 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYupeng Hou
CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation
Mar 11, 2024
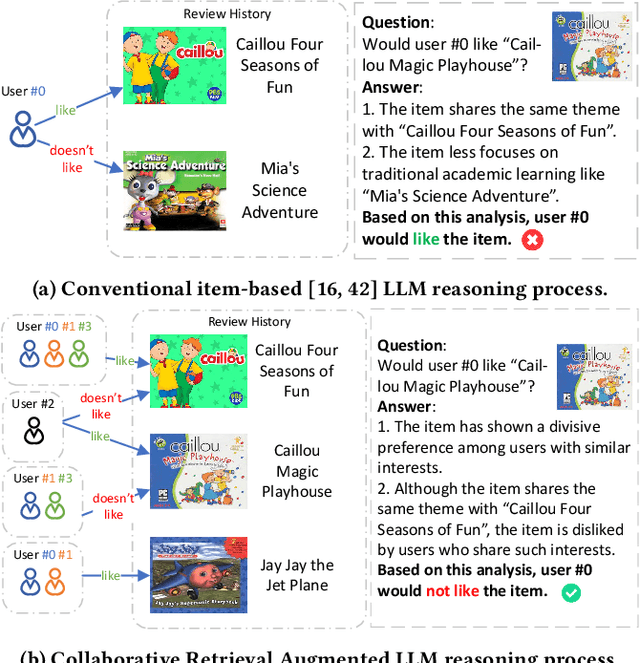
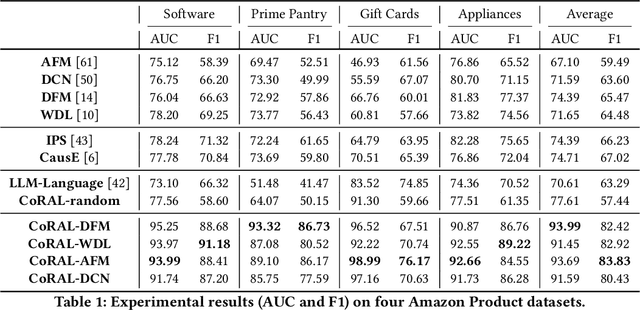
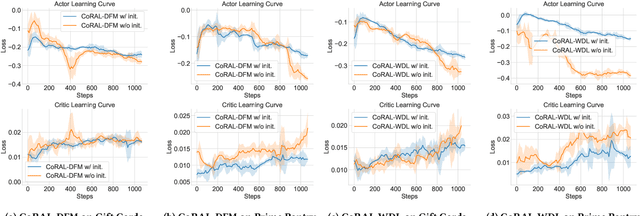
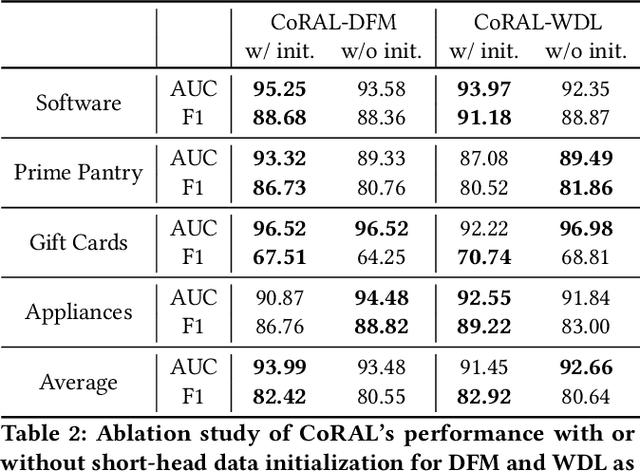
The long-tail recommendation is a challenging task for traditional recommender systems, due to data sparsity and data imbalance issues. The recent development of large language models (LLMs) has shown their abilities in complex reasoning, which can help to deduce users' preferences based on very few previous interactions. However, since most LLM-based systems rely on items' semantic meaning as the sole evidence for reasoning, the collaborative information of user-item interactions is neglected, which can cause the LLM's reasoning to be misaligned with task-specific collaborative information of the dataset. To further align LLMs' reasoning to task-specific user-item interaction knowledge, we introduce collaborative retrieval-augmented LLMs, CoRAL, which directly incorporate collaborative evidence into the prompts. Based on the retrieved user-item interactions, the LLM can analyze shared and distinct preferences among users, and summarize the patterns indicating which types of users would be attracted by certain items. The retrieved collaborative evidence prompts the LLM to align its reasoning with the user-item interaction patterns in the dataset. However, since the capacity of the input prompt is limited, finding the minimally-sufficient collaborative information for recommendation tasks can be challenging. We propose to find the optimal interaction set through a sequential decision-making process and develop a retrieval policy learned through a reinforcement learning (RL) framework, CoRAL. Our experimental results show that CoRAL can significantly improve LLMs' reasoning abilities on specific recommendation tasks. Our analysis also reveals that CoRAL can more efficiently explore collaborative information through reinforcement learning.
Bridging Language and Items for Retrieval and Recommendation
Mar 06, 2024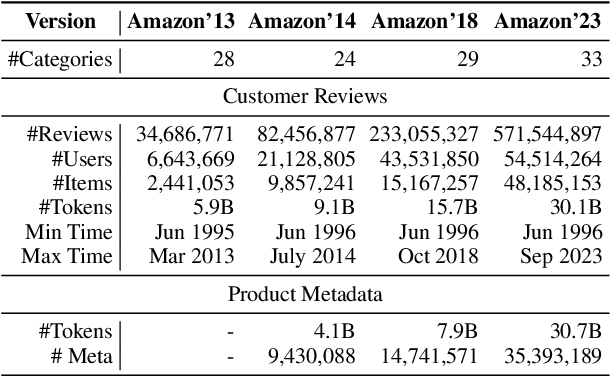
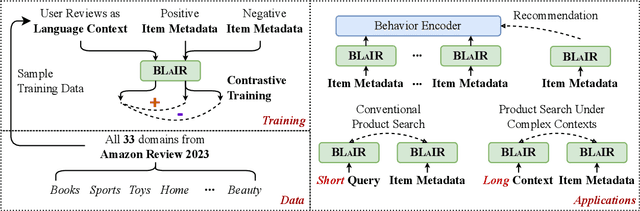
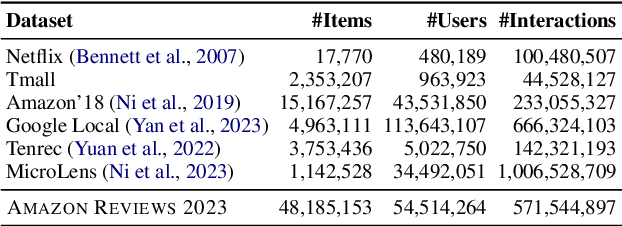

This paper introduces BLaIR, a series of pretrained sentence embedding models specialized for recommendation scenarios. BLaIR is trained to learn correlations between item metadata and potential natural language context, which is useful for retrieving and recommending items. To pretrain BLaIR, we collect Amazon Reviews 2023, a new dataset comprising over 570 million reviews and 48 million items from 33 categories, significantly expanding beyond the scope of previous versions. We evaluate the generalization ability of BLaIR across multiple domains and tasks, including a new task named complex product search, referring to retrieving relevant items given long, complex natural language contexts. Leveraging large language models like ChatGPT, we correspondingly construct a semi-synthetic evaluation set, Amazon-C4. Empirical results on the new task, as well as conventional retrieval and recommendation tasks, demonstrate that BLaIR exhibit strong text and item representation capacity. Our datasets, code, and checkpoints are available at: https://github.com/hyp1231/AmazonReviews2023.
InstructGraph: Boosting Large Language Models via Graph-centric Instruction Tuning and Preference Alignment
Feb 13, 2024Do current large language models (LLMs) better solve graph reasoning and generation tasks with parameter updates? In this paper, we propose InstructGraph, a framework that empowers LLMs with the abilities of graph reasoning and generation by instruction tuning and preference alignment. Specifically, we first propose a structured format verbalizer to unify all graph data into a universal code-like format, which can simply represent the graph without any external graph-specific encoders. Furthermore, a graph instruction tuning stage is introduced to guide LLMs in solving graph reasoning and generation tasks. Finally, we identify potential hallucination problems in graph tasks and sample negative instances for preference alignment, the target of which is to enhance the output's reliability of the model. Extensive experiments across multiple graph-centric tasks exhibit that InstructGraph can achieve the best performance and outperform GPT-4 and LLaMA2 by more than 13\% and 38\%, respectively.
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Nov 28, 2023



Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Scaling Law of Large Sequential Recommendation Models
Nov 19, 2023



Scaling of neural networks has recently shown great potential to improve the model capacity in various fields. Specifically, model performance has a power-law relationship with model size or data size, which provides important guidance for the development of large-scale models. However, there is still limited understanding on the scaling effect of user behavior models in recommender systems, where the unique data characteristics (e.g. data scarcity and sparsity) pose new challenges to explore the scaling effect in recommendation tasks. In this work, we focus on investigating the scaling laws in large sequential recommendation models. Specially, we consider a pure ID-based task formulation, where the interaction history of a user is formatted as a chronological sequence of item IDs. We don't incorporate any side information (e.g. item text), because we would like to explore how scaling law holds from the perspective of user behavior. With specially improved strategies, we scale up the model size to 0.8B parameters, making it feasible to explore the scaling effect in a diverse range of model sizes. As the major findings, we empirically show that scaling law still holds for these trained models, even in data-constrained scenarios. We then fit the curve for scaling law, and successfully predict the test loss of the two largest tested model scales. Furthermore, we examine the performance advantage of scaling effect on five challenging recommendation tasks, considering the unique issues (e.g. cold start, robustness, long-term preference) in recommender systems. We find that scaling up the model size can greatly boost the performance on these challenging tasks, which again verifies the benefits of large recommendation models.
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
Oct 13, 2023
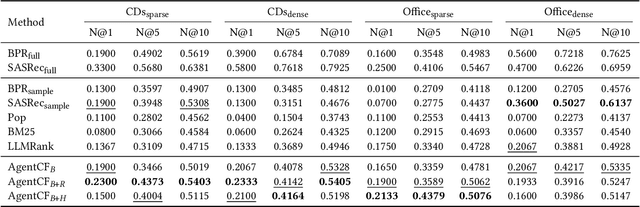

Recently, there has been an emergence of employing LLM-powered agents as believable human proxies, based on their remarkable decision-making capability. However, existing studies mainly focus on simulating human dialogue. Human non-verbal behaviors, such as item clicking in recommender systems, although implicitly exhibiting user preferences and could enhance the modeling of users, have not been deeply explored. The main reasons lie in the gap between language modeling and behavior modeling, as well as the incomprehension of LLMs about user-item relations. To address this issue, we propose AgentCF for simulating user-item interactions in recommender systems through agent-based collaborative filtering. We creatively consider not only users but also items as agents, and develop a collaborative learning approach that optimizes both kinds of agents together. Specifically, at each time step, we first prompt the user and item agents to interact autonomously. Then, based on the disparities between the agents' decisions and real-world interaction records, user and item agents are prompted to reflect on and adjust the misleading simulations collaboratively, thereby modeling their two-sided relations. The optimized agents can also propagate their preferences to other agents in subsequent interactions, implicitly capturing the collaborative filtering idea. Overall, the optimized agents exhibit diverse interaction behaviors within our framework, including user-item, user-user, item-item, and collective interactions. The results show that these agents can demonstrate personalized behaviors akin to those of real-world individuals, sparking the development of next-generation user behavior simulation.
Reciprocal Sequential Recommendation
Jun 26, 2023



Reciprocal recommender system (RRS), considering a two-way matching between two parties, has been widely applied in online platforms like online dating and recruitment. Existing RRS models mainly capture static user preferences, which have neglected the evolving user tastes and the dynamic matching relation between the two parties. Although dynamic user modeling has been well-studied in sequential recommender systems, existing solutions are developed in a user-oriented manner. Therefore, it is non-trivial to adapt sequential recommendation algorithms to reciprocal recommendation. In this paper, we formulate RRS as a distinctive sequence matching task, and further propose a new approach ReSeq for RRS, which is short for Reciprocal Sequential recommendation. To capture dual-perspective matching, we propose to learn fine-grained sequence similarities by co-attention mechanism across different time steps. Further, to improve the inference efficiency, we introduce the self-distillation technique to distill knowledge from the fine-grained matching module into the more efficient student module. In the deployment stage, only the efficient student module is used, greatly speeding up the similarity computation. Extensive experiments on five real-world datasets from two scenarios demonstrate the effectiveness and efficiency of the proposed method. Our code is available at https://github.com/RUCAIBox/ReSeq/.
Large Language Models are Zero-Shot Rankers for Recommender Systems
May 15, 2023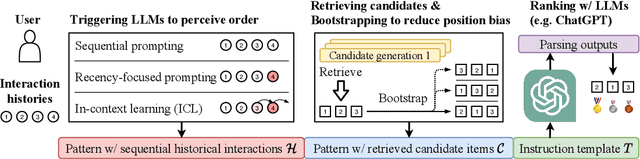

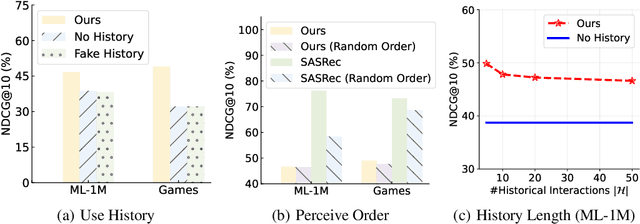
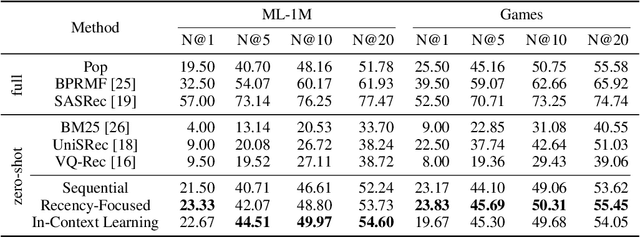
Recently, large language models (LLMs) (e.g. GPT-4) have demonstrated impressive general-purpose task-solving abilities, including the potential to approach recommendation tasks. Along this line of research, this work aims to investigate the capacity of LLMs that act as the ranking model for recommender systems. To conduct our empirical study, we first formalize the recommendation problem as a conditional ranking task, considering sequential interaction histories as conditions and the items retrieved by the candidate generation model as candidates. We adopt a specific prompting approach to solving the ranking task by LLMs: we carefully design the prompting template by including the sequential interaction history, the candidate items, and the ranking instruction. We conduct extensive experiments on two widely-used datasets for recommender systems and derive several key findings for the use of LLMs in recommender systems. We show that LLMs have promising zero-shot ranking abilities, even competitive to or better than conventional recommendation models on candidates retrieved by multiple candidate generators. We also demonstrate that LLMs struggle to perceive the order of historical interactions and can be affected by biases like position bias, while these issues can be alleviated via specially designed prompting and bootstrapping strategies. The code to reproduce this work is available at https://github.com/RUCAIBox/LLMRank.
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
May 11, 2023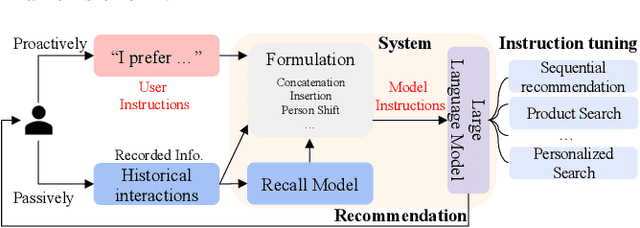

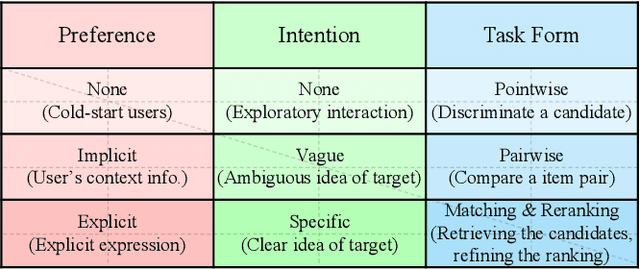
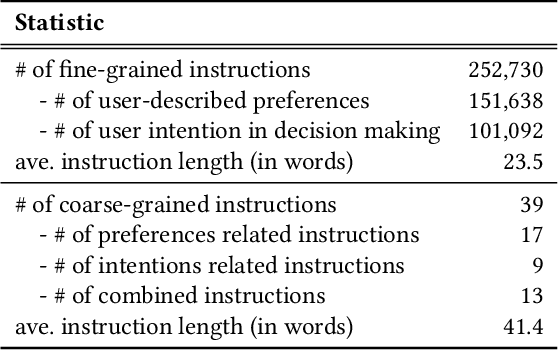
In the past decades, recommender systems have attracted much attention in both research and industry communities, and a large number of studies have been devoted to developing effective recommendation models. Basically speaking, these models mainly learn the underlying user preference from historical behavior data, and then estimate the user-item matching relationships for recommendations. Inspired by the recent progress on large language models (LLMs), we take a different approach to developing the recommendation models, considering recommendation as instruction following by LLMs. The key idea is that the preferences or needs of a user can be expressed in natural language descriptions (called instructions), so that LLMs can understand and further execute the instruction for fulfilling the recommendation task. Instead of using public APIs of LLMs, we instruction tune an open-source LLM (3B Flan-T5-XL), in order to better adapt LLMs to recommender systems. For this purpose, we first design a general instruction format for describing the preference, intention, task form and context of a user in natural language. Then we manually design 39 instruction templates and automatically generate a large amount of user-personalized instruction data (252K instructions) with varying types of preferences and intentions. To demonstrate the effectiveness of our approach, we instantiate the instruction templates into several widely-studied recommendation (or search) tasks, and conduct extensive experiments on these tasks with real-world datasets. Experiment results show that the proposed approach can outperform several competitive baselines, including the powerful GPT-3.5, on these evaluation tasks. Our approach sheds light on developing more user-friendly recommender systems, in which users can freely communicate with the system and obtain more accurate recommendations via natural language instructions.
Multi-grained Hypergraph Interest Modeling for Conversational Recommendation
May 04, 2023



Conversational recommender system (CRS) interacts with users through multi-turn dialogues in natural language, which aims to provide high-quality recommendations for user's instant information need. Although great efforts have been made to develop effective CRS, most of them still focus on the contextual information from the current dialogue, usually suffering from the data scarcity issue. Therefore, we consider leveraging historical dialogue data to enrich the limited contexts of the current dialogue session. In this paper, we propose a novel multi-grained hypergraph interest modeling approach to capture user interest beneath intricate historical data from different perspectives. As the core idea, we employ hypergraph to represent complicated semantic relations underlying historical dialogues. In our approach, we first employ the hypergraph structure to model users' historical dialogue sessions and form a session-based hypergraph, which captures coarse-grained, session-level relations. Second, to alleviate the issue of data scarcity, we use an external knowledge graph and construct a knowledge-based hypergraph considering fine-grained, entity-level semantics. We further conduct multi-grained hypergraph convolution on the two kinds of hypergraphs, and utilize the enhanced representations to develop interest-aware CRS. Extensive experiments on two benchmarks ReDial and TG-ReDial validate the effectiveness of our approach on both recommendation and conversation tasks. Code is available at: https://github.com/RUCAIBox/MHIM.