 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunda Wu
List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs
Apr 25, 2024
Set-of-Mark (SoM) Prompting unleashes the visual grounding capability of GPT-4V, by enabling the model to associate visual objects with tags inserted on the image. These tags, marked with alphanumerics, can be indexed via text tokens for easy reference. Despite the extraordinary performance from GPT-4V, we observe that other Multimodal Large Language Models (MLLMs) struggle to understand these visual tags. To promote the learning of SoM prompting for open-source models, we propose a new learning paradigm: "list items one by one," which asks the model to enumerate and describe all visual tags placed on the image following the alphanumeric orders of tags. By integrating our curated dataset with other visual instruction tuning datasets, we are able to equip existing MLLMs with the SoM prompting ability. Furthermore, we evaluate our finetuned SoM models on five MLLM benchmarks. We find that this new dataset, even in a relatively small size (10k-30k images with tags), significantly enhances visual reasoning capabilities and reduces hallucinations for MLLMs. Perhaps surprisingly, these improvements persist even when the visual tags are omitted from input images during inference. This suggests the potential of "list items one by one" as a new paradigm for training MLLMs, which strengthens the object-text alignment through the use of visual tags in the training stage. Finally, we conduct analyses by probing trained models to understand the working mechanism of SoM. Our code and data are available at \url{https://github.com/zzxslp/SoM-LLaVA}.
Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
Mar 14, 2024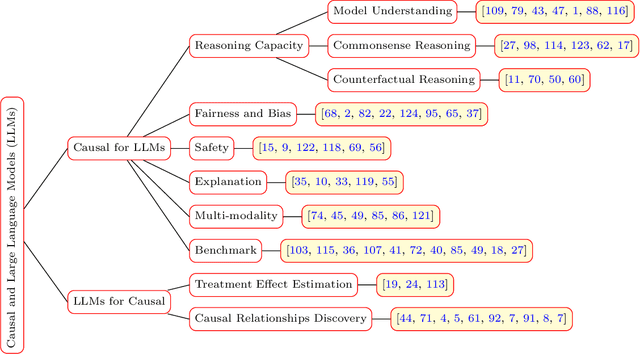
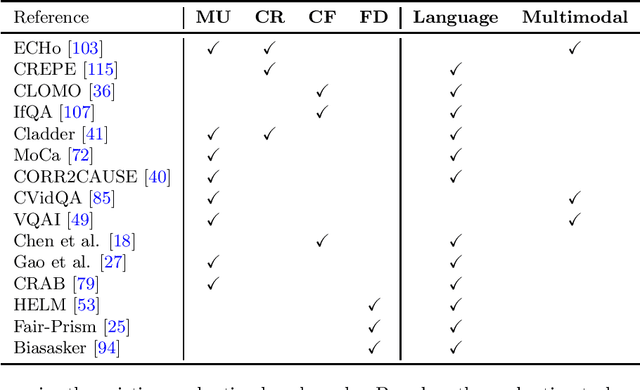
Causal inference has shown potential in enhancing the predictive accuracy, fairness, robustness, and explainability of Natural Language Processing (NLP) models by capturing causal relationships among variables. The emergence of generative Large Language Models (LLMs) has significantly impacted various NLP domains, particularly through their advanced reasoning capabilities. This survey focuses on evaluating and improving LLMs from a causal view in the following areas: understanding and improving the LLMs' reasoning capacity, addressing fairness and safety issues in LLMs, complementing LLMs with explanations, and handling multimodality. Meanwhile, LLMs' strong reasoning capacities can in turn contribute to the field of causal inference by aiding causal relationship discovery and causal effect estimations. This review explores the interplay between causal inference frameworks and LLMs from both perspectives, emphasizing their collective potential to further the development of more advanced and equitable artificial intelligence systems.
CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation
Mar 11, 2024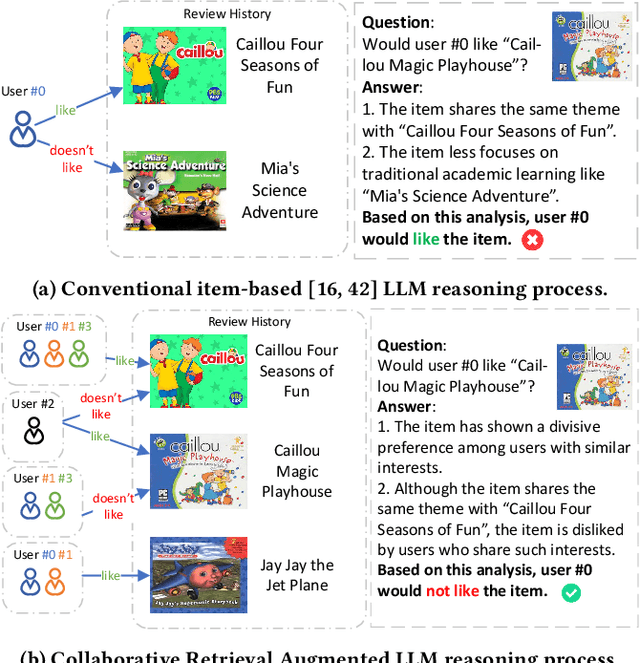
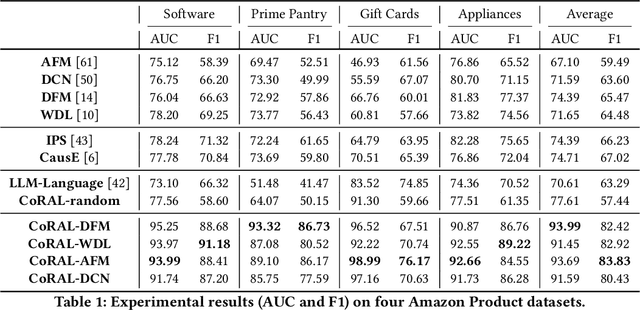
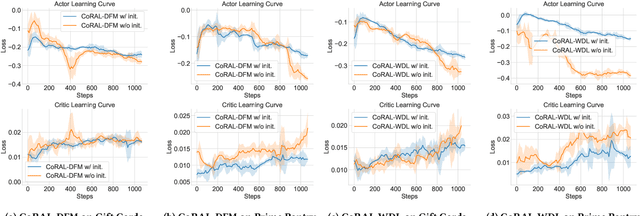
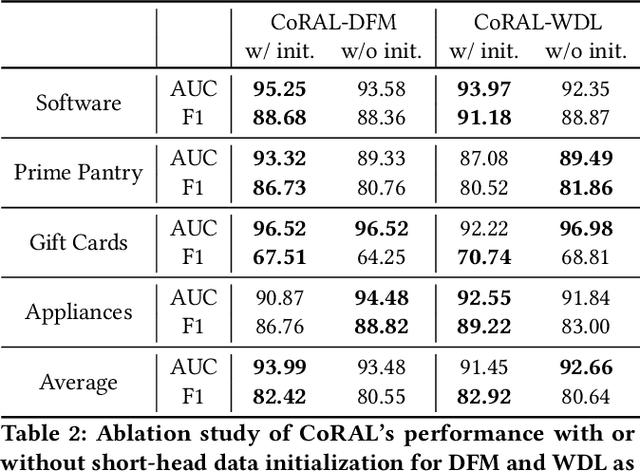
The long-tail recommendation is a challenging task for traditional recommender systems, due to data sparsity and data imbalance issues. The recent development of large language models (LLMs) has shown their abilities in complex reasoning, which can help to deduce users' preferences based on very few previous interactions. However, since most LLM-based systems rely on items' semantic meaning as the sole evidence for reasoning, the collaborative information of user-item interactions is neglected, which can cause the LLM's reasoning to be misaligned with task-specific collaborative information of the dataset. To further align LLMs' reasoning to task-specific user-item interaction knowledge, we introduce collaborative retrieval-augmented LLMs, CoRAL, which directly incorporate collaborative evidence into the prompts. Based on the retrieved user-item interactions, the LLM can analyze shared and distinct preferences among users, and summarize the patterns indicating which types of users would be attracted by certain items. The retrieved collaborative evidence prompts the LLM to align its reasoning with the user-item interaction patterns in the dataset. However, since the capacity of the input prompt is limited, finding the minimally-sufficient collaborative information for recommendation tasks can be challenging. We propose to find the optimal interaction set through a sequential decision-making process and develop a retrieval policy learned through a reinforcement learning (RL) framework, CoRAL. Our experimental results show that CoRAL can significantly improve LLMs' reasoning abilities on specific recommendation tasks. Our analysis also reveals that CoRAL can more efficiently explore collaborative information through reinforcement learning.
InstructGraph: Boosting Large Language Models via Graph-centric Instruction Tuning and Preference Alignment
Feb 13, 2024Do current large language models (LLMs) better solve graph reasoning and generation tasks with parameter updates? In this paper, we propose InstructGraph, a framework that empowers LLMs with the abilities of graph reasoning and generation by instruction tuning and preference alignment. Specifically, we first propose a structured format verbalizer to unify all graph data into a universal code-like format, which can simply represent the graph without any external graph-specific encoders. Furthermore, a graph instruction tuning stage is introduced to guide LLMs in solving graph reasoning and generation tasks. Finally, we identify potential hallucination problems in graph tasks and sample negative instances for preference alignment, the target of which is to enhance the output's reliability of the model. Extensive experiments across multiple graph-centric tasks exhibit that InstructGraph can achieve the best performance and outperform GPT-4 and LLaMA2 by more than 13\% and 38\%, respectively.
FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis
Jul 31, 2023



In this paper, we propose FinVis-GPT, a novel multimodal large language model (LLM) specifically designed for financial chart analysis. By leveraging the power of LLMs and incorporating instruction tuning and multimodal capabilities, FinVis-GPT is capable of interpreting financial charts and providing valuable analysis. To train FinVis-GPT, a financial task oriented dataset was generated for pre-training alignment and instruction tuning, comprising various types of financial charts and their corresponding descriptions. We evaluate the model performance via several case studies due to the time limit, and the promising results demonstrated that FinVis-GPT is superior in various financial chart related tasks, including generating descriptions, answering questions and predicting future market trends, surpassing existing state-of-the-art multimodal LLMs. The proposed FinVis-GPT serves as a pioneering effort in utilizing multimodal LLMs in the finance domain and our generated dataset will be release for public use in the near future to speedup related research.
An Effective Data Creation Pipeline to Generate High-quality Financial Instruction Data for Large Language Model
Jul 31, 2023



At the beginning era of large language model, it is quite critical to generate a high-quality financial dataset to fine-tune a large language model for financial related tasks. Thus, this paper presents a carefully designed data creation pipeline for this purpose. Particularly, we initiate a dialogue between an AI investor and financial expert using ChatGPT and incorporate the feedback of human financial experts, leading to the refinement of the dataset. This pipeline yielded a robust instruction tuning dataset comprised of 103k multi-turn chats. Extensive experiments have been conducted on this dataset to evaluate the model's performance by adopting an external GPT-4 as the judge. The promising experimental results verify that our approach led to significant advancements in generating accurate, relevant, and financial-style responses from AI models, and thus providing a powerful tool for applications within the financial sector.
InfoPrompt: Information-Theoretic Soft Prompt Tuning for Natural Language Understanding
Jun 08, 2023


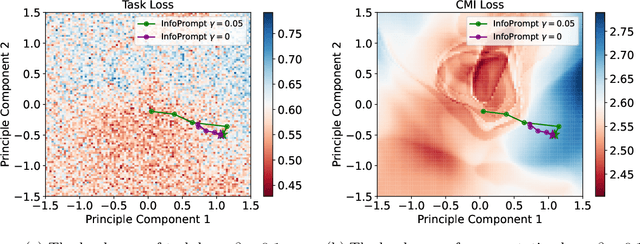
Soft prompt tuning achieves superior performances across a wide range of few-shot tasks. However, the performances of prompt tuning can be highly sensitive to the initialization of the prompts. We also empirically observe that conventional prompt tuning methods cannot encode and learn sufficient task-relevant information from prompt tokens. In this work, we develop an information-theoretic framework that formulates soft prompt tuning as maximizing mutual information between prompts and other model parameters (or encoded representations). This novel view helps us to develop a more efficient, accurate and robust soft prompt tuning method InfoPrompt. With this framework, we develop two novel mutual information based loss functions, to (i) discover proper prompt initialization for the downstream tasks and learn sufficient task-relevant information from prompt tokens and (ii) encourage the output representation from the pretrained language model to be more aware of the task-relevant information captured in the learnt prompt. Extensive experiments validate that InfoPrompt can significantly accelerate the convergence of the prompt tuning and outperform traditional prompt tuning methods. Finally, we provide a formal theoretical result for showing to show that gradient descent type algorithm can be used to train our mutual information loss.
Few-Shot Dialogue Summarization via Skeleton-Assisted Prompt Transfer
May 20, 2023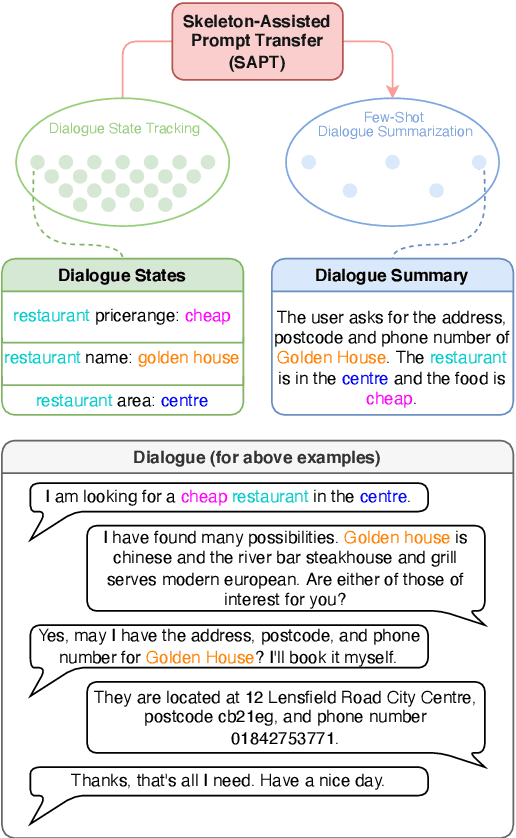

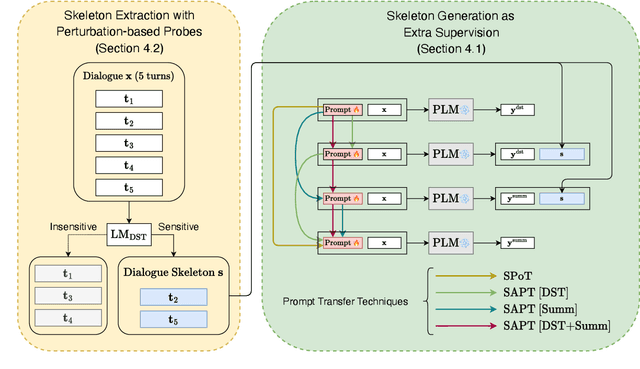
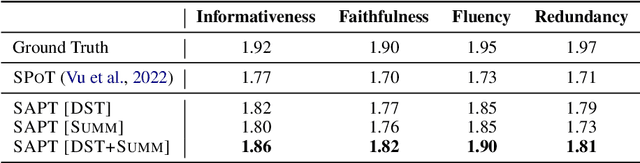
In real-world scenarios, labeled samples for dialogue summarization are usually limited (i.e., few-shot) due to high annotation costs for high-quality dialogue summaries. To efficiently learn from few-shot samples, previous works have utilized massive annotated data from other downstream tasks and then performed prompt transfer in prompt tuning so as to enable cross-task knowledge transfer. However, existing general-purpose prompt transfer techniques lack consideration for dialogue-specific information. In this paper, we focus on improving the prompt transfer from dialogue state tracking to dialogue summarization and propose Skeleton-Assisted Prompt Transfer (SAPT), which leverages skeleton generation as extra supervision that functions as a medium connecting the distinct source and target task and resulting in the model's better consumption of dialogue state information. To automatically extract dialogue skeletons as supervised training data for skeleton generation, we design a novel approach with perturbation-based probes requiring neither annotation effort nor domain knowledge. Training the model on such skeletons can also help preserve model capability during prompt transfer. Our method significantly outperforms existing baselines. In-depth analyses demonstrate the effectiveness of our method in facilitating cross-task knowledge transfer in few-shot dialogue summarization.