 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhuoming Chen
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
Apr 18, 2024
With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cache, which is stored to avoid re-computation, has emerged as a critical bottleneck by growing linearly in size with the sequence length. Due to the auto-regressive nature of LLMs, the entire KV cache will be loaded for every generated token, resulting in low utilization of computational cores and high latency. While various compression methods for KV cache have been proposed to alleviate this issue, they suffer from degradation in generation quality. We introduce TriForce, a hierarchical speculative decoding system that is scalable to long sequence generation. This approach leverages the original model weights and dynamic sparse KV cache via retrieval as a draft model, which serves as an intermediate layer in the hierarchy and is further speculated by a smaller model to reduce its drafting latency. TriForce not only facilitates impressive speedups for Llama2-7B-128K, achieving up to 2.31$\times$ on an A100 GPU but also showcases scalability in handling even longer contexts. For the offloading setting on two RTX 4090 GPUs, TriForce achieves 0.108s/token$\unicode{x2014}$only half as slow as the auto-regressive baseline on an A100, which attains 7.78$\times$ on our optimized offloading system. Additionally, TriForce performs 4.86$\times$ than DeepSpeed-Zero-Inference on a single RTX 4090 GPU. TriForce's robustness is highlighted by its consistently outstanding performance across various temperatures. The code is available at https://github.com/Infini-AI-Lab/TriForce.
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Feb 29, 2024As the usage of large language models (LLMs) grows, performing efficient inference with these models becomes increasingly important. While speculative decoding has recently emerged as a promising direction for speeding up inference, existing methods are limited in their ability to scale to larger speculation budgets, and adapt to different hyperparameters and hardware. This paper introduces Sequoia, a scalable, robust, and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to $4.04\times$, $3.73\times$, and $2.27\times$. For offloading setting on L40, Sequoia achieves as low as 0.56 s/token for exact Llama2-70B inference latency, which is $9.96\times$ on our optimized offloading system (5.6 s/token), $9.7\times$ than DeepSpeed-Zero-Inference, $19.5\times$ than Huggingface Accelerate.
GNNPipe: Accelerating Distributed Full-Graph GNN Training with Pipelined Model Parallelism
Aug 19, 2023Current distributed full-graph GNN training methods adopt a variant of data parallelism, namely graph parallelism, in which the whole graph is divided into multiple partitions (subgraphs) and each GPU processes one of them. This incurs high communication overhead because of the inter-partition message passing at each layer. To this end, we proposed a new training method named GNNPipe that adopts model parallelism instead, which has a lower worst-case asymptotic communication complexity than graph parallelism. To ensure high GPU utilization, we proposed to combine model parallelism with a chunk-based pipelined training method, in which each GPU processes a different chunk of graph data at different layers concurrently. We further proposed hybrid parallelism that combines model and graph parallelism when the model-level parallelism is insufficient. We also introduced several tricks to ensure convergence speed and model accuracies to accommodate embedding staleness introduced by pipelining. Extensive experiments show that our method reduces the per-epoch training time by up to 2.45x (on average 2.03x) and reduces the communication volume and overhead by up to 22.51x and 27.21x (on average 10.27x and 14.96x), respectively, while achieving a comparable level of model accuracy and convergence speed compared to graph parallelism.
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
May 16, 2023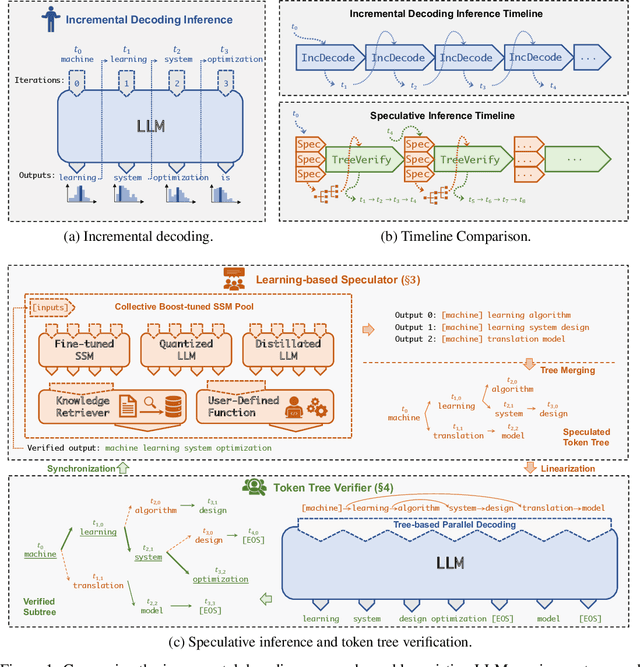
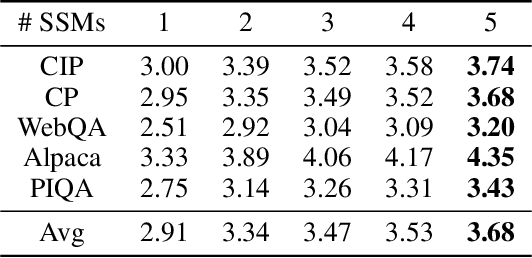


The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. This paper introduces SpecInfer, an LLM serving system that accelerates generative LLM inference with speculative inference and token tree verification. A key insight behind SpecInfer is to combine various collectively boost-tuned small language models to jointly predict the LLM's outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified by the LLM in parallel using a novel tree-based parallel decoding mechanism. SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which significantly reduces the end-to-end latency and computational requirement for serving generative LLMs while provably preserving model quality.
Quark: A Gradient-Free Quantum Learning Framework for Classification Tasks
Oct 02, 2022



As more practical and scalable quantum computers emerge, much attention has been focused on realizing quantum supremacy in machine learning. Existing quantum ML methods either (1) embed a classical model into a target Hamiltonian to enable quantum optimization or (2) represent a quantum model using variational quantum circuits and apply classical gradient-based optimization. The former method leverages the power of quantum optimization but only supports simple ML models, while the latter provides flexibility in model design but relies on gradient calculation, resulting in barren plateau (i.e., gradient vanishing) and frequent classical-quantum interactions. To address the limitations of existing quantum ML methods, we introduce Quark, a gradient-free quantum learning framework that optimizes quantum ML models using quantum optimization. Quark does not rely on gradient computation and therefore avoids barren plateau and frequent classical-quantum interactions. In addition, Quark can support more general ML models than prior quantum ML methods and achieves a dataset-size-independent optimization complexity. Theoretically, we prove that Quark can outperform classical gradient-based methods by reducing model query complexity for highly non-convex problems; empirically, evaluations on the Edge Detection and Tiny-MNIST tasks show that Quark can support complex ML models and significantly reduce the number of measurements needed for discovering near-optimal weights for these tasks.
Quantized Training of Gradient Boosting Decision Trees
Jul 20, 2022



Recent years have witnessed significant success in Gradient Boosting Decision Trees (GBDT) for a wide range of machine learning applications. Generally, a consensus about GBDT's training algorithms is gradients and statistics are computed based on high-precision floating points. In this paper, we investigate an essentially important question which has been largely ignored by the previous literature: how many bits are needed for representing gradients in training GBDT? To solve this mystery, we propose to quantize all the high-precision gradients in a very simple yet effective way in the GBDT's training algorithm. Surprisingly, both our theoretical analysis and empirical studies show that the necessary precisions of gradients without hurting any performance can be quite low, e.g., 2 or 3 bits. With low-precision gradients, most arithmetic operations in GBDT training can be replaced by integer operations of 8, 16, or 32 bits. Promisingly, these findings may pave the way for much more efficient training of GBDT from several aspects: (1) speeding up the computation of gradient statistics in histograms; (2) compressing the communication cost of high-precision statistical information during distributed training; (3) the inspiration of utilization and development of hardware architectures which well support low-precision computation for GBDT training. Benchmarked on CPU, GPU, and distributed clusters, we observe up to 2$\times$ speedup of our simple quantization strategy compared with SOTA GBDT systems on extensive datasets, demonstrating the effectiveness and potential of the low-precision training of GBDT. The code will be released to the official repository of LightGBM.