 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhonghua Zhai
Tunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
Apr 26, 2024




Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named "Tunnel Try-on." The core idea is excavating a "focus tunnel" in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.
Cell Variational Information Bottleneck Network
Mar 29, 2024In this work, we propose Cell Variational Information Bottleneck Network (cellVIB), a convolutional neural network using information bottleneck mechanism, which can be combined with the latest feedforward network architecture in an end-to-end training method. Our Cell Variational Information Bottleneck Network is constructed by stacking VIB cells, which generate feature maps with uncertainty. As layers going deeper, the regularization effect will gradually increase, instead of directly adding excessive regular constraints to the output layer of the model as in Deep VIB. Under each VIB cell, the feedforward process learns an independent mean term and an standard deviation term, and predicts the Gaussian distribution based on them. The feedback process is based on reparameterization trick for effective training. This work performs an extensive analysis on MNIST dataset to verify the effectiveness of each VIB cells, and provides an insightful analysis on how the VIB cells affect mutual information. Experiments conducted on CIFAR-10 also prove that our cellVIB is robust against noisy labels during training and against corrupted images during testing. Then, we validate our method on PACS dataset, whose results show that the VIB cells can significantly improve the generalization performance of the basic model. Finally, in a more complex representation learning task, face recognition, our network structure has also achieved very competitive results.
Wear-Any-Way: Manipulable Virtual Try-on via Sparse Correspondence Alignment
Mar 19, 2024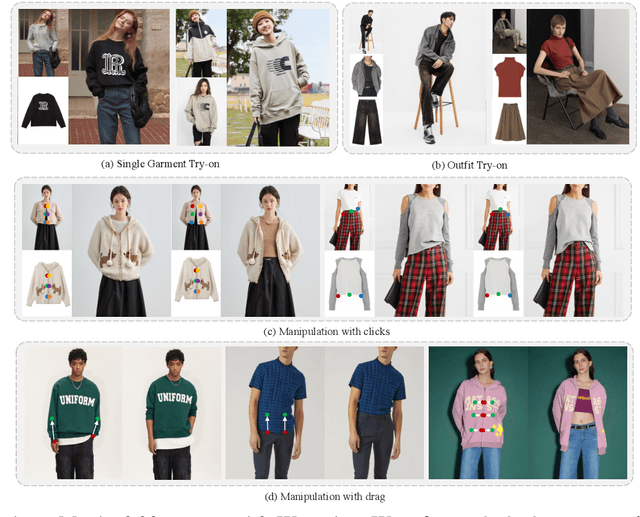

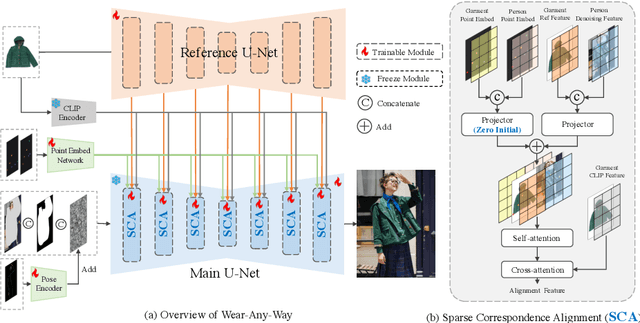
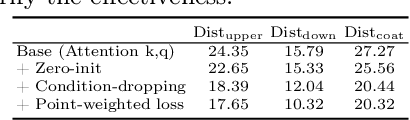
This paper introduces a novel framework for virtual try-on, termed Wear-Any-Way. Different from previous methods, Wear-Any-Way is a customizable solution. Besides generating high-fidelity results, our method supports users to precisely manipulate the wearing style. To achieve this goal, we first construct a strong pipeline for standard virtual try-on, supporting single/multiple garment try-on and model-to-model settings in complicated scenarios. To make it manipulable, we propose sparse correspondence alignment which involves point-based control to guide the generation for specific locations. With this design, Wear-Any-Way gets state-of-the-art performance for the standard setting and provides a novel interaction form for customizing the wearing style. For instance, it supports users to drag the sleeve to make it rolled up, drag the coat to make it open, and utilize clicks to control the style of tuck, etc. Wear-Any-Way enables more liberated and flexible expressions of the attires, holding profound implications in the fashion industry.
Turbo: Informativity-Driven Acceleration Plug-In for Vision-Language Models
Dec 12, 2023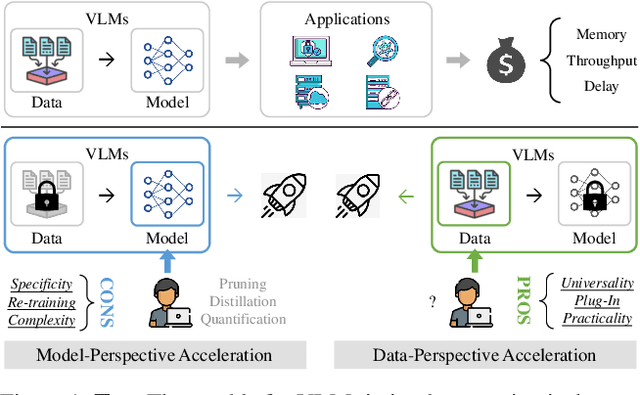
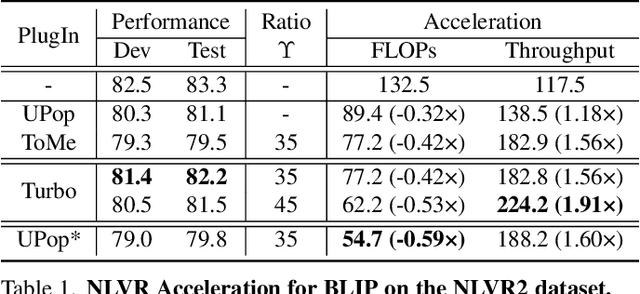
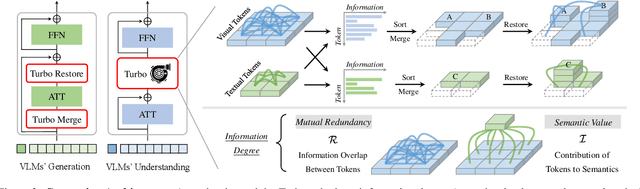
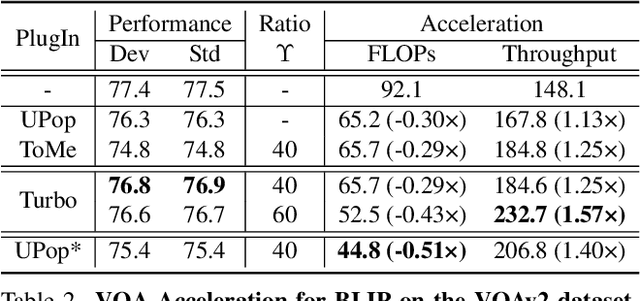
Vision-Language Large Models (VLMs) have become primary backbone of AI, due to the impressive performance. However, their expensive computation costs, i.e., throughput and delay, impede potentials in real-world scenarios. To achieve acceleration for VLMs, most existing methods focus on the model perspective: pruning, distillation, quantification, but completely overlook the data-perspective redundancy. To fill the overlook, this paper pioneers the severity of data redundancy, and designs one plug-and-play Turbo module guided by information degree to prune inefficient tokens from visual or textual data. In pursuit of efficiency-performance trade-offs, information degree takes two key factors into consideration: mutual redundancy and semantic value. Concretely, the former evaluates the data duplication between sequential tokens; while the latter evaluates each token by its contribution to the overall semantics. As a result, tokens with high information degree carry less redundancy and stronger semantics. For VLMs' calculation, Turbo works as a user-friendly plug-in that sorts data referring to information degree, utilizing only top-level ones to save costs. Its advantages are multifaceted, e.g., being generally compatible to various VLMs across understanding and generation, simple use without retraining and trivial engineering efforts. On multiple public VLMs benchmarks, we conduct extensive experiments to reveal the gratifying acceleration of Turbo, under negligible performance drop.
Mixer: Image to Multi-Modal Retrieval Learning for Industrial Application
May 06, 2023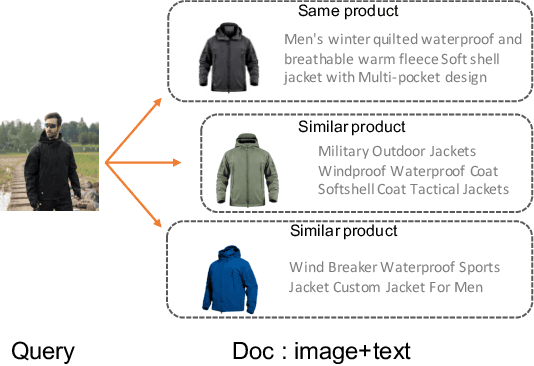
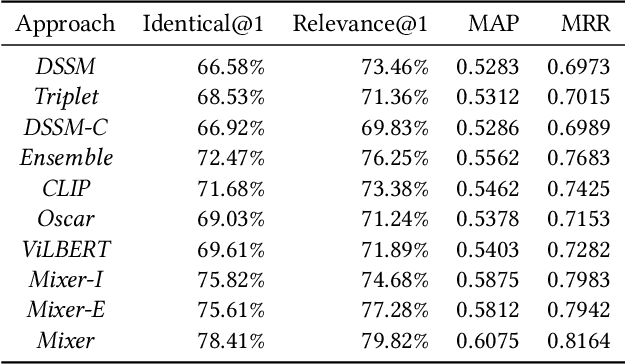

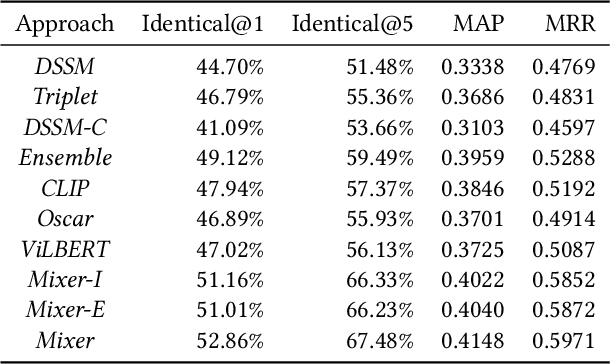
Cross-modal retrieval, where the query is an image and the doc is an item with both image and text description, is ubiquitous in e-commerce platforms and content-sharing social media. However, little research attention has been paid to this important application. This type of retrieval task is challenging due to the facts: 1)~domain gap exists between query and doc. 2)~multi-modality alignment and fusion. 3)~skewed training data and noisy labels collected from user behaviors. 4)~huge number of queries and timely responses while the large-scale candidate docs exist. To this end, we propose a novel scalable and efficient image query to multi-modal retrieval learning paradigm called Mixer, which adaptively integrates multi-modality data, mines skewed and noisy data more efficiently and scalable to high traffic. The Mixer consists of three key ingredients: First, for query and doc image, a shared encoder network followed by separate transformation networks are utilized to account for their domain gap. Second, in the multi-modal doc, images and text are not equally informative. So we design a concept-aware modality fusion module, which extracts high-level concepts from the text by a text-to-image attention mechanism. Lastly, but most importantly, we turn to a new data organization and training paradigm for single-modal to multi-modal retrieval: large-scale classification learning which treats single-modal query and multi-modal doc as equivalent samples of certain classes. Besides, the data organization follows a weakly-supervised manner, which can deal with skewed data and noisy labels inherited in the industrial systems. Learning such a large number of categories for real-world multi-modality data is non-trivial and we design a specific learning strategy for it. The proposed Mixer achieves SOTA performance on public datasets from industrial retrieval systems.