 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Yan
Towards Long-term Autonomy: A Perspective from Robot Learning
Jan 02, 2023
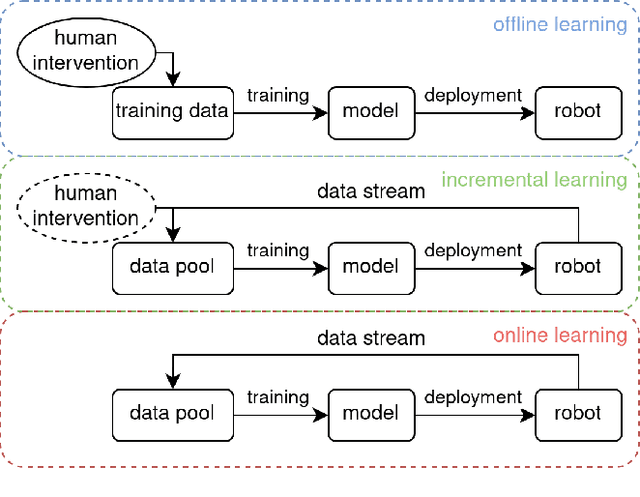
In the future, service robots are expected to be able to operate autonomously for long periods of time without human intervention. Many work striving for this goal have been emerging with the development of robotics, both hardware and software. Today we believe that an important underpinning of long-term robot autonomy is the ability of robots to learn on site and on-the-fly, especially when they are deployed in changing environments or need to traverse different environments. In this paper, we examine the problem of long-term autonomy from the perspective of robot learning, especially in an online way, and discuss in tandem its premise "data" and the subsequent "deployment".
Software-hardware Integration and Human-centered Benchmarking for Socially-compliant Robot Navigation
Oct 27, 2022
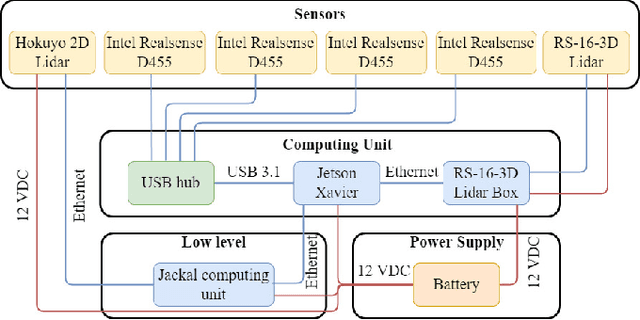

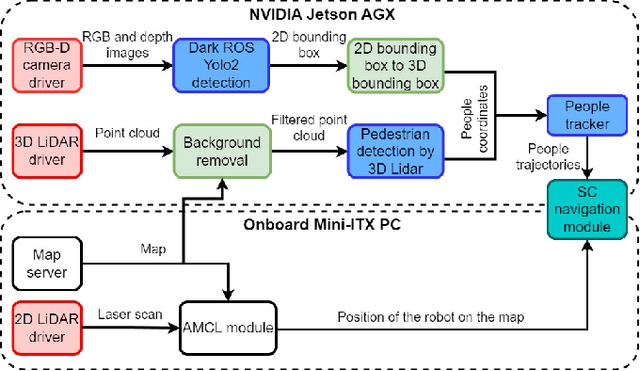
The social compatibility (SC) is one of the most important parameters for service robots. It characterises the interaction quality between a robot and a human. In this paper, we first introduce an open-source software-hardware integration scheme for socially-compliant robot navigation and then propose a human-centered benchmarking framework. For the former, we integrate one 3D lidar, one 2D lidar, and four RGB-D cameras for robot exterior perception. The software system is entirely based on the Robot Operating System (ROS) with high modularity and fully deployed to the embedded hardware-based edge while running at a rate that exceeds the release frequency of sensor data. For the latter, we propose a new human-centered performance evaluation metric that can be used to measure SC quickly and efficiently. The values of this metric correlate with the results of the Godspeed questionnaire, which is believed to be a golden standard approach for SC measurements. Together with other commonly used metrics, we benchmark two open-source socially-compliant robot navigation methods, in an end-to-end manner. We clarify all aspects of the benchmarking to ensure the reproducibility of the experiments. We also show that the proposed new metric can provide further justification for the selection of numerical metrics (objective) from a human perspective (subjective).
3D ToF LiDAR in Mobile Robotics: A Review
Feb 22, 2022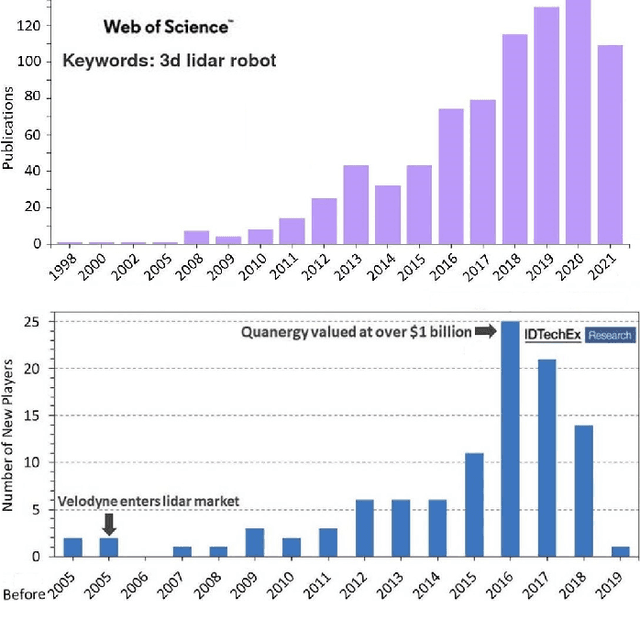

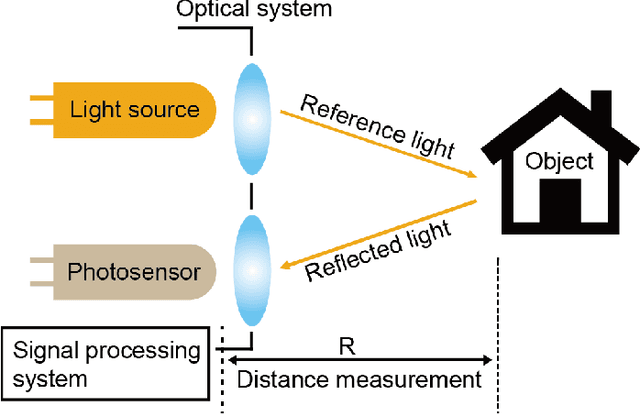
In the past ten years, the use of 3D Time-of-Flight (ToF) LiDARs in mobile robotics has grown rapidly. Based on our accumulation of relevant research, this article systematically reviews and analyzes the use 3D ToF LiDARs in research and industrial applications. The former includes object detection, robot localization, long-term autonomy, LiDAR data processing under adverse weather conditions, and sensor fusion. The latter encompasses service robots, assisted and autonomous driving, and recent applications performed in response to public health crises. We hope that our efforts can effectively provide readers with relevant references and promote the deployment of existing mature technologies in real-world systems.
Efficient Online Transfer Learning for 3D Object Classification in Autonomous Driving
May 04, 2021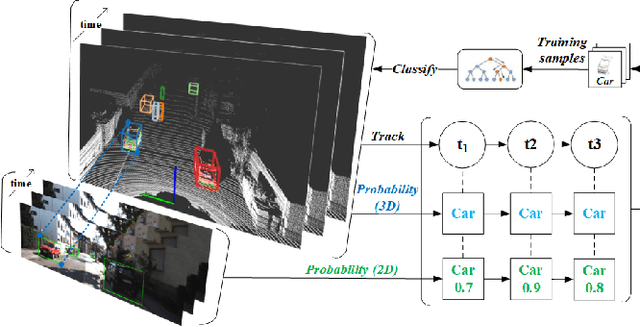
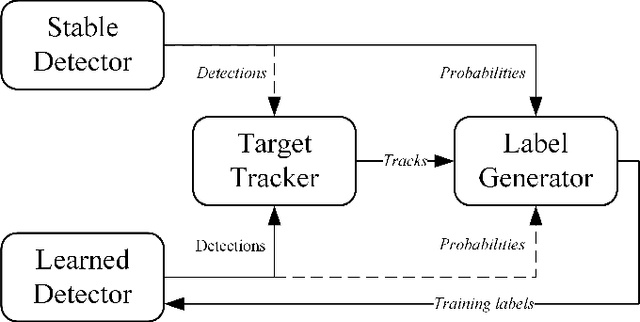
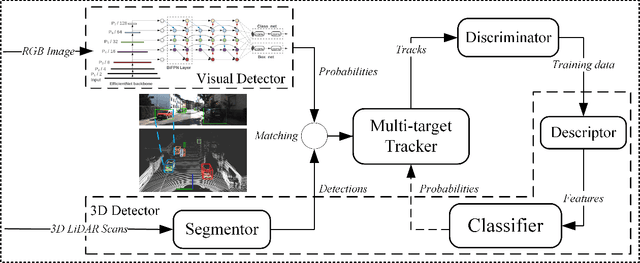

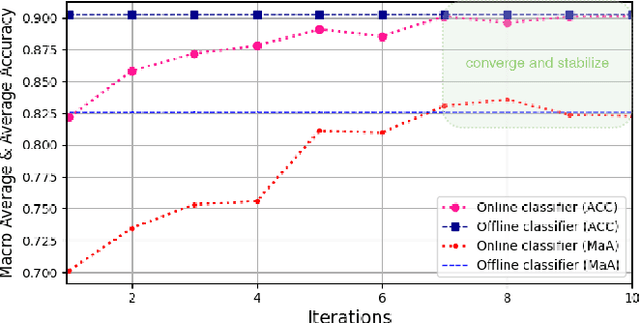
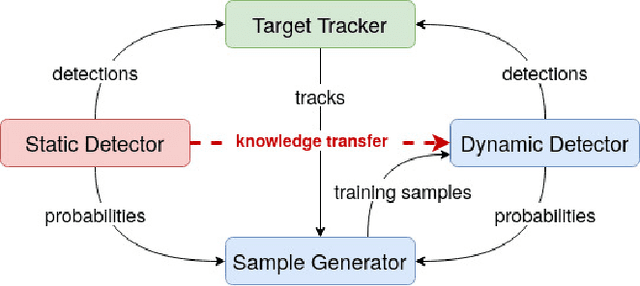
Autonomous driving has achieved rapid development over the last few decades, including the machine perception as an important issue of it. Although object detection based on conventional cameras has achieved remarkable results in 2D/3D, non-visual sensors such as 3D LiDAR still have incomparable advantages in the accuracy of object position detection. However, the challenge also exists with the difficulty in properly interpreting point cloud generated by LiDAR. This paper presents a multi-modal-based online learning system for 3D LiDAR-based object classification in urban environments, including cars, cyclists and pedestrians. The proposed system aims to effectively transfer the mature detection capabilities based on visual sensors to the new model learning based on non-visual sensors through a multi-target tracker (i.e. using one sensor to train another). In particular, it integrates the Online Random Forests (ORF) \cite{saffari2009line} method, which inherently has the abilities of fast and multi-class learning. Through experiments, we show that our system is capable of learning a high-performance model for LiDAR-based 3D object classification on-the-fly, which is especially suitable for robotics in-situ deployment while responding to the widespread challenge of insufficient detector generalization capabilities.
Time-of-Flight LiDAR-based Precise Mapping
Sep 21, 2020Last two decades, the problem of robotic mapping has made a lot of progress in the research community. However, since the data provided by the sensor still contains noise, how to obtain an accurate map is still an open problem. In this note, we analyze the problem from the perspective of mathematical analysis and propose a probabilistic map update method based on multiple explorations. The proposed method can help us estimate the number of rounds of robot exploration, which is meaningful for the hardware and time costs of the task.
Robot Perception of Static and Dynamic Objects with an Autonomous Floor Scrubber
Feb 24, 2020

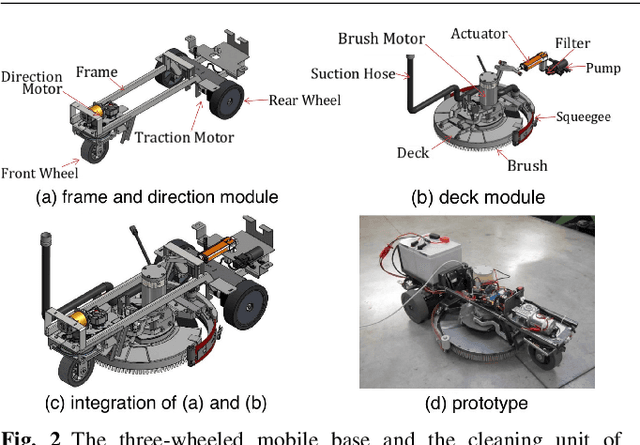
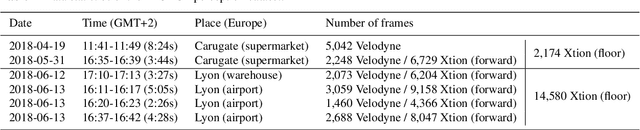
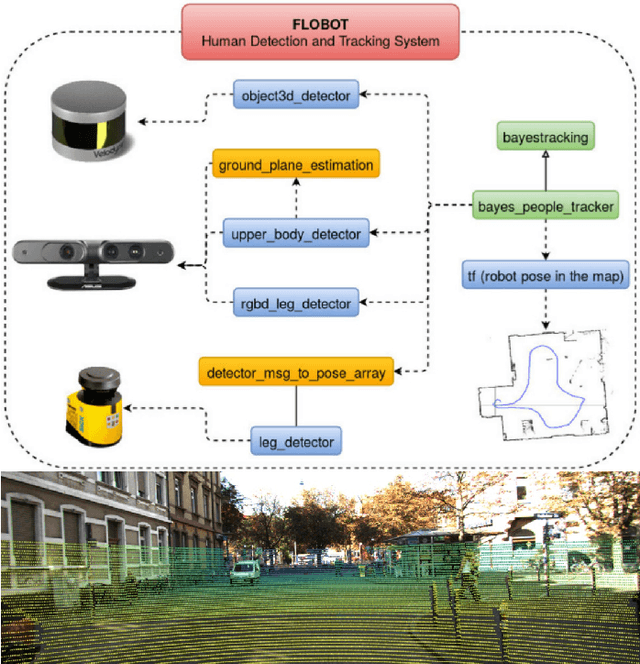
This paper presents the perception system of a new professional cleaning robot for large public places. The proposed system is based on multiple sensors including 3D and 2D lidar, two RGB-D cameras and a stereo camera. The two lidars together with an RGB-D camera are used for dynamic object (human) detection and tracking, while the second RGB-D and stereo camera are used for detection of static objects (dirt and ground objects). A learning and reasoning module for spatial-temporal representation of the environment based on the perception pipeline is also introduced. Furthermore, a new dataset collected with the robot in several public places, including a supermarket, a warehouse and an airport, is released. Baseline results on this dataset for further research and comparison are provided. The proposed system has been fully implemented into the Robot Operating System (ROS) with high modularity, also publicly available to the community.
EU Long-term Dataset with Multiple Sensors for Autonomous Driving
Sep 07, 2019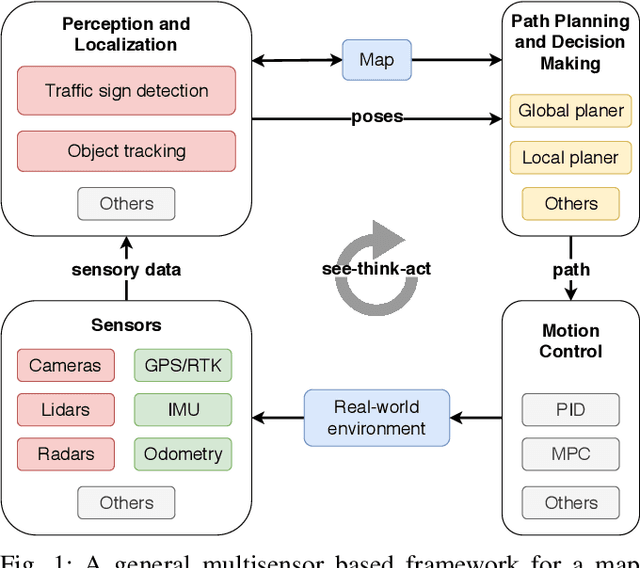

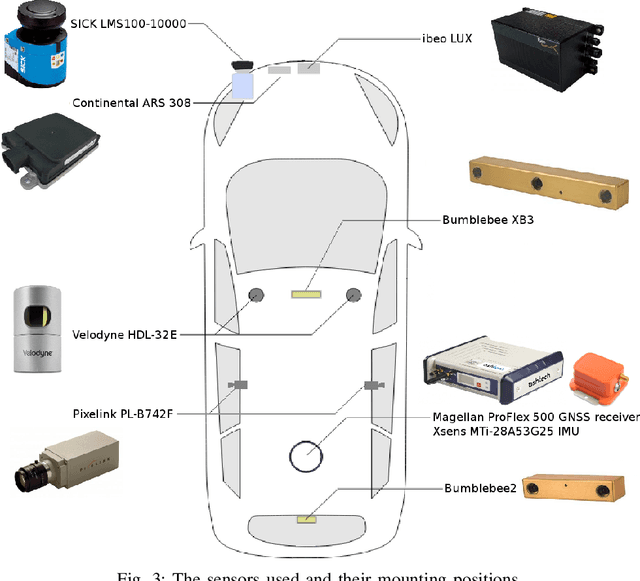
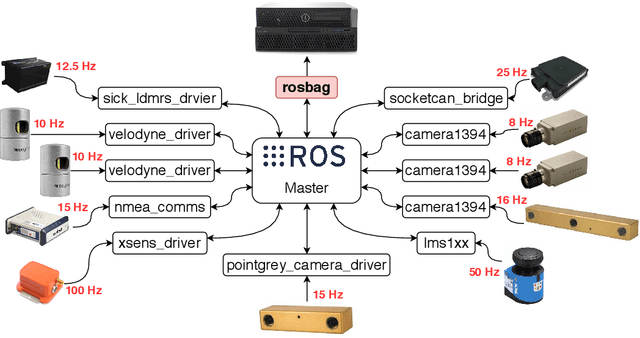
The field of autonomous driving has grown tremendously over the past few years, along with the rapid progress in sensor technology. One of the major purposes of using sensors is to provide environment perception for vehicle understanding, learning and reasoning, and ultimately interacting with the environment. In this article, we introduce a multisensor framework allowing vehicle to perceive its surroundings and locate itself in a more efficient and accurate way. Our framework integrates up to eleven heterogeneous sensors including various cameras and lidars, a radar, an IMU (Inertial Measurement Unit), and a GPS/RTK (Global Positioning System / Real-Time Kinematic), while exploits a ROS (Robot Operating System) based software to process the sensory data. In addition, we present a new dataset (https://epan-utbm.github.io/utbm_robocar_dataset/) for autonomous driving captured many new research challenges (e.g. highly dynamic environment), and especially for long-term autonomy (e.g. creating and maintaining maps), collected with our instrumented vehicle, publicly available to the community.
EPANer Team Description Paper for World Robot Challenge 2020
Sep 05, 2019
This paper presents the research focus and ideas incorporated in the EPANer robotics team, entering the World Robot Challenge 2020 - Partner Robot Challenge (Real Space).
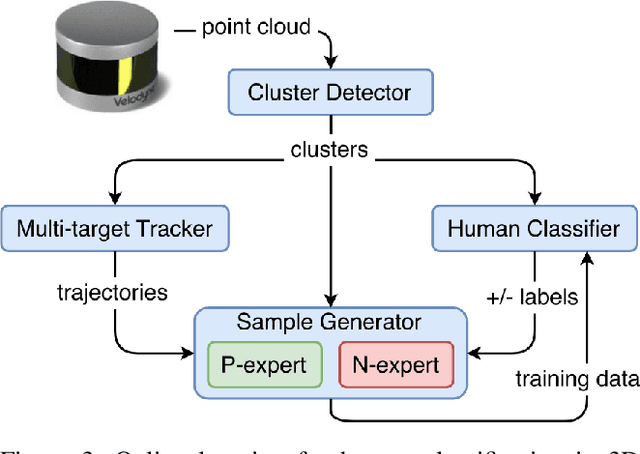
Multisensor Online Transfer Learning for 3D LiDAR-based Human Detection with a Mobile Robot
Jul 31, 2018
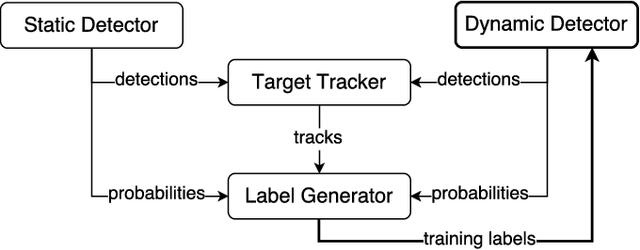
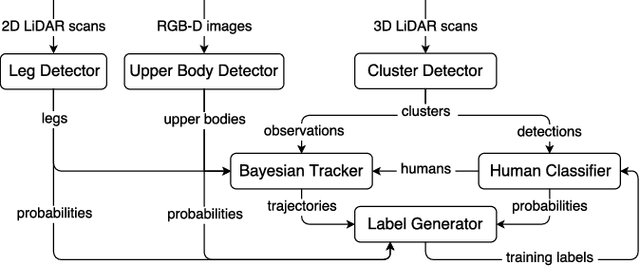

Human detection and tracking is an essential task for service robots, where the combined use of multiple sensors has potential advantages that are yet to be exploited. In this paper, we introduce a framework allowing a robot to learn a new 3D LiDAR-based human classifier from other sensors over time, taking advantage of a multisensor tracking system. The main innovation is the use of different detectors for existing sensors (i.e. RGB-D camera, 2D LiDAR) to train, online, a new 3D LiDAR-based human classifier, exploiting a so-called trajectory probability. Our framework uses this probability to check whether new detections belongs to a human trajectory, estimated by different sensors and/or detectors, and to learn a human classifier in a semi-supervised fashion. The framework has been implemented and tested on a real-world dataset collected by a mobile robot. We present experiments illustrating that our system is able to effectively learn from different sensors and from the environment, and that the performance of the 3D LiDAR-based human classification improves with the number of sensors/detectors used.
Recurrent-OctoMap: Learning State-based Map Refinement for Long-Term Semantic Mapping with 3D-Lidar Data
Jul 29, 2018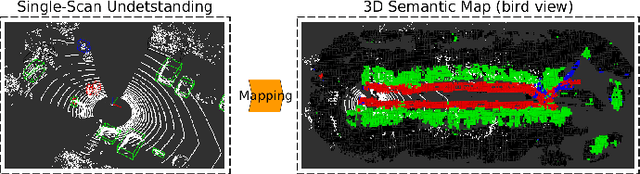

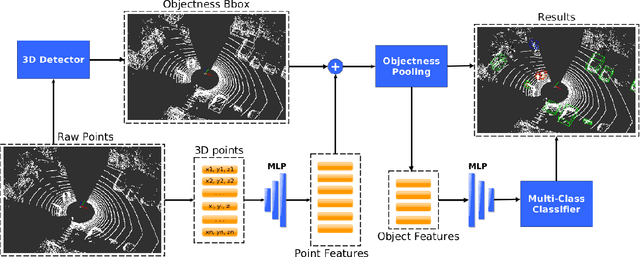
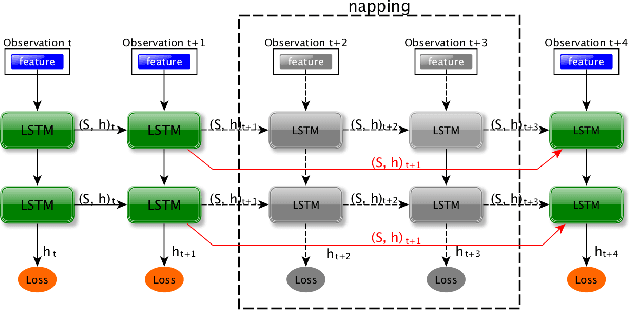
This paper presents a novel semantic mapping approach, Recurrent-OctoMap, learned from long-term 3D Lidar data. Most existing semantic mapping approaches focus on improving semantic understanding of single frames, rather than 3D refinement of semantic maps (i.e. fusing semantic observations). The most widely-used approach for 3D semantic map refinement is a Bayesian update, which fuses the consecutive predictive probabilities following a Markov-Chain model. Instead, we propose a learning approach to fuse the semantic features, rather than simply fusing predictions from a classifier. In our approach, we represent and maintain our 3D map as an OctoMap, and model each cell as a recurrent neural network (RNN), to obtain a Recurrent-OctoMap. In this case, the semantic mapping process can be formulated as a sequence-to-sequence encoding-decoding problem. Moreover, in order to extend the duration of observations in our Recurrent-OctoMap, we developed a robust 3D localization and mapping system for successively mapping a dynamic environment using more than two weeks of data, and the system can be trained and deployed with arbitrary memory length. We validate our approach on the ETH long-term 3D Lidar dataset [1]. The experimental results show that our proposed approach outperforms the conventional "Bayesian update" approach.