 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuqi Zhou
A Data-Driven Approach for High-Impedance Fault Localization in Distribution Systems
Nov 26, 2023
Accurate and quick identification of high-impedance faults is critical for the reliable operation of distribution systems. Unlike other faults in power grids, HIFs are very difficult to detect by conventional overcurrent relays due to the low fault current. Although HIFs can be affected by various factors, the voltage current characteristics can substantially imply how the system responds to the disturbance and thus provides opportunities to effectively localize HIFs. In this work, we propose a data-driven approach for the identification of HIF events. To tackle the nonlinearity of the voltage current trajectory, first, we formulate optimization problems to approximate the trajectory with piecewise functions. Then we collect the function features of all segments as inputs and use the support vector machine approach to efficiently identify HIFs at different locations. Numerical studies on the IEEE 123-node test feeder demonstrate the validity and accuracy of the proposed approach for real-time HIF identification.
LLMs may Dominate Information Access: Neural Retrievers are Biased Towards LLM-Generated Texts
Oct 31, 2023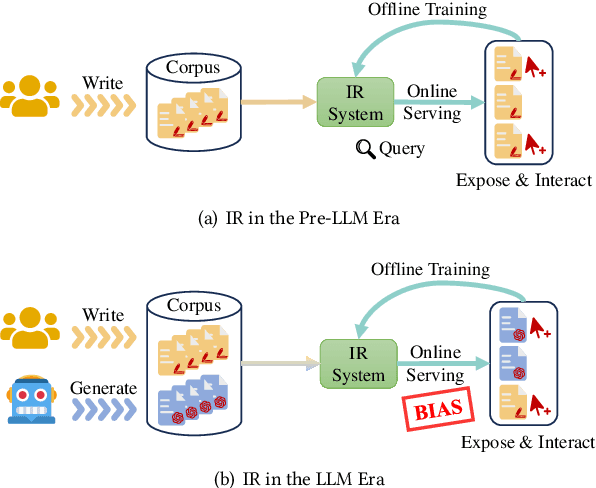
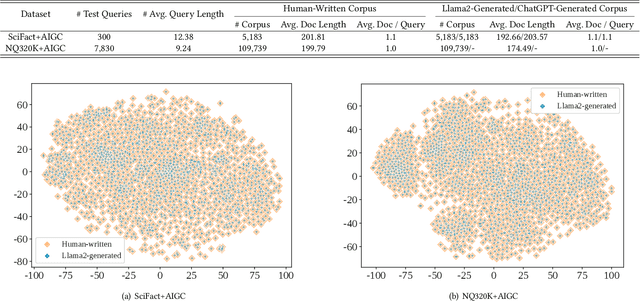
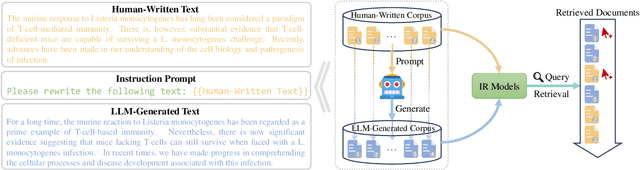
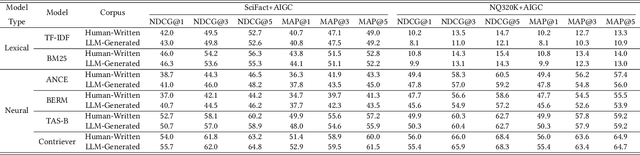
Recently, the emergence of large language models (LLMs) has revolutionized the paradigm of information retrieval (IR) applications, especially in web search. With their remarkable capabilities in generating human-like texts, LLMs have created enormous texts on the Internet. As a result, IR systems in the LLMs era are facing a new challenge: the indexed documents now are not only written by human beings but also automatically generated by the LLMs. How these LLM-generated documents influence the IR systems is a pressing and still unexplored question. In this work, we conduct a quantitative evaluation of different IR models in scenarios where both human-written and LLM-generated texts are involved. Surprisingly, our findings indicate that neural retrieval models tend to rank LLM-generated documents higher.We refer to this category of biases in neural retrieval models towards the LLM-generated text as the \textbf{source bias}. Moreover, we discover that this bias is not confined to the first-stage neural retrievers, but extends to the second-stage neural re-rankers. Then, we provide an in-depth analysis from the perspective of text compression and observe that neural models can better understand the semantic information of LLM-generated text, which is further substantiated by our theoretical analysis.We also discuss the potential server concerns stemming from the observed source bias and hope our findings can serve as a critical wake-up call to the IR community and beyond. To facilitate future explorations of IR in the LLM era, the constructed two new benchmarks and codes will later be available at \url{https://github.com/KID-22/LLM4IR-Bias}.
Complementary and Integrative Health Lexicon (CIHLex) and Entity Recognition in the Literature
May 27, 2023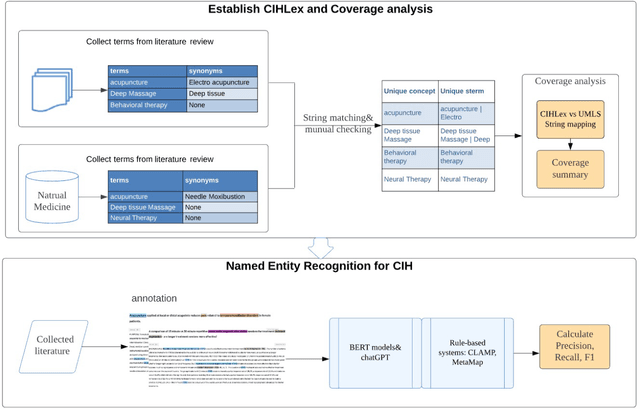
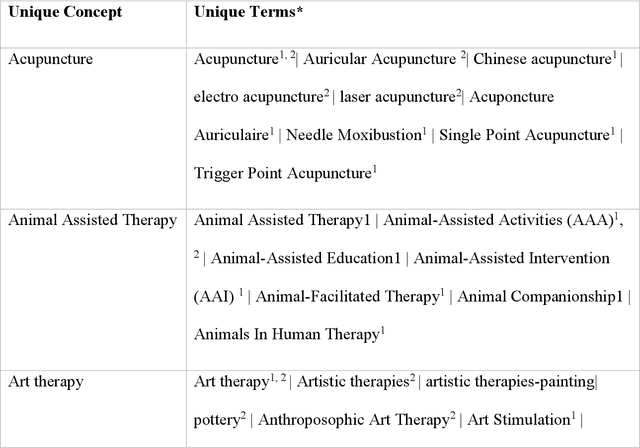


Objective: Our study aimed to construct an exhaustive Complementary and Integrative Health (CIH) Lexicon (CIHLex) to better represent the often underrepresented physical and psychological CIH approaches in standard terminologies. We also intended to apply advanced Natural Language Processing (NLP) models such as Bidirectional Encoder Representations from Transformers (BERT) and GPT-3.5 Turbo for CIH named entity recognition, evaluating their performance against established models like MetaMap and CLAMP. Materials and Methods: We constructed the CIHLex by integrating various resources, compiling and integrating data from biomedical literature and relevant knowledge bases. The Lexicon encompasses 198 unique concepts with 1090 corresponding unique terms. We matched these concepts to the Unified Medical Language System (UMLS). Additionally, we developed and utilized BERT models and compared their efficiency in CIH named entity recognition to that of other models such as MetaMap, CLAMP, and GPT3.5-turbo. Results: From the 198 unique concepts in CIHLex, 62.1% could be matched to at least one term in the UMLS. Moreover, 75.7% of the mapped UMLS Concept Unique Identifiers (CUIs) were categorized as "Therapeutic or Preventive Procedure." Among the models applied to CIH named entity recognition, BLUEBERT delivered the highest macro average F1-score of 0.90, surpassing other models. Conclusion: Our CIHLex significantly augments representation of CIH approaches in biomedical literature. Demonstrating the utility of advanced NLP models, BERT notably excelled in CIH entity recognition. These results highlight promising strategies for enhancing standardization and recognition of CIH terminology in biomedical contexts.
Appliance Level Short-term Load Forecasting via Recurrent Neural Network
Nov 23, 2021



Accurate load forecasting is critical for electricity market operations and other real-time decision-making tasks in power systems. This paper considers the short-term load forecasting (STLF) problem for residential customers within a community. Existing STLF work mainly focuses on forecasting the aggregated load for either a feeder system or a single customer, but few efforts have been made on forecasting the load at individual appliance level. In this work, we present an STLF algorithm for efficiently predicting the power consumption of individual electrical appliances. The proposed method builds upon a powerful recurrent neural network (RNN) architecture in deep learning, termed as long short-term memory (LSTM). As each appliance has uniquely repetitive consumption patterns, the patterns of prediction error will be tracked such that past prediction errors can be used for improving the final prediction performance. Numerical tests on real-world load datasets demonstrate the improvement of the proposed method over existing LSTM-based method and other benchmark approaches.
Scalable Learning for Optimal Load Shedding Under Power Grid Emergency Operations
Nov 23, 2021



Effective and timely responses to unexpected contingencies are crucial for enhancing the resilience of power grids. Given the fast, complex process of cascading propagation, corrective actions such as optimal load shedding (OLS) are difficult to attain in large-scale networks due to the computation complexity and communication latency issues. This work puts forth an innovative learning-for-OLS approach by constructing the optimal decision rules of load shedding under a variety of potential contingency scenarios through offline neural network (NN) training. Notably, the proposed NN-based OLS decisions are fully decentralized, enabling individual load centers to quickly react to the specific contingency using readily available local measurements. Numerical studies on the IEEE 14-bus system have demonstrated the effectiveness of our scalable OLS design for real-time responses to severe grid emergency events.
Discovering novel drug-supplement interactions using a dietary supplements knowledge graph generated from the biomedical literature
Jun 24, 2021



OBJECTIVE: Leverage existing biomedical NLP tools and DS domain terminology to produce a novel and comprehensive knowledge graph containing dietary supplement (DS) information for discovering interactions between DS and drugs, or Drug-Supplement Interactions (DSI). MATERIALS AND METHODS: We created SemRepDS (an extension of SemRep), capable of extracting semantic relations from abstracts by leveraging a DS-specific terminology (iDISK) containing 28,884 DS terms not found in the UMLS. PubMed abstracts were processed using SemRepDS to generate semantic relations, which were then filtered using a PubMedBERT-based model to remove incorrect relations before generating our knowledge graph (SuppKG). Two pathways are used to identify potential DS-Drug interactions which are then evaluated by medical professionals for mechanistic plausibility. RESULTS: Comparison analysis found that SemRepDS returned 206.9% more DS relations and 158.5% more DS entities than SemRep. The fine-tuned BERT model obtained an F1 score of 0.8605 and removed 43.86% of the relations, improving the precision of the relations by 26.4% compared to pre-filtering. SuppKG consists of 2,928 DS-specific nodes. Manual review of findings identified 44 (88%) proposed DS-Gene-Drug and 32 (64%) proposed DS-Gene1-Function-Gene2-Drug pathways to be mechanistically plausible. DISCUSSION: The additional relations extracted using SemRepDS generated SuppKG that was used to find plausible DSI not found in the current literature. By the nature of the SuppKG, these interactions are unlikely to have been found using SemRep without the expanded DS terminology. CONCLUSION: We successfully extend SemRep to include DS information and produce SuppKG which can be used to find potential DS-Drug interactions.
Social determinants of health in the era of artificial intelligence with electronic health records: A systematic review
Jan 22, 2021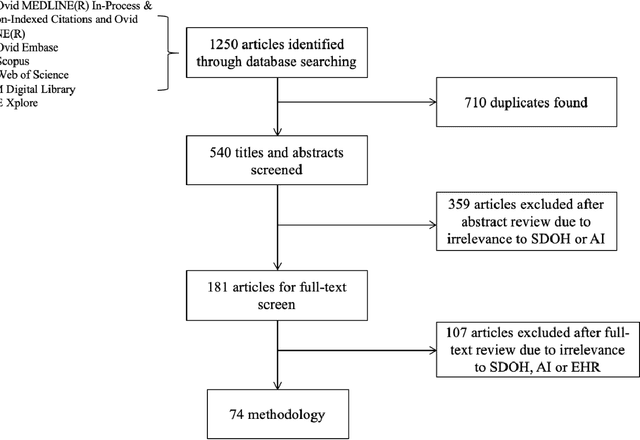
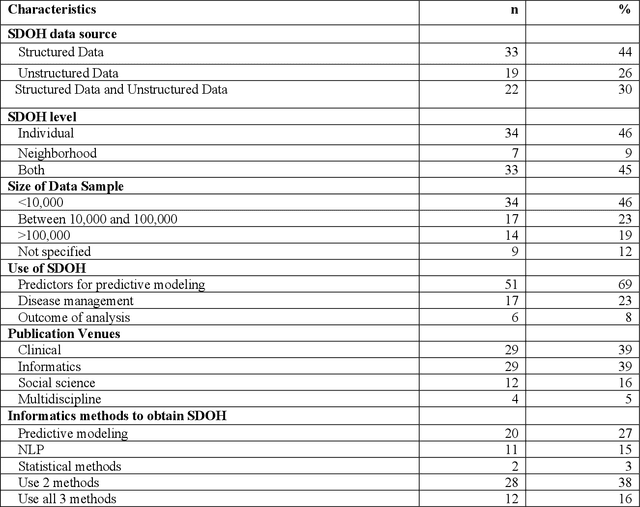
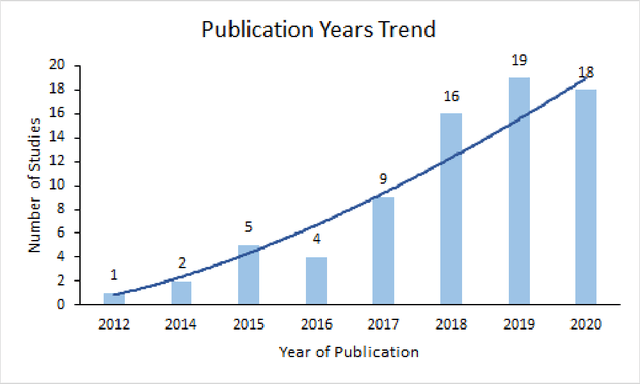

There is growing evidence showing the significant role of social determinant of health (SDOH) on a wide variety of health outcomes. In the era of artificial intelligence (AI), electronic health records (EHRs) have been widely used to conduct observational studies. However, how to make the best of SDOH information from EHRs is yet to be studied. In this paper, we systematically reviewed recently published papers and provided a methodology review of AI methods using the SDOH information in EHR data. A total of 1250 articles were retrieved from the literature between 2010 and 2020, and 74 papers were included in this review after abstract and full-text screening. We summarized these papers in terms of general characteristics (including publication years, venues, countries etc.), SDOH types, disease areas, study outcomes, AI methods to extract SDOH from EHRs and AI methods using SDOH for healthcare outcomes. Finally, we conclude this paper with discussion on the current trends, challenges, and future directions on using SDOH from EHRs.