 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhang Yi
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 21, 2023
Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
Deep Dictionary Learning with An Intra-class Constraint
Jul 14, 2022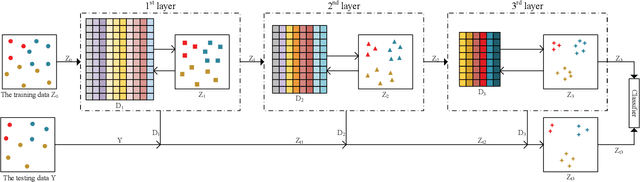
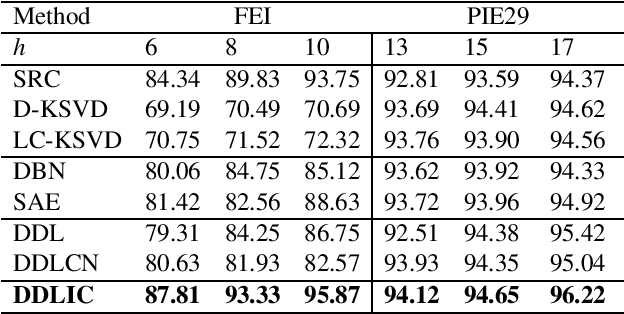
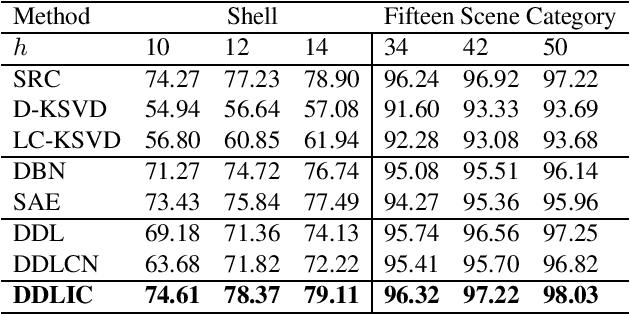
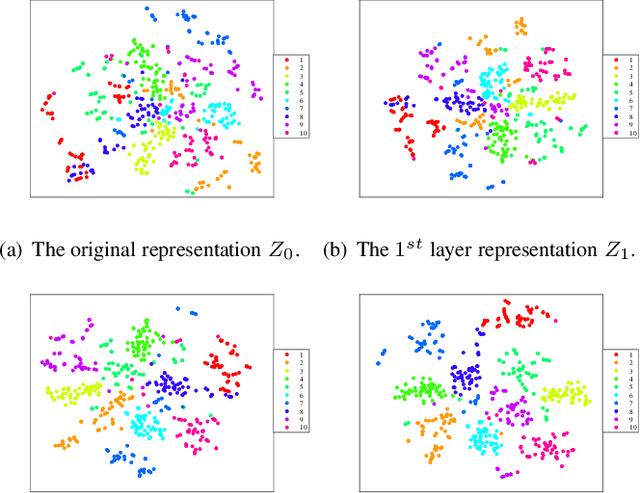
In recent years, deep dictionary learning (DDL)has attracted a great amount of attention due to its effectiveness for representation learning and visual recognition.~However, most existing methods focus on unsupervised deep dictionary learning, failing to further explore the category information.~To make full use of the category information of different samples, we propose a novel deep dictionary learning model with an intra-class constraint (DDLIC) for visual classification. Specifically, we design the intra-class compactness constraint on the intermediate representation at different levels to encourage the intra-class representations to be closer to each other, and eventually the learned representation becomes more discriminative.~Unlike the traditional DDL methods, during the classification stage, our DDLIC performs a layer-wise greedy optimization in a similar way to the training stage. Experimental results on four image datasets show that our method is superior to the state-of-the-art methods.
RegNet: Self-Regulated Network for Image Classification
Jan 03, 2021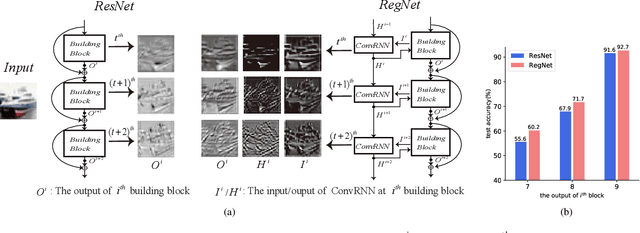
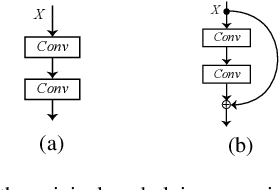
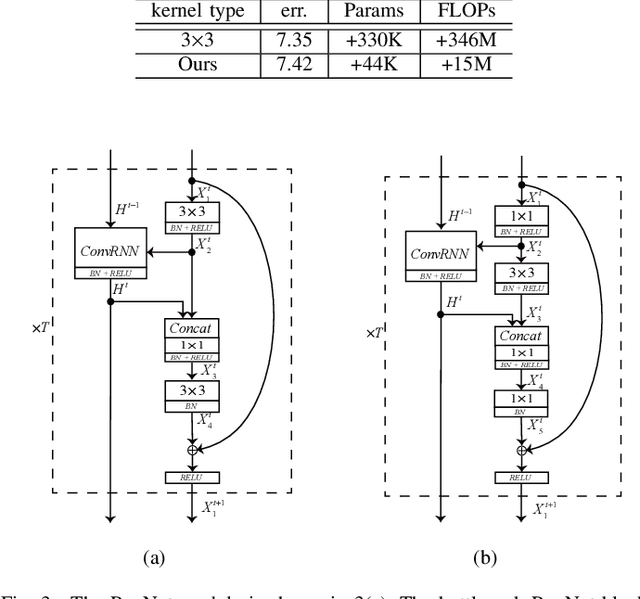
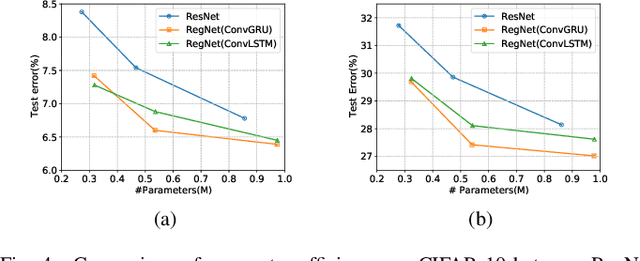
The ResNet and its variants have achieved remarkable successes in various computer vision tasks. Despite its success in making gradient flow through building blocks, the simple shortcut connection mechanism limits the ability of re-exploring new potentially complementary features due to the additive function. To address this issue, in this paper, we propose to introduce a regulator module as a memory mechanism to extract complementary features, which are further fed to the ResNet. In particular, the regulator module is composed of convolutional RNNs (e.g., Convolutional LSTMs or Convolutional GRUs), which are shown to be good at extracting Spatio-temporal information. We named the new regulated networks as RegNet. The regulator module can be easily implemented and appended to any ResNet architecture. We also apply the regulator module for improving the Squeeze-and-Excitation ResNet to show the generalization ability of our method. Experimental results on three image classification datasets have demonstrated the promising performance of the proposed architecture compared with the standard ResNet, SE-ResNet, and other state-of-the-art architectures.
IGD Indicator-based Evolutionary Algorithm for Many-objective Optimization Problems
Feb 24, 2018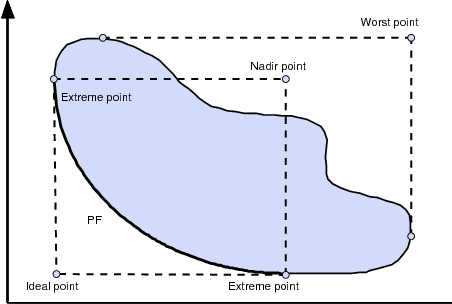
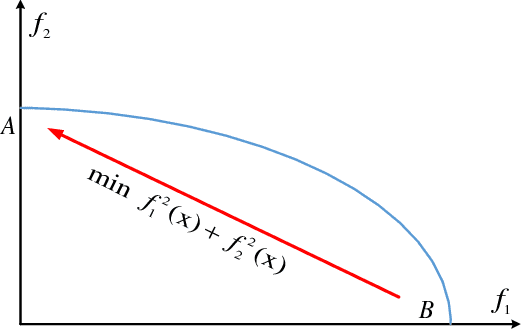
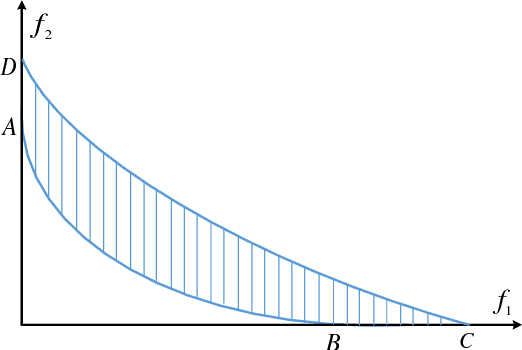
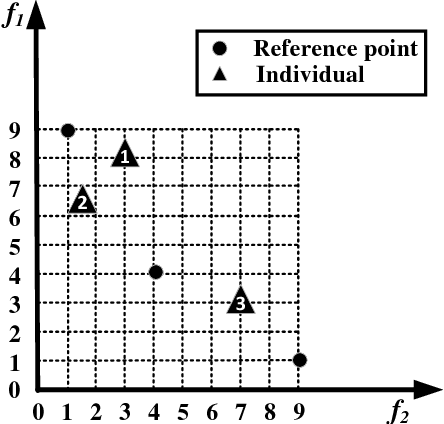
Inverted Generational Distance (IGD) has been widely considered as a reliable performance indicator to concurrently quantify the convergence and diversity of multi- and many-objective evolutionary algorithms. In this paper, an IGD indicator-based evolutionary algorithm for solving many-objective optimization problems (MaOPs) has been proposed. Specifically, the IGD indicator is employed in each generation to select the solutions with favorable convergence and diversity. In addition, a computationally efficient dominance comparison method is designed to assign the rank values of solutions along with three newly proposed proximity distance assignments. Based on these two designs, the solutions are selected from a global view by linear assignment mechanism to concern the convergence and diversity simultaneously. In order to facilitate the accuracy of the sampled reference points for the calculation of IGD indicator, we also propose an efficient decomposition-based nadir point estimation method for constructing the Utopian Pareto front which is regarded as the best approximate Pareto front for real-world MaOPs at the early stage of the evolution. To evaluate the performance, a series of experiments is performed on the proposed algorithm against a group of selected state-of-the-art many-objective optimization algorithms over optimization problems with $8$-, $15$-, and $20$-objective. Experimental results measured by the chosen performance metrics indicate that the proposed algorithm is very competitive in addressing MaOPs.
Improved Regularity Model-based EDA for Many-objective Optimization
Feb 24, 2018
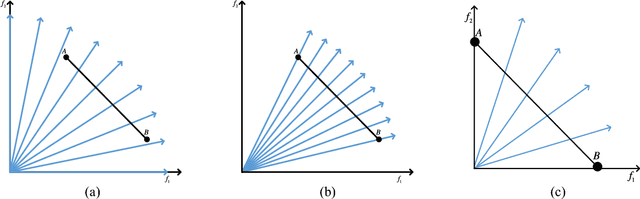
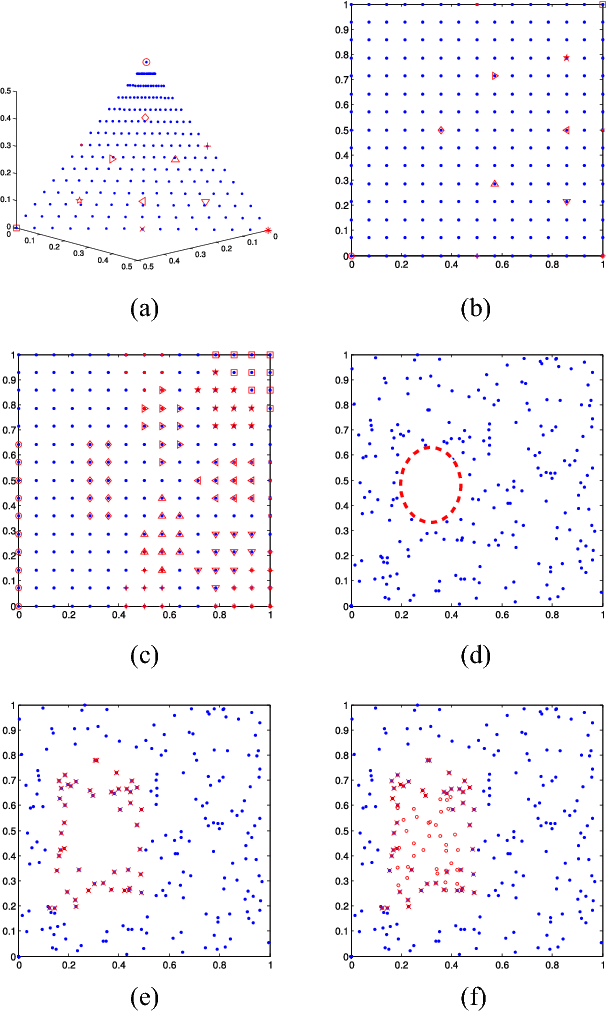
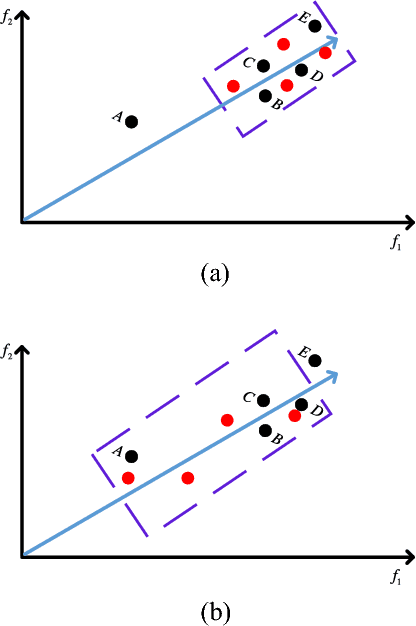
The performance of multi-objective evolutionary algorithms deteriorates appreciably in solving many-objective optimization problems which encompass more than three objectives. One of the known rationales is the loss of selection pressure which leads to the selected parents not generating promising offspring towards Pareto-optimal front with diversity. Estimation of distribution algorithms sample new solutions with a probabilistic model built from the statistics extracting over the existing solutions so as to mitigate the adverse impact of genetic operators. In this paper, an improved regularity-based estimation of distribution algorithm is proposed to effectively tackle unconstrained many-objective optimization problems. In the proposed algorithm, \emph{diversity repairing mechanism} is utilized to mend the areas where need non-dominated solutions with a closer proximity to the Pareto-optimal front. Then \emph{favorable solutions} are generated by the model built from the regularity of the solutions surrounding a group of representatives. These two steps collectively enhance the selection pressure which gives rise to the superior convergence of the proposed algorithm. In addition, dimension reduction technique is employed in the decision space to speed up the estimation search of the proposed algorithm. Finally, by assigning the Pareto-optimal solutions to the uniformly distributed reference vectors, a set of solutions with excellent diversity and convergence is obtained. To measure the performance, NSGA-III, GrEA, MOEA/D, HypE, MBN-EDA, and RM-MEDA are selected to perform comparison experiments over DTLZ and DTLZ$^-$ test suites with $3$-, $5$-, $8$-, $10$-, and $15$-objective. Experimental results quantified by the selected performance metrics reveal that the proposed algorithm shows considerable competitiveness in addressing unconstrained many-objective optimization problems.
Evolving Unsupervised Deep Neural Networks for Learning Meaningful Representations
Feb 24, 2018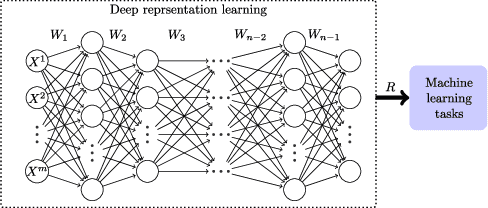
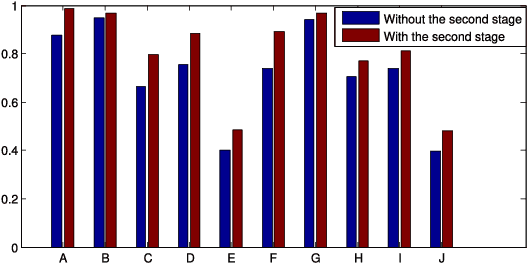

Deep Learning (DL) aims at learning the \emph{meaningful representations}. A meaningful representation refers to the one that gives rise to significant performance improvement of associated Machine Learning (ML) tasks by replacing the raw data as the input. However, optimal architecture design and model parameter estimation in DL algorithms are widely considered to be intractable. Evolutionary algorithms are much preferable for complex and non-convex problems due to its inherent characteristics of gradient-free and insensitivity to local optimum. In this paper, we propose a computationally economical algorithm for evolving \emph{unsupervised deep neural networks} to efficiently learn \emph{meaningful representations}, which is very suitable in the current Big Data era where sufficient labeled data for training is often expensive to acquire. In the proposed algorithm, finding an appropriate architecture and the initialized parameter values for a ML task at hand is modeled by one computational efficient gene encoding approach, which is employed to effectively model the task with a large number of parameters. In addition, a local search strategy is incorporated to facilitate the exploitation search for further improving the performance. Furthermore, a small proportion labeled data is utilized during evolution search to guarantee the learnt representations to be meaningful. The performance of the proposed algorithm has been thoroughly investigated over classification tasks. Specifically, error classification rate on MNIST with $1.15\%$ is reached by the proposed algorithm consistently, which is a very promising result against state-of-the-art unsupervised DL algorithms.
Deep Sparse Subspace Clustering
Sep 25, 2017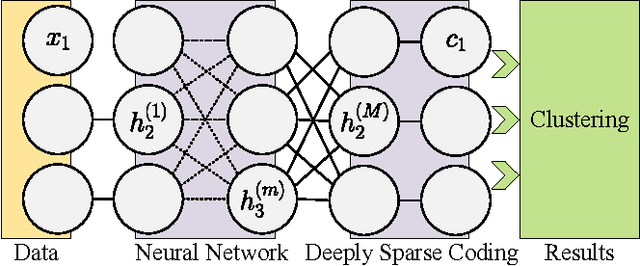
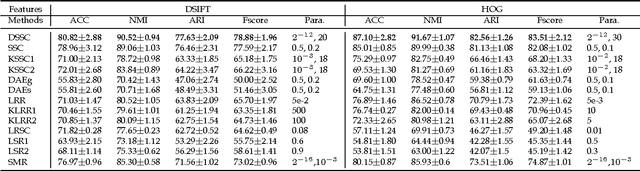
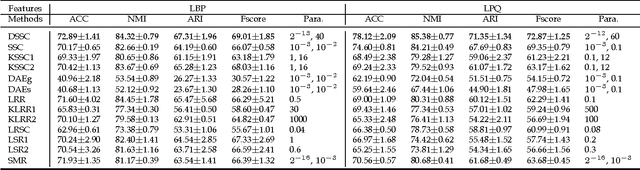
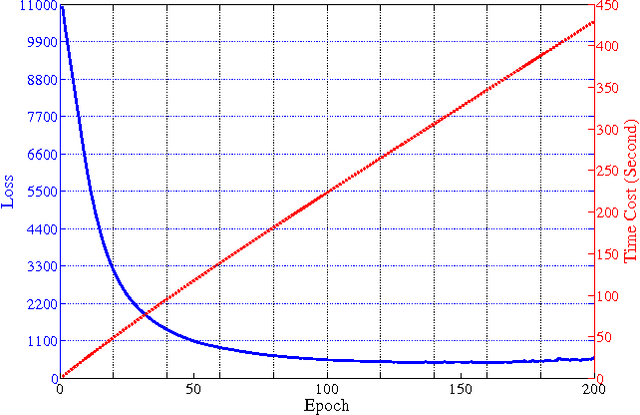
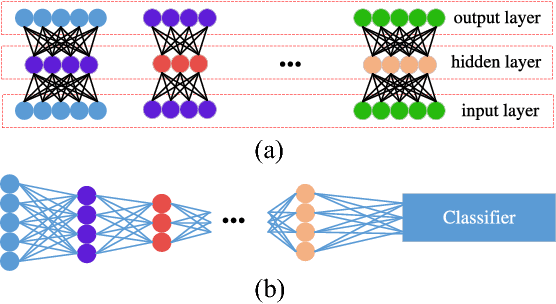
In this paper, we present a deep extension of Sparse Subspace Clustering, termed Deep Sparse Subspace Clustering (DSSC). Regularized by the unit sphere distribution assumption for the learned deep features, DSSC can infer a new data affinity matrix by simultaneously satisfying the sparsity principle of SSC and the nonlinearity given by neural networks. One of the appealing advantages brought by DSSC is: when original real-world data do not meet the class-specific linear subspace distribution assumption, DSSC can employ neural networks to make the assumption valid with its hierarchical nonlinear transformations. To the best of our knowledge, this is among the first deep learning based subspace clustering methods. Extensive experiments are conducted on four real-world datasets to show the proposed DSSC is significantly superior to 12 existing methods for subspace clustering.
Locally linear representation for image clustering
May 16, 2017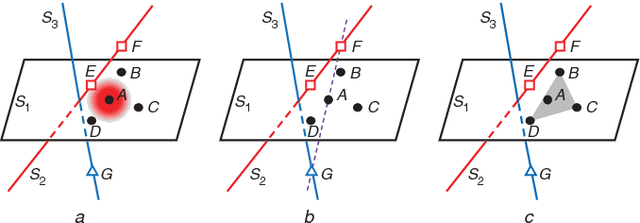
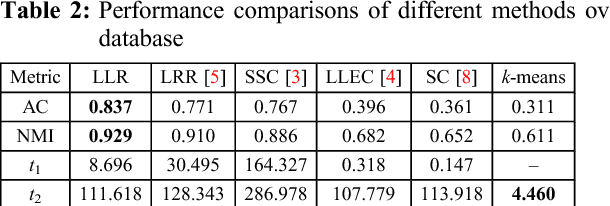
It is a key to construct a similarity graph in graph-oriented subspace learning and clustering. In a similarity graph, each vertex denotes a data point and the edge weight represents the similarity between two points. There are two popular schemes to construct a similarity graph, i.e., pairwise distance based scheme and linear representation based scheme. Most existing works have only involved one of the above schemes and suffered from some limitations. Specifically, pairwise distance based methods are sensitive to the noises and outliers compared with linear representation based methods. On the other hand, there is the possibility that linear representation based algorithms wrongly select inter-subspaces points to represent a point, which will degrade the performance. In this paper, we propose an algorithm, called Locally Linear Representation (LLR), which integrates pairwise distance with linear representation together to address the problems. The proposed algorithm can automatically encode each data point over a set of points that not only could denote the objective point with less residual error, but also are close to the point in Euclidean space. The experimental results show that our approach is promising in subspace learning and subspace clustering.
Subspace clustering using a symmetric low-rank representation
May 13, 2017
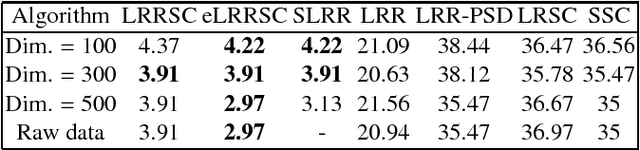
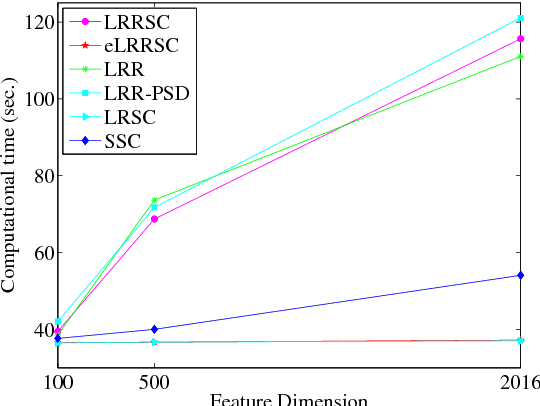
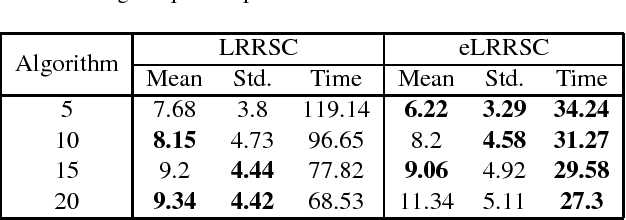
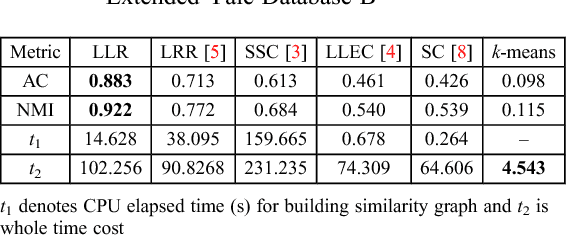
In this paper, we propose a low-rank representation with symmetric constraint (LRRSC) method for robust subspace clustering. Given a collection of data points approximately drawn from multiple subspaces, the proposed technique can simultaneously recover the dimension and members of each subspace. LRRSC extends the original low-rank representation algorithm by integrating a symmetric constraint into the low-rankness property of high-dimensional data representation. The symmetric low-rank representation, which preserves the subspace structures of high-dimensional data, guarantees weight consistency for each pair of data points so that highly correlated data points of subspaces are represented together. Moreover, it can be efficiently calculated by solving a convex optimization problem. We provide a rigorous proof for minimizing the nuclear-norm regularized least square problem with a symmetric constraint. The affinity matrix for spectral clustering can be obtained by further exploiting the angular information of the principal directions of the symmetric low-rank representation. This is a critical step towards evaluating the memberships between data points. Experimental results on benchmark databases demonstrate the effectiveness and robustness of LRRSC compared with several state-of-the-art subspace clustering algorithms.
Automatic Subspace Learning via Principal Coefficients Embedding
Oct 17, 2016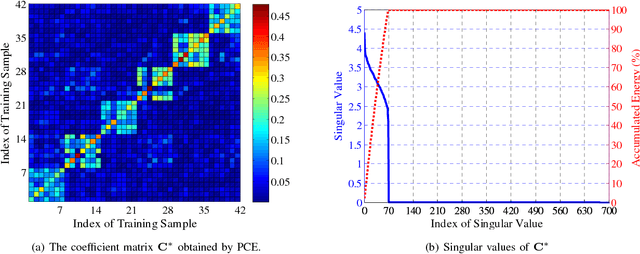
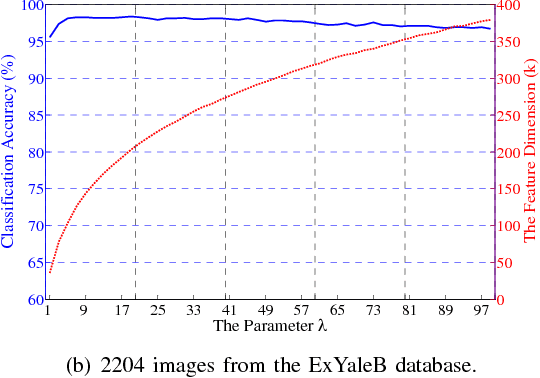
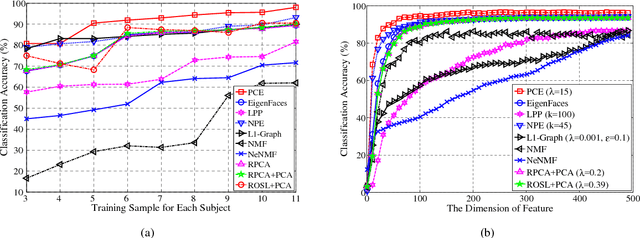

In this paper, we address two challenging problems in unsupervised subspace learning: 1) how to automatically identify the feature dimension of the learned subspace (i.e., automatic subspace learning), and 2) how to learn the underlying subspace in the presence of Gaussian noise (i.e., robust subspace learning). We show that these two problems can be simultaneously solved by proposing a new method (called principal coefficients embedding, PCE). For a given data set $\mathbf{D}\in \mathds{R}^{m\times n}$, PCE recovers a clean data set $\mathbf{D}_{0}\in \mathds{R}^{m\times n}$ from $\mathbf{D}$ and simultaneously learns a global reconstruction relation $\mathbf{C}\in \mathbf{R}^{n\times n}$ of $\mathbf{D}_{0}$. By preserving $\mathbf{C}$ into an $m^{\prime}$-dimensional space, the proposed method obtains a projection matrix that can capture the latent manifold structure of $\mathbf{D}_{0}$, where $m^{\prime}\ll m$ is automatically determined by the rank of $\mathbf{C}$ with theoretical guarantees. PCE has three advantages: 1) it can automatically determine the feature dimension even though data are sampled from a union of multiple linear subspaces in presence of the Gaussian noise, 2) Although the objective function of PCE only considers the Gaussian noise, experimental results show that it is robust to the non-Gaussian noise (\textit{e.g.}, random pixel corruption) and real disguises, 3) Our method has a closed-form solution and can be calculated very fast. Extensive experimental results show the superiority of PCE on a range of databases with respect to the classification accuracy, robustness and efficiency.
* IEEE Trans. on Cybernetics, 2016