 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZehua Wang
FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation
Jul 20, 2023
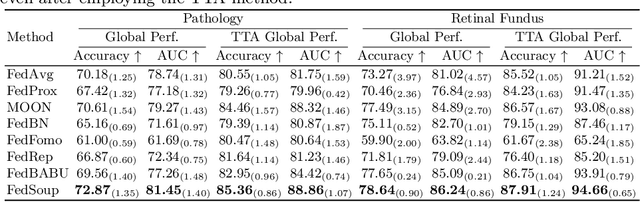
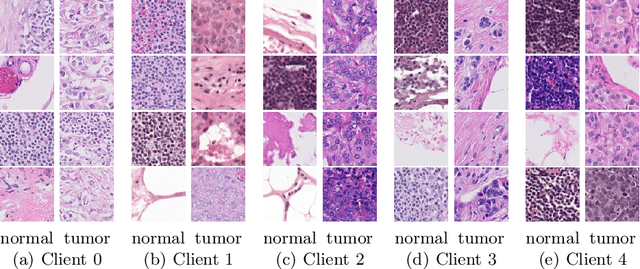
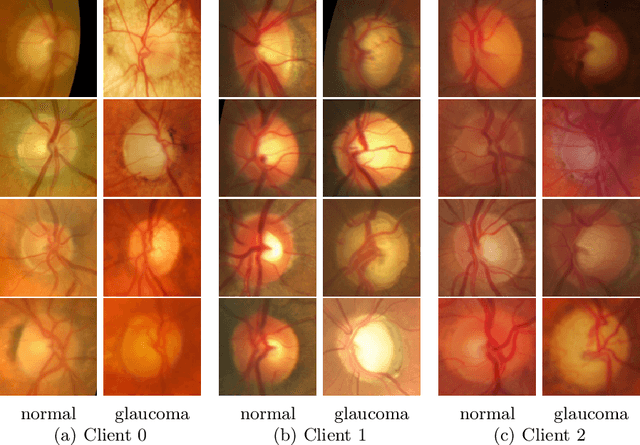
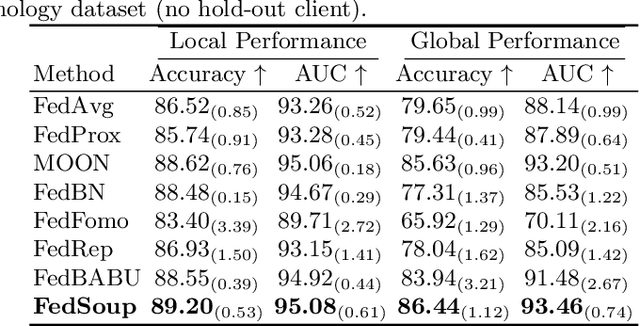
Cross-silo federated learning (FL) enables the development of machine learning models on datasets distributed across data centers such as hospitals and clinical research laboratories. However, recent research has found that current FL algorithms face a trade-off between local and global performance when confronted with distribution shifts. Specifically, personalized FL methods have a tendency to overfit to local data, leading to a sharp valley in the local model and inhibiting its ability to generalize to out-of-distribution data. In this paper, we propose a novel federated model soup method (i.e., selective interpolation of model parameters) to optimize the trade-off between local and global performance. Specifically, during the federated training phase, each client maintains its own global model pool by monitoring the performance of the interpolated model between the local and global models. This allows us to alleviate overfitting and seek flat minima, which can significantly improve the model's generalization performance. We evaluate our method on retinal and pathological image classification tasks, and our proposed method achieves significant improvements for out-of-distribution generalization. Our code is available at https://github.com/ubc-tea/FedSoup.
Low-code LLM: Visual Programming over LLMs
Apr 20, 2023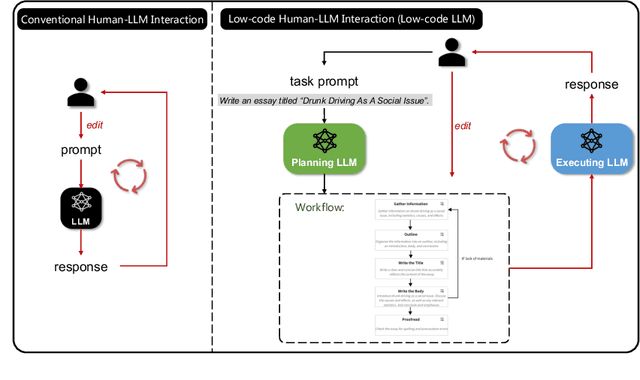
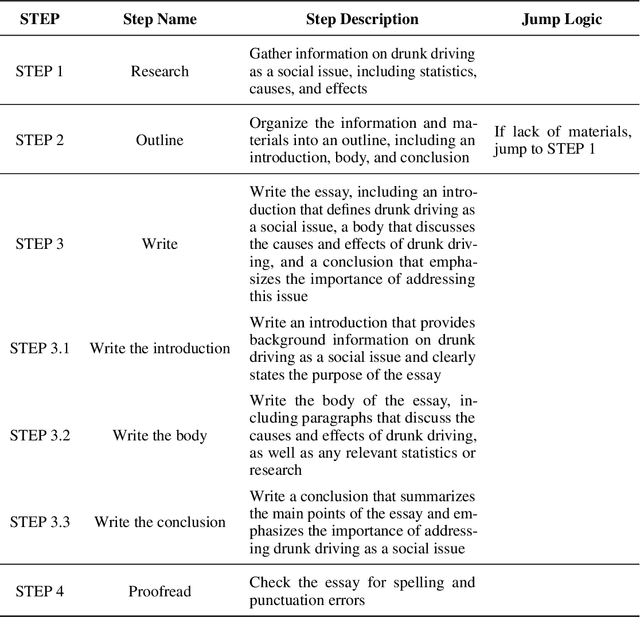
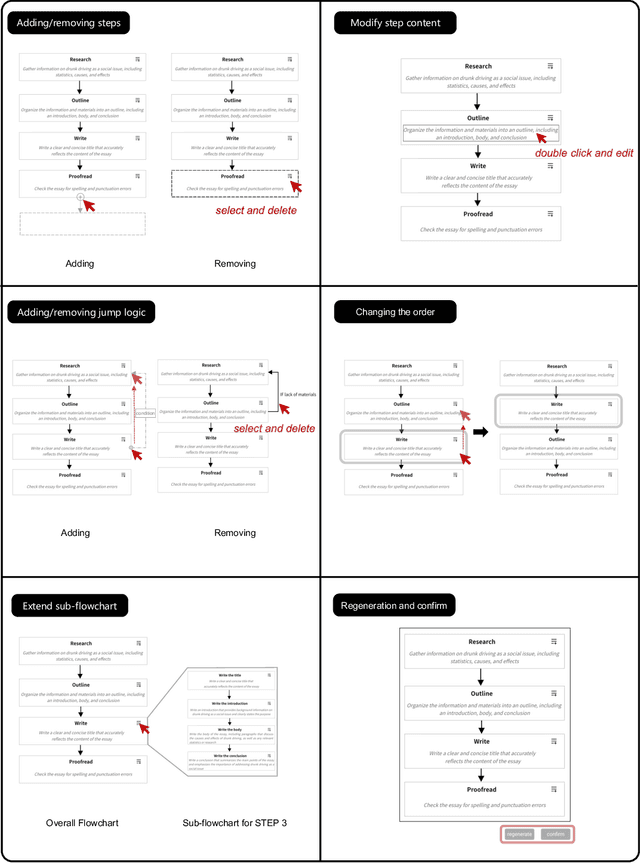

Effectively utilizing LLMs for complex tasks is challenging, often involving a time-consuming and uncontrollable prompt engineering process. This paper introduces a novel human-LLM interaction framework, Low-code LLM. It incorporates six types of simple low-code visual programming interactions, all supported by clicking, dragging, or text editing, to achieve more controllable and stable responses. Through visual interaction with a graphical user interface, users can incorporate their ideas into the workflow without writing trivial prompts. The proposed Low-code LLM framework consists of a Planning LLM that designs a structured planning workflow for complex tasks, which can be correspondingly edited and confirmed by users through low-code visual programming operations, and an Executing LLM that generates responses following the user-confirmed workflow. We highlight three advantages of the low-code LLM: controllable generation results, user-friendly human-LLM interaction, and broadly applicable scenarios. We demonstrate its benefits using four typical applications. By introducing this approach, we aim to bridge the gap between humans and LLMs, enabling more effective and efficient utilization of LLMs for complex tasks. Our system will be soon publicly available at LowCodeLLM.
Cervical Glandular Cell Detection from Whole Slide Image with Out-Of-Distribution Data
Jun 01, 2022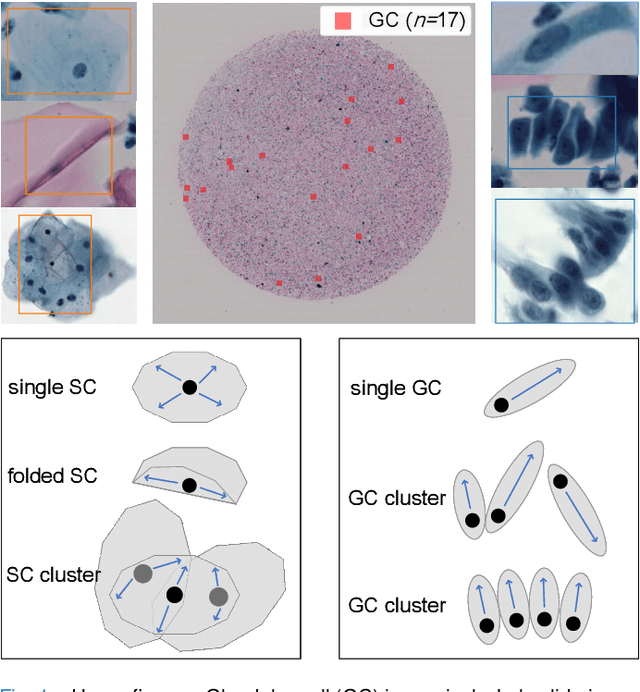

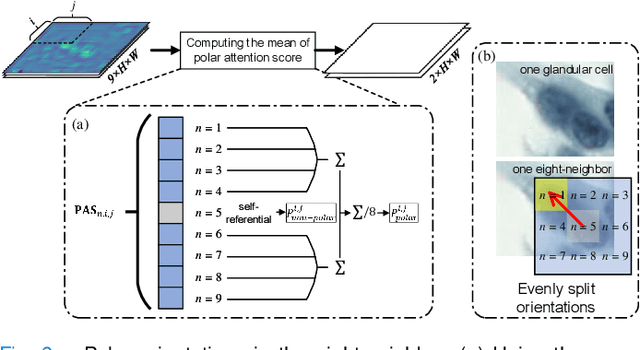
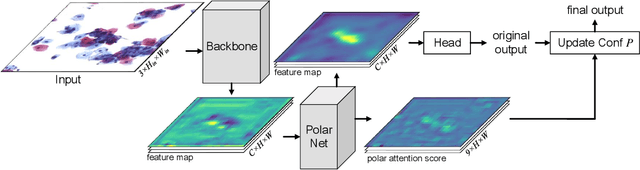
Cervical glandular cell (GC) detection is a key step in computer-aided diagnosis for cervical adenocarcinomas screening. It is challenging to accurately recognize GCs in cervical smears in which squamous cells are the major. Widely existing Out-Of-Distribution (OOD) data in the entire smear leads decreasing reliability of machine learning system for GC detection. Although, the State-Of-The-Art (SOTA) deep learning model can outperform pathologists in preselected regions of interest, the mass False Positive (FP) prediction with high probability is still unsolved when facing such gigapixel whole slide image. This paper proposed a novel PolarNet based on the morphological prior knowledge of GC trying to solve the FP problem via a self-attention mechanism in eight-neighbor. It estimates the polar orientation of nucleus of GC. As a plugin module, PolarNet can guide the deep feature and predicted confidence of general object detection models. In experiments, we discovered that general models based on four different frameworks can reject FP in small image set and increase the mean of average precision (mAP) by $\text{0.007}\sim\text{0.015}$ in average, where the highest exceeds the recent cervical cell detection model 0.037. By plugging PolarNet, the deployed C++ program improved by 8.8\% on accuracy of top-20 GC detection from external WSIs, while sacrificing 14.4 s of computational time. Code is available in https://github.com/Chrisa142857/PolarNet-GCdet
3D Dynamic Point Cloud Denoising via Spatial-Temporal Graph Learning
Apr 07, 2020
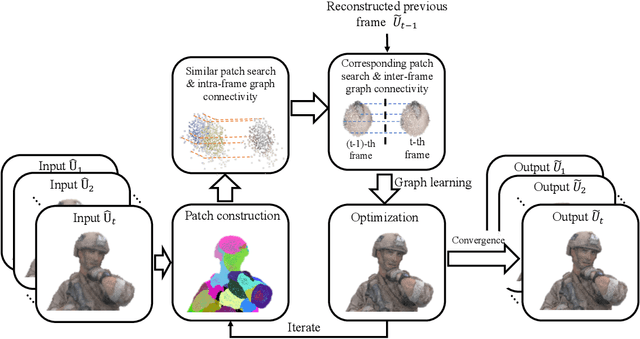
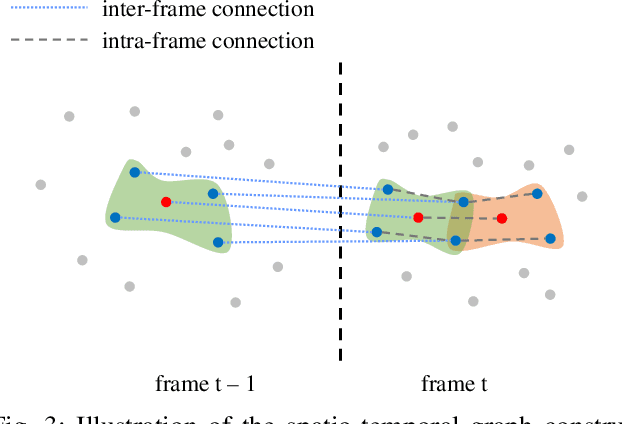
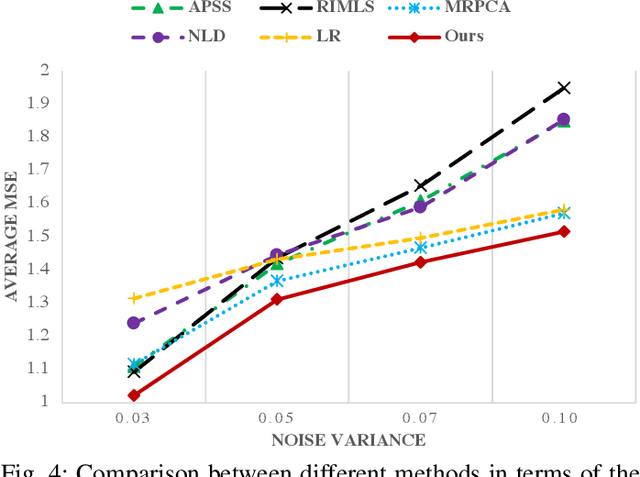
The prevalence of accessible depth sensing and 3D laser scanning techniques has enabled the convenient acquisition of 3D dynamic point clouds, which provide efficient representation of arbitrarily-shaped objects in motion. Nevertheless, dynamic point clouds are often perturbed by noise due to hardware, software or other causes. While a plethora of methods have been proposed for static point cloud denoising, few efforts are made for the denoising of dynamic point clouds with varying number of irregularly-sampled points in each frame. In this paper, we represent dynamic point clouds naturally on graphs and address the denoising problem by inferring the underlying graph via spatio-temporal graph learning, exploiting both the intra-frame similarity and inter-frame consistency. Firstly, assuming the availability of a relevant feature vector per node, we pose spatial-temporal graph learning as optimizing a Mahalanobis distance metric M, which is formulated as the minimization of graph Laplacian regularizer. Secondly, to ease the optimization of the symmetric and positive definite metric matrix M, we decompose it into M = R'*R and solve R instead via proximal gradient. Finally, based on the spatial-temporal graph learning, we formulate dynamic point cloud denoising as the joint optimization of the desired point cloud and underlying spatio-temporal graph, which leverages both intra-frame affinities and inter-frame consistency and is solved via alternating minimization. Experimental results show that the proposed method significantly outperforms independent denoising of each frame from state-of-the-art static point cloud denoising approaches.
3D Dynamic Point Cloud Denoising via Spatio-temporal Graph Modeling
Apr 28, 2019
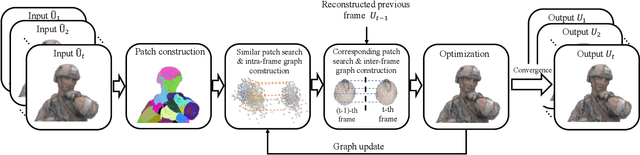
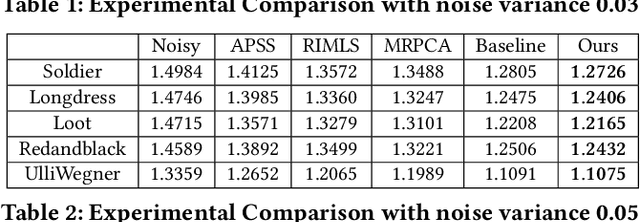
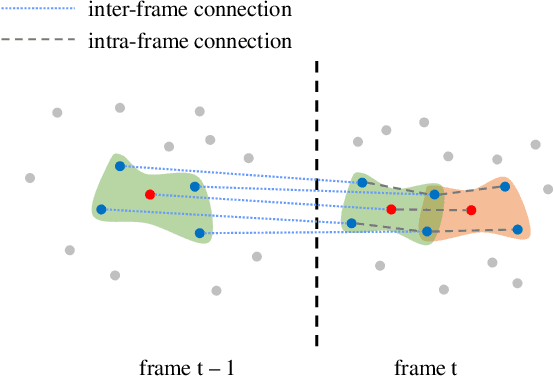
The prevalence of accessible depth sensing and 3D laser scanning techniques has enabled the convenient acquisition of 3D dynamic point clouds, which provide efficient representation of arbitrarily-shaped objects in motion. Nevertheless, dynamic point clouds are often perturbed by noise due to hardware, software or other causes. While many methods have been proposed for the denoising of static point clouds, dynamic point cloud denoising has not been studied in the literature yet. Hence, we address this problem based on the proposed spatio-temporal graph modeling, exploiting both the intra-frame similarity and inter-frame consistency. Specifically, we first represent a point cloud sequence on graphs and model it via spatio-temporal Gaussian Markov Random Fields on defined patches. Then for each target patch, we pose a Maximum a Posteriori estimation, and propose the corresponding likelihood and prior functions via spectral graph theory, leveraging its similar patches within the same frame and corresponding patch in the previous frame. This leads to our problem formulation, which jointly optimizes the underlying dynamic point cloud and spatio-temporal graph. Finally, we propose an efficient algorithm for patch construction, similar/corresponding patch search, intra- and inter-frame graph construction, and the optimization of our problem formulation via alternating minimization. Experimental results show that the proposed method outperforms frame-by-frame denoising from state-of-the-art static point cloud denoising approaches.