 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxiao Chen
Versatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Apr 03, 2024
Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.
Categorical Traffic Transformer: Interpretable and Diverse Behavior Prediction with Tokenized Latent
Nov 30, 2023Adept traffic models are critical to both planning and closed-loop simulation for autonomous vehicles (AV), and key design objectives include accuracy, diverse multimodal behaviors, interpretability, and downstream compatibility. Recently, with the advent of large language models (LLMs), an additional desirable feature for traffic models is LLM compatibility. We present Categorical Traffic Transformer (CTT), a traffic model that outputs both continuous trajectory predictions and tokenized categorical predictions (lane modes, homotopies, etc.). The most outstanding feature of CTT is its fully interpretable latent space, which enables direct supervision of the latent variable from the ground truth during training and avoids mode collapse completely. As a result, CTT can generate diverse behaviors conditioned on different latent modes with semantic meanings while beating SOTA on prediction accuracy. In addition, CTT's ability to input and output tokens enables integration with LLMs for common-sense reasoning and zero-shot generalization.
Interactive Motion Planning for Autonomous Vehicles with Joint Optimization
Nov 02, 2023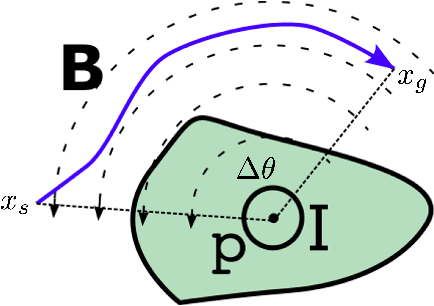
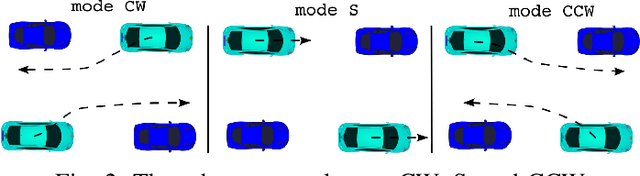

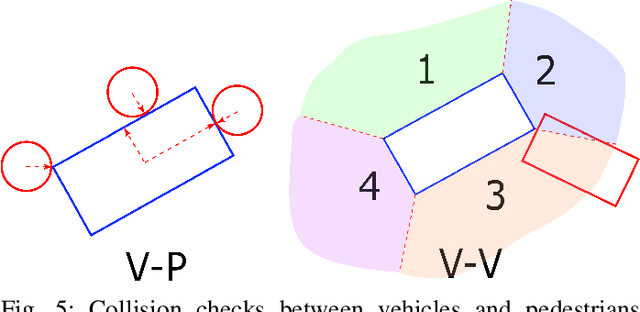
In highly interactive driving scenarios, the actions of one agent greatly influences those of its neighbors. Planning safe motions for autonomous vehicles in such interactive environments, therefore, requires reasoning about the impact of the ego's intended motion plan on nearby agents' behavior. Deep-learning-based models have recently achieved great success in trajectory prediction and many models in the literature allow for ego-conditioned prediction. However, leveraging ego-conditioned prediction remains challenging in downstream planning due to the complex nature of neural networks, limiting the planner structure to simple ones, e.g., sampling-based planner. Despite their ability to generate fine-grained high-quality motion plans, it is difficult for gradient-based planning algorithms, such as model predictive control (MPC), to leverage ego-conditioned prediction due to their iterative nature and need for gradient. We present Interactive Joint Planning (IJP) that bridges MPC with learned prediction models in a computationally scalable manner to provide us the best of both the worlds. In particular, IJP jointly optimizes over the behavior of the ego and the surrounding agents and leverages deep-learned prediction models as prediction priors that the join trajectory optimization tries to stay close to. Furthermore, by leveraging homotopy classes, our joint optimizer searches over diverse motion plans to avoid getting stuck at local minima. Closed-loop simulation result shows that IJP significantly outperforms the baselines that are either without joint optimization or running sampling-based planning.
DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving
Oct 09, 2023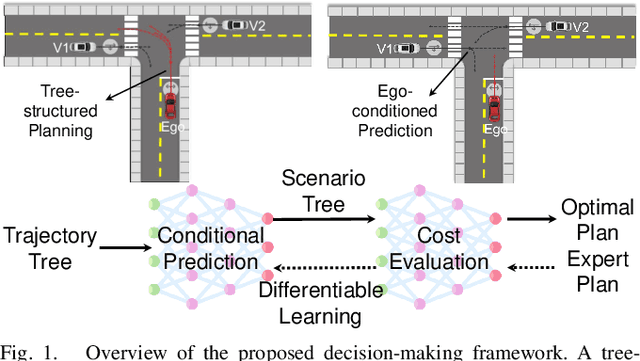
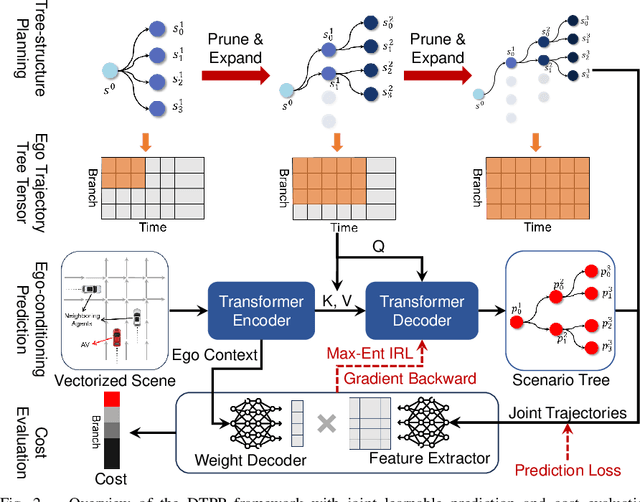

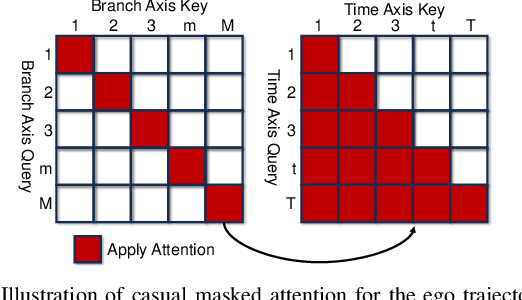
Motion prediction and cost evaluation are vital components in the decision-making system of autonomous vehicles. However, existing methods often ignore the importance of cost learning and treat them as separate modules. In this study, we employ a tree-structured policy planner and propose a differentiable joint training framework for both ego-conditioned prediction and cost models, resulting in a direct improvement of the final planning performance. For conditional prediction, we introduce a query-centric Transformer model that performs efficient ego-conditioned motion prediction. For planning cost, we propose a learnable context-aware cost function with latent interaction features, facilitating differentiable joint learning. We validate our proposed approach using the real-world nuPlan dataset and its associated planning test platform. Our framework not only matches state-of-the-art planning methods but outperforms other learning-based methods in planning quality, while operating more efficiently in terms of runtime. We show that joint training delivers significantly better performance than separate training of the two modules. Additionally, we find that tree-structured policy planning outperforms the conventional single-stage planning approach.
Refining Obstacle Perception Safety Zones via Maneuver-Based Decomposition
Aug 11, 2023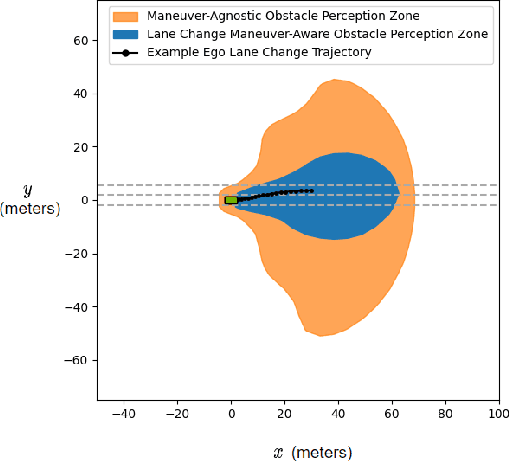
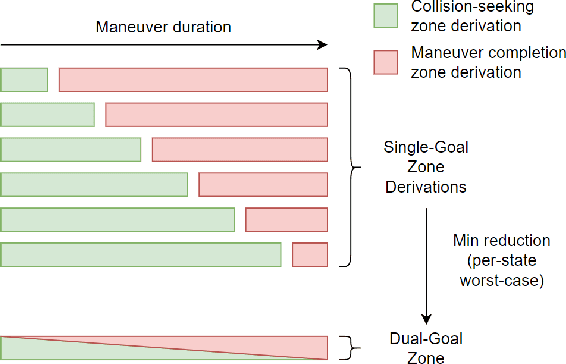
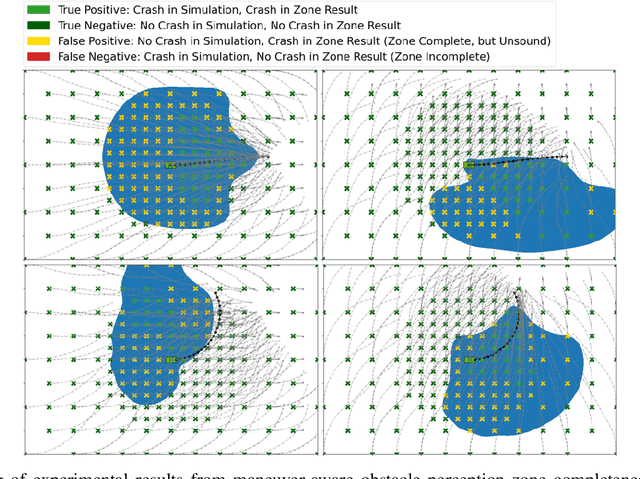
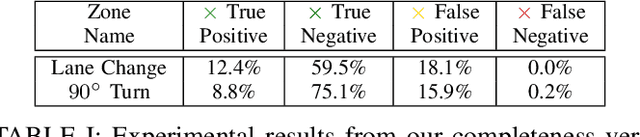
A critical task for developing safe autonomous driving stacks is to determine whether an obstacle is safety-critical, i.e., poses an imminent threat to the autonomous vehicle. Our previous work showed that Hamilton Jacobi reachability theory can be applied to compute interaction-dynamics-aware perception safety zones that better inform an ego vehicle's perception module which obstacles are considered safety-critical. For completeness, these zones are typically larger than absolutely necessary, forcing the perception module to pay attention to a larger collection of objects for the sake of conservatism. As an improvement, we propose a maneuver-based decomposition of our safety zones that leverages information about the ego maneuver to reduce the zone volume. In particular, we propose a "temporal convolution" operation that produces safety zones for specific ego maneuvers, thus limiting the ego's behavior to reduce the size of the safety zones. We show with numerical experiments that maneuver-based zones are significantly smaller (up to 76% size reduction) than the baseline while maintaining completeness.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023
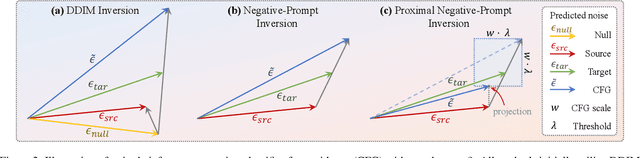
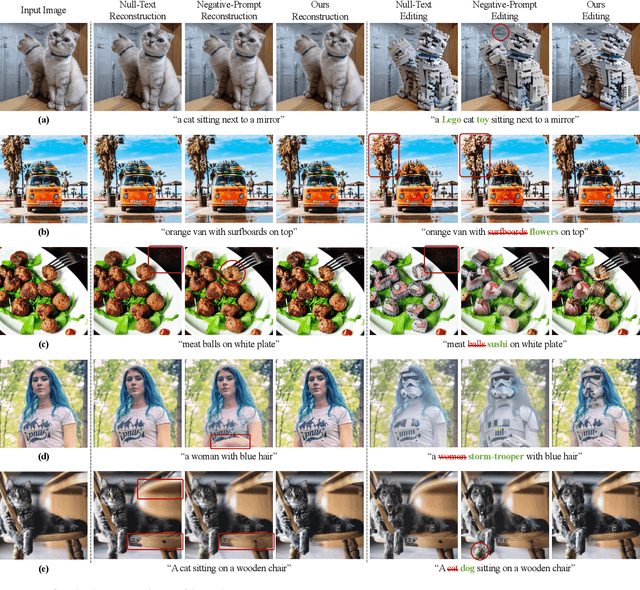

DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Language-Guided Traffic Simulation via Scene-Level Diffusion
Jun 10, 2023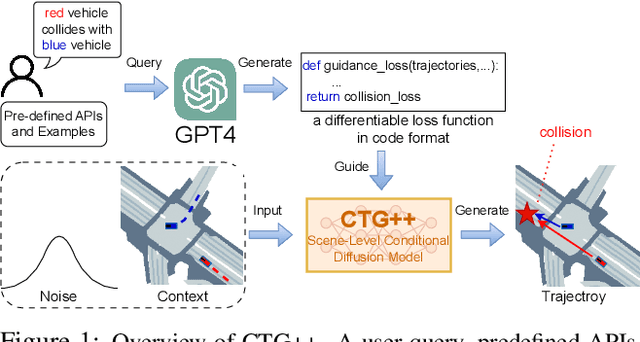

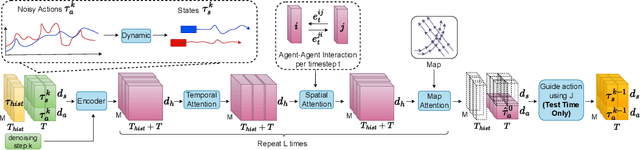
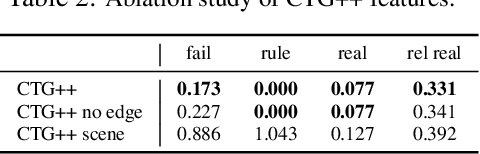
Realistic and controllable traffic simulation is a core capability that is necessary to accelerate autonomous vehicle (AV) development. However, current approaches for controlling learning-based traffic models require significant domain expertise and are difficult for practitioners to use. To remedy this, we present CTG++, a scene-level conditional diffusion model that can be guided by language instructions. Developing this requires tackling two challenges: the need for a realistic and controllable traffic model backbone, and an effective method to interface with a traffic model using language. To address these challenges, we first propose a scene-level diffusion model equipped with a spatio-temporal transformer backbone, which generates realistic and controllable traffic. We then harness a large language model (LLM) to convert a user's query into a loss function, guiding the diffusion model towards query-compliant generation. Through comprehensive evaluation, we demonstrate the effectiveness of our proposed method in generating realistic, query-compliant traffic simulations.
Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens
Mar 27, 2023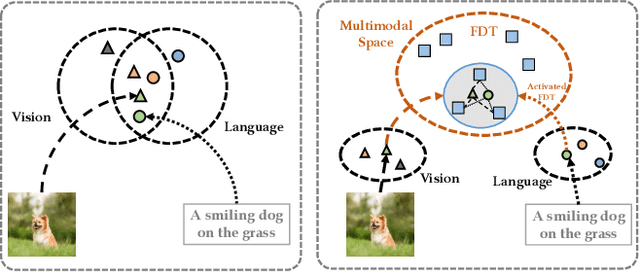

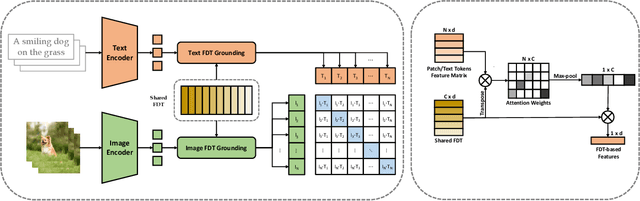
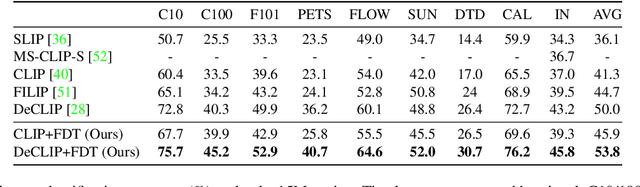
Contrastive learning-based vision-language pre-training approaches, such as CLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes.
Verification and Synthesis of Robust Control Barrier Functions: Multilevel Polynomial Optimization and Semidefinite Relaxation
Mar 17, 2023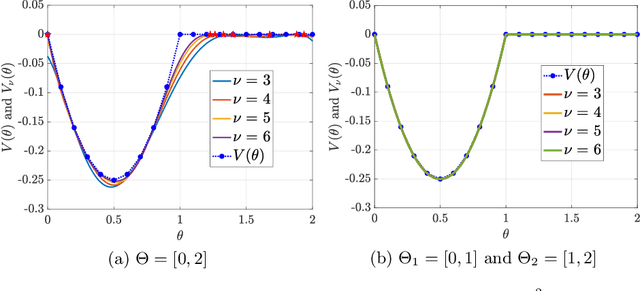

We study the problem of verification and synthesis of robust control barrier functions (CBF) for control-affine polynomial systems with bounded additive uncertainty and convex polynomial constraints on the control. We first formulate robust CBF verification and synthesis as multilevel polynomial optimization problems (POP), where verification optimizes -- in three levels -- the uncertainty, control, and state, while synthesis additionally optimizes the parameter of a chosen parametric CBF candidate. We then show that, by invoking the KKT conditions of the inner optimizations over uncertainty and control, the verification problem can be simplified as a single-level POP and the synthesis problem reduces to a min-max POP. This reduction leads to multilevel semidefinite relaxations. For the verification problem, we apply Lasserre's hierarchy of moment relaxations. For the synthesis problem, we draw connections to existing relaxation techniques for robust min-max POP, which first use sum-of-squares programming to find increasingly tight polynomial lower bounds to the unknown value function of the verification POP, and then call Lasserre's hierarchy again to maximize the lower bounds. Both semidefinite relaxations guarantee asymptotic global convergence to optimality. We provide an in-depth study of our framework on the controlled Van der Pol Oscillator, both with and without additive uncertainty.
HiCLIP: Contrastive Language-Image Pretraining with Hierarchy-aware Attention
Mar 06, 2023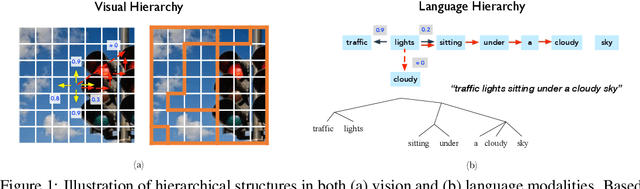
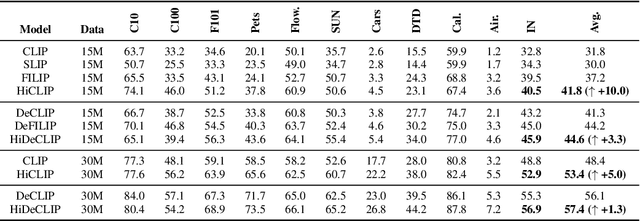
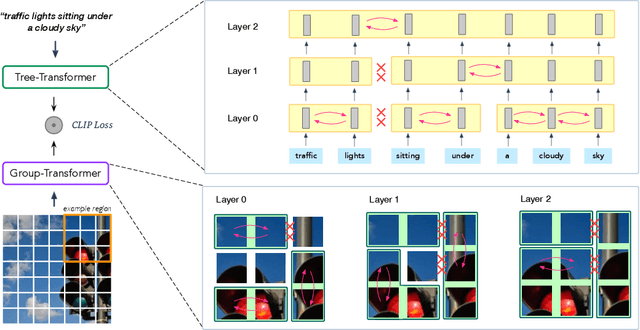
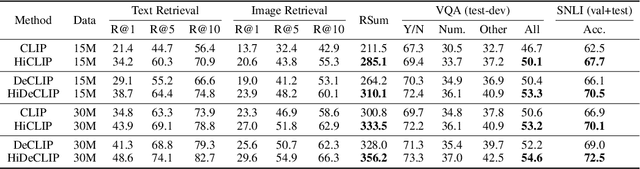
The success of large-scale contrastive vision-language pretraining (CLIP) has benefited both visual recognition and multimodal content understanding. The concise design brings CLIP the advantage in inference efficiency against other vision-language models with heavier cross-attention fusion layers, making it a popular choice for a wide spectrum of downstream tasks. However, CLIP does not explicitly capture the hierarchical nature of high-level and fine-grained semantics conveyed in images and texts, which is arguably critical to vision-language understanding and reasoning. To this end, we equip both the visual and language branches in CLIP with hierarchy-aware attentions, namely Hierarchy-aware CLIP (HiCLIP), to progressively discover semantic hierarchies layer-by-layer from both images and texts in an unsupervised manner. As a result, such hierarchical aggregation significantly improves the cross-modal alignment. To demonstrate the advantages of HiCLIP, we conduct qualitative analysis on its unsupervised hierarchy induction during inference, as well as extensive quantitative experiments on both visual recognition and vision-language downstream tasks.