 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhixiang Wang
Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
Mar 28, 2024
In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.
Efficient Continuous-Time Ego-Motion Estimation for Asynchronous Event-based Data Associations
Feb 26, 2024Event cameras are bio-inspired vision sensors that asynchronously measure per-pixel brightness changes. The high temporal resolution and asynchronicity of event cameras offer great potential for estimating the robot motion state. Recent works have adopted the continuous-time ego-motion estimation methods to exploit the inherent nature of event cameras. However, most of the adopted methods have poor real-time performance. To alleviate it, a lightweight Gaussian Process (GP)-based estimation framework is proposed to efficiently estimate motion trajectory from asynchronous event-driven data associations. Concretely, an asynchronous front-end pipeline is designed to adapt event-driven feature trackers and generate feature trajectories from event streams; a parallel dynamic sliding-window back-end is presented within the framework of sparse GP regression on SE(3). Notably, a specially designed state marginalization strategy is employed to ensure the consistency and sparsity of this GP regression. Experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves competitive precision and superior robustness compared to the state-of-the-art. Furthermore, the evaluations on three 60 s trajectories show that the proposal outperforms the ISAM2-based method in terms of computational efficiency by 2.64, 4.22, and 11.70 times, respectively.
Contributing Dimension Structure of Deep Feature for Coreset Selection
Jan 29, 2024Coreset selection seeks to choose a subset of crucial training samples for efficient learning. It has gained traction in deep learning, particularly with the surge in training dataset sizes. Sample selection hinges on two main aspects: a sample's representation in enhancing performance and the role of sample diversity in averting overfitting. Existing methods typically measure both the representation and diversity of data based on similarity metrics, such as L2-norm. They have capably tackled representation via distribution matching guided by the similarities of features, gradients, or other information between data. However, the results of effectively diverse sample selection are mired in sub-optimality. This is because the similarity metrics usually simply aggregate dimension similarities without acknowledging disparities among the dimensions that significantly contribute to the final similarity. As a result, they fall short of adequately capturing diversity. To address this, we propose a feature-based diversity constraint, compelling the chosen subset to exhibit maximum diversity. Our key lies in the introduction of a novel Contributing Dimension Structure (CDS) metric. Different from similarity metrics that measure the overall similarity of high-dimensional features, our CDS metric considers not only the reduction of redundancy in feature dimensions, but also the difference between dimensions that contribute significantly to the final similarity. We reveal that existing methods tend to favor samples with similar CDS, leading to a reduced variety of CDS types within the coreset and subsequently hindering model performance. In response, we enhance the performance of five classical selection methods by integrating the CDS constraint. Our experiments on three datasets demonstrate the general effectiveness of the proposed method in boosting existing methods.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
Multi-level feature fusion network combining attention mechanisms for polyp segmentation
Sep 24, 2023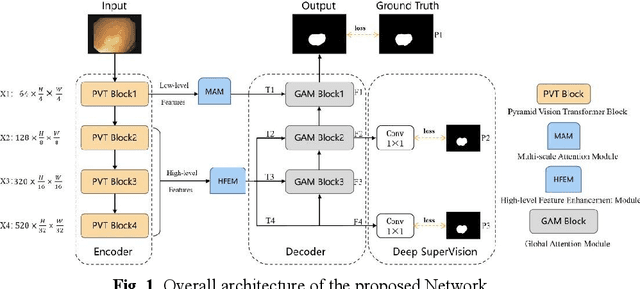
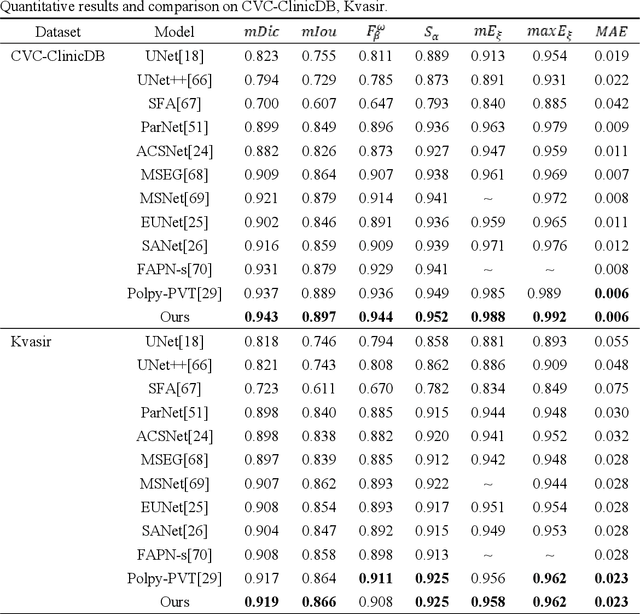
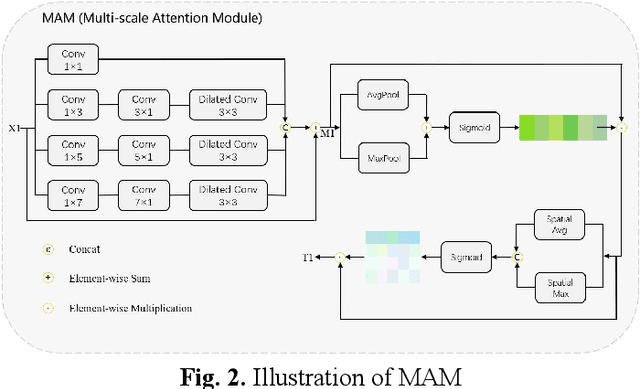
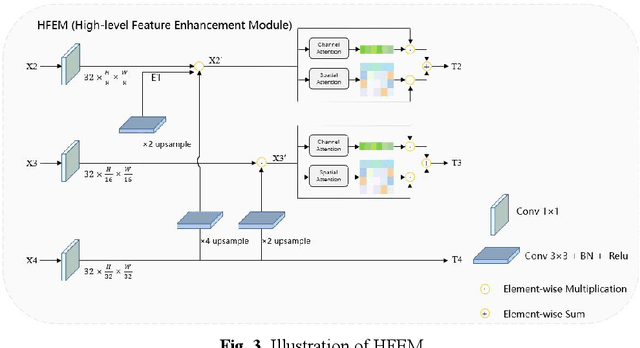
Clinically, automated polyp segmentation techniques have the potential to significantly improve the efficiency and accuracy of medical diagnosis, thereby reducing the risk of colorectal cancer in patients. Unfortunately, existing methods suffer from two significant weaknesses that can impact the accuracy of segmentation. Firstly, features extracted by encoders are not adequately filtered and utilized. Secondly, semantic conflicts and information redundancy caused by feature fusion are not attended to. To overcome these limitations, we propose a novel approach for polyp segmentation, named MLFF-Net, which leverages multi-level feature fusion and attention mechanisms. Specifically, MLFF-Net comprises three modules: Multi-scale Attention Module (MAM), High-level Feature Enhancement Module (HFEM), and Global Attention Module (GAM). Among these, MAM is used to extract multi-scale information and polyp details from the shallow output of the encoder. In HFEM, the deep features of the encoders complement each other by aggregation. Meanwhile, the attention mechanism redistributes the weight of the aggregated features, weakening the conflicting redundant parts and highlighting the information useful to the task. GAM combines features from the encoder and decoder features, as well as computes global dependencies to prevent receptive field locality. Experimental results on five public datasets show that the proposed method not only can segment multiple types of polyps but also has advantages over current state-of-the-art methods in both accuracy and generalization ability.
Beyond Domain Gap: Exploiting Subjectivity in Sketch-Based Person Retrieval
Sep 15, 2023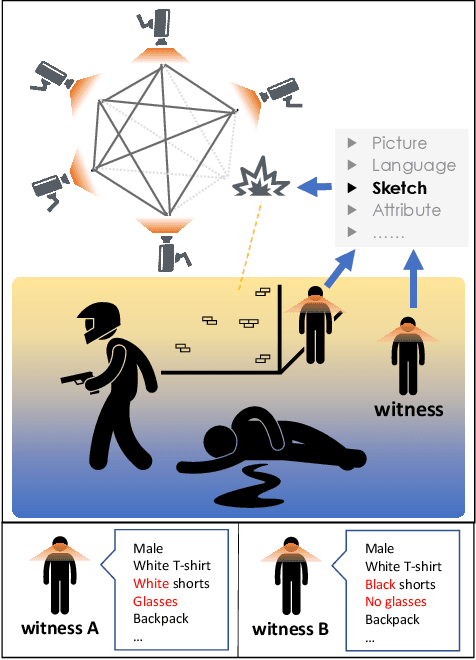

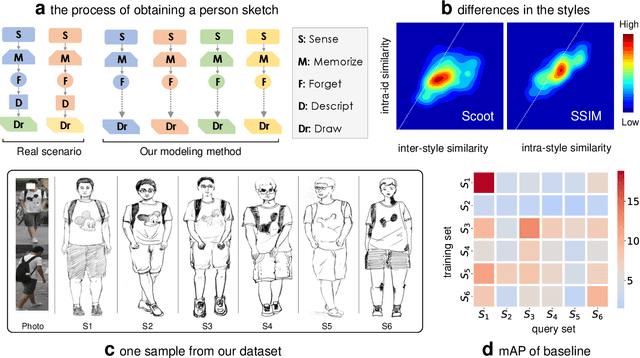
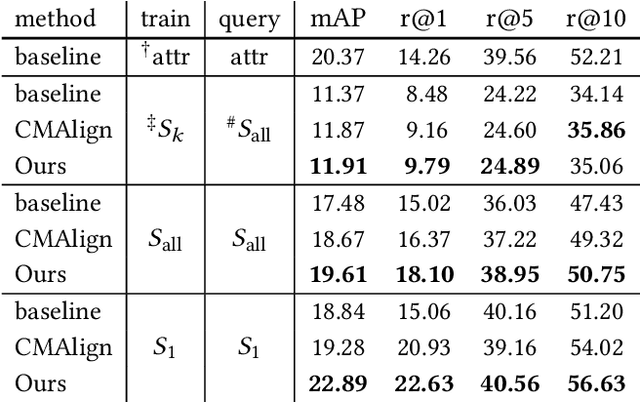
Person re-identification (re-ID) requires densely distributed cameras. In practice, the person of interest may not be captured by cameras and, therefore, needs to be retrieved using subjective information (e.g., sketches from witnesses). Previous research defines this case using the sketch as sketch re-identification (Sketch re-ID) and focuses on eliminating the domain gap. Actually, subjectivity is another significant challenge. We model and investigate it by posing a new dataset with multi-witness descriptions. It features two aspects. 1) Large-scale. It contains over 4,763 sketches and 32,668 photos, making it the largest Sketch re-ID dataset. 2) Multi-perspective and multi-style. Our dataset offers multiple sketches for each identity. Witnesses' subjective cognition provides multiple perspectives on the same individual, while different artists' drawing styles provide variation in sketch styles. We further have two novel designs to alleviate the challenge of subjectivity. 1) Fusing subjectivity. We propose a non-local (NL) fusion module that gathers sketches from different witnesses for the same identity. 2) Introducing objectivity. An AttrAlign module utilizes attributes as an implicit mask to align cross-domain features. To push forward the advance of Sketch re-ID, we set three benchmarks (large-scale, multi-style, cross-style). Extensive experiments demonstrate our leading performance in these benchmarks. Dataset and Codes are publicly available at: https://github.com/Lin-Kayla/subjectivity-sketch-reid
DisCO: Portrait Distortion Correction with Perspective-Aware 3D GANs
Feb 23, 2023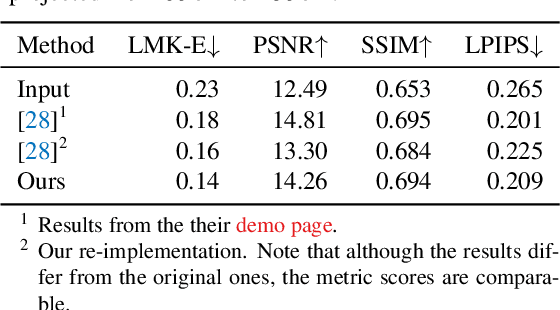

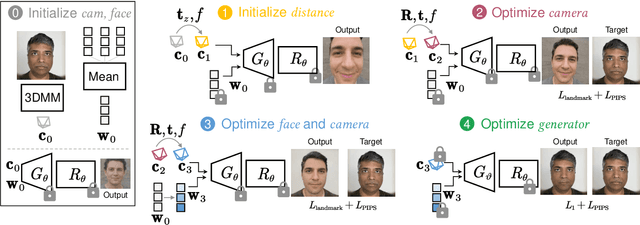
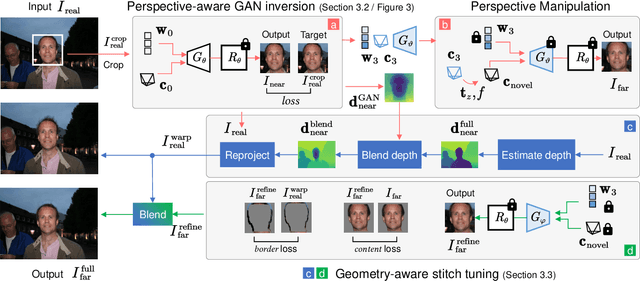
Close-up facial images captured at close distances often suffer from perspective distortion, resulting in exaggerated facial features and unnatural/unattractive appearances. We propose a simple yet effective method for correcting perspective distortions in a single close-up face. We first perform GAN inversion using a perspective-distorted input facial image by jointly optimizing the camera intrinsic/extrinsic parameters and face latent code. To address the ambiguity of joint optimization, we develop focal length reparametrization, optimization scheduling, and geometric regularization. Re-rendering the portrait at a proper focal length and camera distance effectively corrects these distortions and produces more natural-looking results. Our experiments show that our method compares favorably against previous approaches regarding visual quality. We showcase numerous examples validating the applicability of our method on portrait photos in the wild.
HOTCOLD Block: Fooling Thermal Infrared Detectors with a Novel Wearable Design
Dec 12, 2022
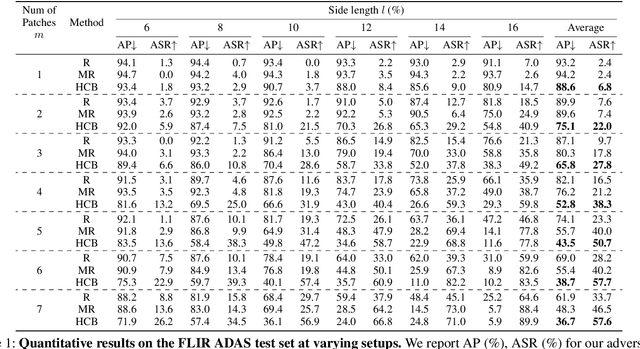
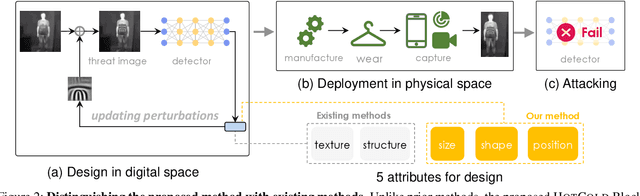
Adversarial attacks on thermal infrared imaging expose the risk of related applications. Estimating the security of these systems is essential for safely deploying them in the real world. In many cases, realizing the attacks in the physical space requires elaborate special perturbations. These solutions are often \emph{impractical} and \emph{attention-grabbing}. To address the need for a physically practical and stealthy adversarial attack, we introduce \textsc{HotCold} Block, a novel physical attack for infrared detectors that hide persons utilizing the wearable Warming Paste and Cooling Paste. By attaching these readily available temperature-controlled materials to the body, \textsc{HotCold} Block evades human eyes efficiently. Moreover, unlike existing methods that build adversarial patches with complex texture and structure features, \textsc{HotCold} Block utilizes an SSP-oriented adversarial optimization algorithm that enables attacks with pure color blocks and explores the influence of size, shape, and position on attack performance. Extensive experimental results in both digital and physical environments demonstrate the performance of our proposed \textsc{HotCold} Block. \emph{Code is available: \textcolor{magenta}{https://github.com/weihui1308/HOTCOLDBlock}}.
Physical Adversarial Attack meets Computer Vision: A Decade Survey
Sep 30, 2022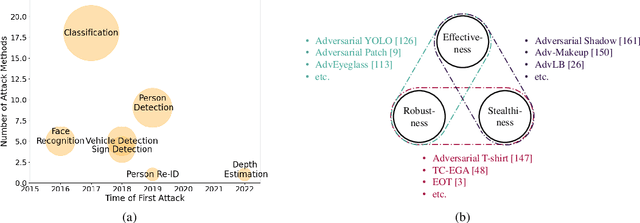
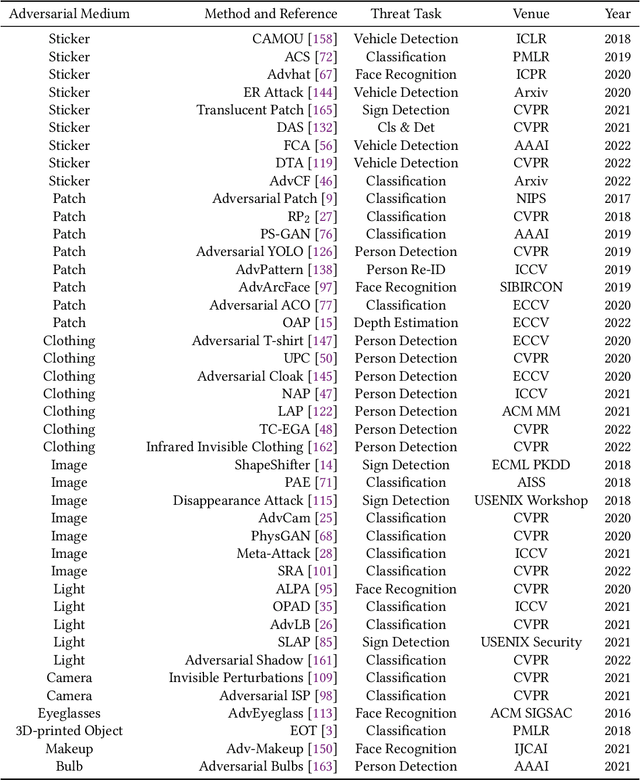

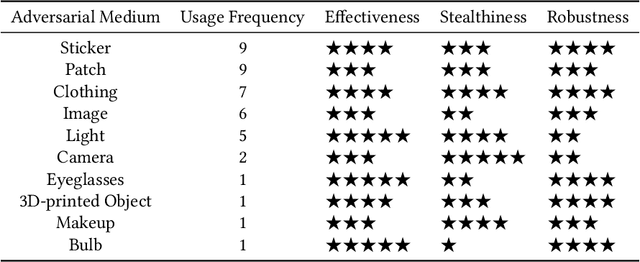
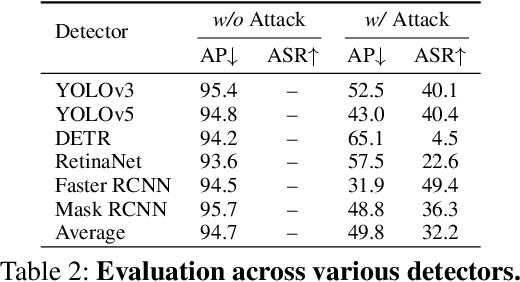
Although Deep Neural Networks (DNNs) have achieved impressive results in computer vision, their exposed vulnerability to adversarial attacks remains a serious concern. A series of works has shown that by adding elaborate perturbations to images, DNNs could have catastrophic degradation in performance metrics. And this phenomenon does not only exist in the digital space but also in the physical space. Therefore, estimating the security of these DNNs-based systems is critical for safely deploying them in the real world, especially for security-critical applications, e.g., autonomous cars, video surveillance, and medical diagnosis. In this paper, we focus on physical adversarial attacks and provide a comprehensive survey of over 150 existing papers. We first clarify the concept of the physical adversarial attack and analyze its characteristics. Then, we define the adversarial medium, essential to perform attacks in the physical world. Next, we present the physical adversarial attack methods in task order: classification, detection, and re-identification, and introduce their performance in solving the trilemma: effectiveness, stealthiness, and robustness. In the end, we discuss the current challenges and potential future directions.