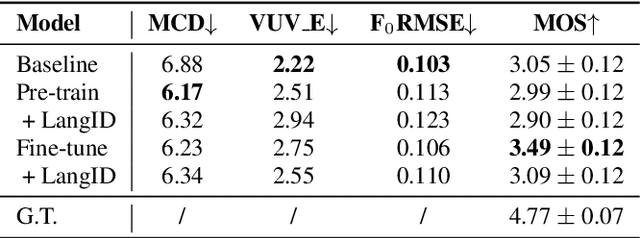
This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.