 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi-Quan Luo
Prior-dependent analysis of posterior sampling reinforcement learning with function approximation
Mar 17, 2024

This work advances randomized exploration in reinforcement learning (RL) with function approximation modeled by linear mixture MDPs. We establish the first prior-dependent Bayesian regret bound for RL with function approximation; and refine the Bayesian regret analysis for posterior sampling reinforcement learning (PSRL), presenting an upper bound of ${\mathcal{O}}(d\sqrt{H^3 T \log T})$, where $d$ represents the dimensionality of the transition kernel, $H$ the planning horizon, and $T$ the total number of interactions. This signifies a methodological enhancement by optimizing the $\mathcal{O}(\sqrt{\log T})$ factor over the previous benchmark (Osband and Van Roy, 2014) specified to linear mixture MDPs. Our approach, leveraging a value-targeted model learning perspective, introduces a decoupling argument and a variance reduction technique, moving beyond traditional analyses reliant on confidence sets and concentration inequalities to formalize Bayesian regret bounds more effectively.
Radar Anti-jamming Strategy Learning via Domain-knowledge Enhanced Online Convex Optimization
Feb 29, 2024The dynamic competition between radar and jammer systems presents a significant challenge for modern Electronic Warfare (EW), as current active learning approaches still lack sample efficiency and fail to exploit jammer's characteristics. In this paper, the competition between a frequency agile radar and a Digital Radio Frequency Memory (DRFM)-based intelligent jammer is considered. We introduce an Online Convex Optimization (OCO) framework designed to illustrate this adversarial interaction. Notably, traditional OCO algorithms exhibit suboptimal sample efficiency due to the limited information obtained per round. To address the limitations, two refined algorithms are proposed, utilizing unbiased gradient estimators that leverage the unique attributes of the jammer system. Sub-linear theoretical results on both static regret and universal regret are provided, marking a significant improvement in OCO performance. Furthermore, simulation results reveal that the proposed algorithms outperform common OCO baselines, suggesting the potential for effective deployment in real-world scenarios.
Why Transformers Need Adam: A Hessian Perspective
Feb 26, 2024SGD performs worse than Adam by a significant margin on Transformers, but the reason remains unclear. In this work, we provide an explanation of SGD's failure on Transformers through the lens of Hessian: (i) Transformers are ``heterogeneous'': the Hessian spectrum across parameter blocks vary dramatically, a phenomenon we call ``block heterogeneity"; (ii) Heterogeneity hampers SGD: SGD performs badly on problems with block heterogeneity. To validate that heterogeneity hampers SGD, we check various Transformers, CNNs, MLPs, and quadratic problems, and find that SGD works well on problems without block heterogeneity but performs badly when the heterogeneity exists. Our initial theoretical analysis indicates that SGD fails because it applies one single learning rate for all blocks, which cannot handle the heterogeneity among blocks. The failure could be rescued if we could assign different learning rates across blocks, as designed in Adam.
Optimistic Thompson Sampling for No-Regret Learning in Unknown Games
Feb 25, 2024This work tackles the complexities of multi-player scenarios in \emph{unknown games}, where the primary challenge lies in navigating the uncertainty of the environment through bandit feedback alongside strategic decision-making. We introduce Thompson Sampling (TS)-based algorithms that exploit the information of opponents' actions and reward structures, leading to a substantial reduction in experimental budgets -- achieving over tenfold improvements compared to conventional approaches. Notably, our algorithms demonstrate that, given specific reward structures, the regret bound depends logarithmically on the total action space, significantly alleviating the curse of multi-player. Furthermore, we unveil the \emph{Optimism-then-NoRegret} (OTN) framework, a pioneering methodology that seamlessly incorporates our advancements with established algorithms, showcasing its utility in practical scenarios such as traffic routing and radar sensing in the real world.
HyperAgent: A Simple, Scalable, Efficient and Provable Reinforcement Learning Framework for Complex Environments
Feb 05, 2024To solve complex tasks under resource constraints, reinforcement learning (RL) agents need to be simple, efficient, and scalable with (1) large state space and (2) increasingly accumulated data of interactions. We propose the HyperAgent, a RL framework with hypermodel, index sampling schemes and incremental update mechanism, enabling computation-efficient sequential posterior approximation and data-efficient action selection under general value function approximation beyond conjugacy. The implementation of \HyperAgent is simple as it only adds one module and one line of code additional to DDQN. Practically, HyperAgent demonstrates its robust performance in large-scale deep RL benchmarks with significant efficiency gain in terms of both data and computation. Theoretically, among the practically scalable algorithms, HyperAgent is the first method to achieve provably scalable per-step computational complexity as well as sublinear regret under tabular RL. The core of our theoretical analysis is the sequential posterior approximation argument, made possible by the first analytical tool for sequential random projection, a non-trivial martingale extension of the Johnson-Lindenstrauss lemma. This work bridges the theoretical and practical realms of RL, establishing a new benchmark for RL algorithm design.
Intelligent Surfaces Empowered Wireless Network: Recent Advances and The Road to 6G
Jan 15, 2024Intelligent surfaces (ISs) have emerged as a key technology to empower a wide range of appealing applications for wireless networks, due to their low cost, high energy efficiency, flexibility of deployment and capability of constructing favorable wireless channels/radio environments. Moreover, the recent advent of several new IS architectures further expanded their electromagnetic functionalities from passive reflection to active amplification, simultaneous reflection and refraction, as well as holographic beamforming. However, the research on ISs is still in rapid progress and there have been recent technological advances in ISs and their emerging applications that are worthy of a timely review. Thus, we provide in this paper a comprehensive survey on the recent development and advances of ISs aided wireless networks. Specifically, we start with an overview on the anticipated use cases of ISs in future wireless networks such as 6G, followed by a summary of the recent standardization activities related to ISs. Then, the main design issues of the commonly adopted reflection-based IS and their state-of-theart solutions are presented in detail, including reflection optimization, deployment, signal modulation, wireless sensing, and integrated sensing and communications. Finally, recent progress and new challenges in advanced IS architectures are discussed to inspire futrue research.
TeleQnA: A Benchmark Dataset to Assess Large Language Models Telecommunications Knowledge
Oct 23, 2023

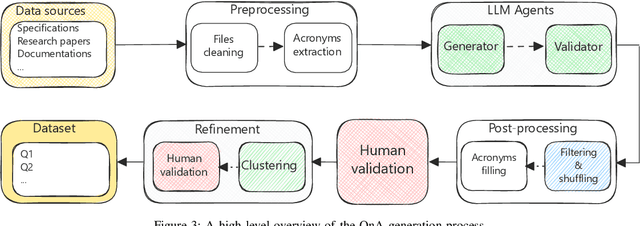
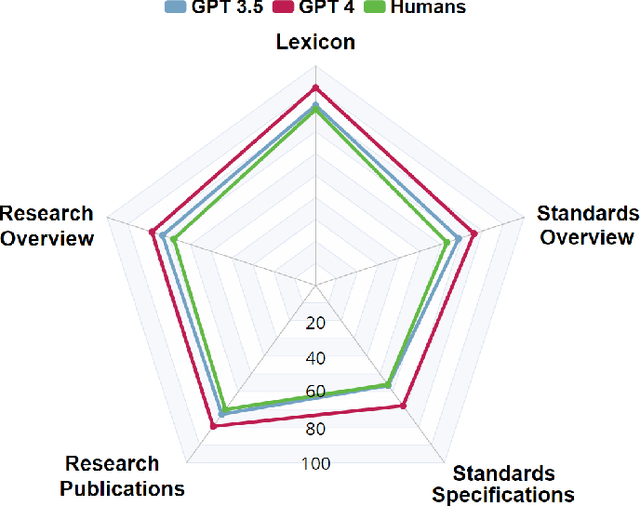
We introduce TeleQnA, the first benchmark dataset designed to evaluate the knowledge of Large Language Models (LLMs) in telecommunications. Comprising 10,000 questions and answers, this dataset draws from diverse sources, including standards and research articles. This paper outlines the automated question generation framework responsible for creating this dataset, along with how human input was integrated at various stages to ensure the quality of the questions. Afterwards, using the provided dataset, an evaluation is conducted to assess the capabilities of LLMs, including GPT-3.5 and GPT-4. The results highlight that these models struggle with complex standards related questions but exhibit proficiency in addressing general telecom-related inquiries. Additionally, our results showcase how incorporating telecom knowledge context significantly enhances their performance, thus shedding light on the need for a specialized telecom foundation model. Finally, the dataset is shared with active telecom professionals, whose performance is subsequently benchmarked against that of the LLMs. The findings illustrate that LLMs can rival the performance of active professionals in telecom knowledge, thanks to their capacity to process vast amounts of information, underscoring the potential of LLMs within this domain. The dataset has been made publicly accessible on GitHub.
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Oct 17, 2023Alignment is of critical importance for training large language models (LLMs). The predominant strategy to address this is through Reinforcement Learning from Human Feedback (RLHF), where PPO serves as the de-facto algorithm. Yet, PPO is known to suffer from computational inefficiency, which is a challenge that this paper aims to address. We identify three important properties in RLHF tasks: fast simulation, deterministic transitions, and trajectory-level rewards, which are not leveraged in PPO. Based on such observations, we develop a new algorithm tailored for RLHF, called ReMax. The algorithm design of ReMax is built on a celebrated algorithm REINFORCE but is equipped with a new variance-reduction technique. Our method has three-fold advantages over PPO: first, ReMax is simple to implement and removes many hyper-parameters in PPO, which are scale-sensitive and laborious to tune. Second, ReMax saves about 50% memory usage in principle. As a result, PPO runs out-of-memory when fine-tuning a Llama2 (7B) model on 8xA100-40GB GPUs, whereas ReMax can afford training. This memory improvement is achieved by removing the value model in PPO. Third, based on our calculations, we find that even assuming PPO can afford the training of Llama2 (7B), it would still run about 2x slower than ReMax. This is due to the computational overhead of the value model, which does not exist in ReMax. Importantly, the above computational improvements do not sacrifice the performance. We hypothesize these advantages can be maintained in larger-scaled models. Our implementation of ReMax is available at https://github.com/liziniu/ReMax
An Efficient Decomposition Algorithm for Large-Scale Network Slicing
Jun 27, 2023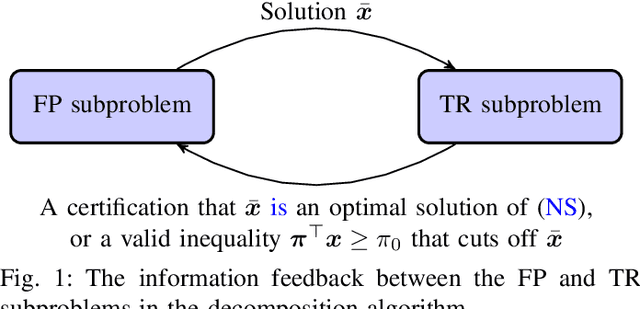
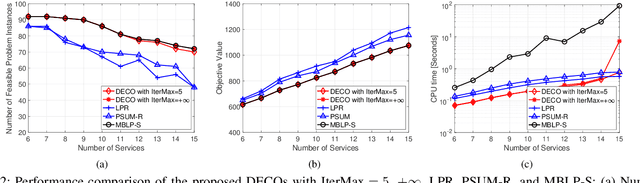
In this paper, we consider the network slicing (NS) problem which attempts to map multiple customized virtual network requests to a common shared network infrastructure and allocate network resources to meet diverse service requirements. We propose an efficient decomposition algorithm for solving this NP-hard problem. The proposed algorithm decomposes the large-scale hard NS problem into two relatively easy function placement (FP) and traffic routing (TR) subproblems and iteratively solves them enabling information feedback between each other, which makes it particularly suitable to solve large-scale problems. Specifically, the FP subproblem is to place service functions into cloud nodes in the network, and solving it can return a function placement strategy based on which the TR subproblem is defined; and the TR subproblem is to find paths connecting two nodes hosting two adjacent functions in the network, and solving it can either verify that the solution of the FP subproblem is an optimal solution of the original problem, or return a valid inequality to the FP subproblem that cuts off the current infeasible solution. The proposed algorithm is guaranteed to find the global solution of the NS problem. We demonstrate the effectiveness and efficiency of the proposed algorithm via numerical experiments.
Provably Efficient Adversarial Imitation Learning with Unknown Transitions
Jun 11, 2023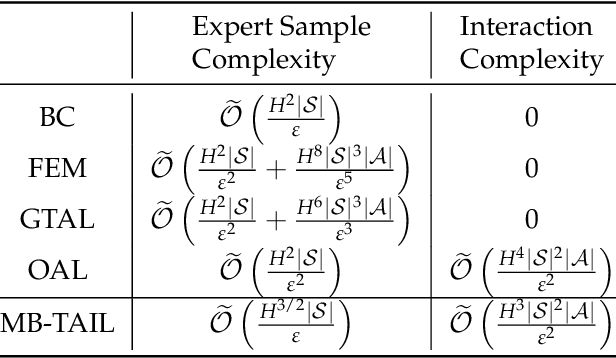
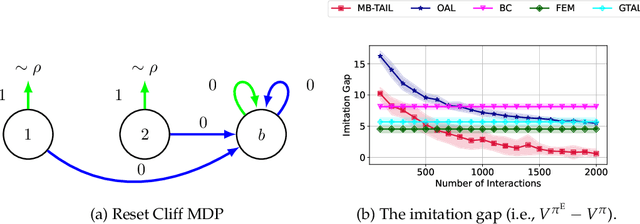
Imitation learning (IL) has proven to be an effective method for learning good policies from expert demonstrations. Adversarial imitation learning (AIL), a subset of IL methods, is particularly promising, but its theoretical foundation in the presence of unknown transitions has yet to be fully developed. This paper explores the theoretical underpinnings of AIL in this context, where the stochastic and uncertain nature of environment transitions presents a challenge. We examine the expert sample complexity and interaction complexity required to recover good policies. To this end, we establish a framework connecting reward-free exploration and AIL, and propose an algorithm, MB-TAIL, that achieves the minimax optimal expert sample complexity of $\widetilde{O} (H^{3/2} |S|/\varepsilon)$ and interaction complexity of $\widetilde{O} (H^{3} |S|^2 |A|/\varepsilon^2)$. Here, $H$ represents the planning horizon, $|S|$ is the state space size, $|A|$ is the action space size, and $\varepsilon$ is the desired imitation gap. MB-TAIL is the first algorithm to achieve this level of expert sample complexity in the unknown transition setting and improves upon the interaction complexity of the best-known algorithm, OAL, by $O(H)$. Additionally, we demonstrate the generalization ability of MB-TAIL by extending it to the function approximation setting and proving that it can achieve expert sample and interaction complexity independent of $|S|$