 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhuoyi Yang
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
Mar 08, 2024
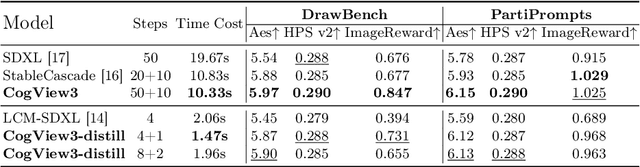

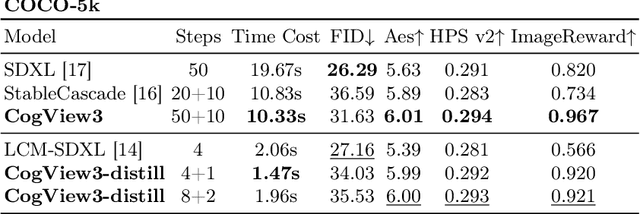
Recent advancements in text-to-image generative systems have been largely driven by diffusion models. However, single-stage text-to-image diffusion models still face challenges, in terms of computational efficiency and the refinement of image details. To tackle the issue, we propose CogView3, an innovative cascaded framework that enhances the performance of text-to-image diffusion. CogView3 is the first model implementing relay diffusion in the realm of text-to-image generation, executing the task by first creating low-resolution images and subsequently applying relay-based super-resolution. This methodology not only results in competitive text-to-image outputs but also greatly reduces both training and inference costs. Our experimental results demonstrate that CogView3 outperforms SDXL, the current state-of-the-art open-source text-to-image diffusion model, by 77.0\% in human evaluations, all while requiring only about 1/2 of the inference time. The distilled variant of CogView3 achieves comparable performance while only utilizing 1/10 of the inference time by SDXL.
CogVLM: Visual Expert for Pretrained Language Models
Nov 06, 2023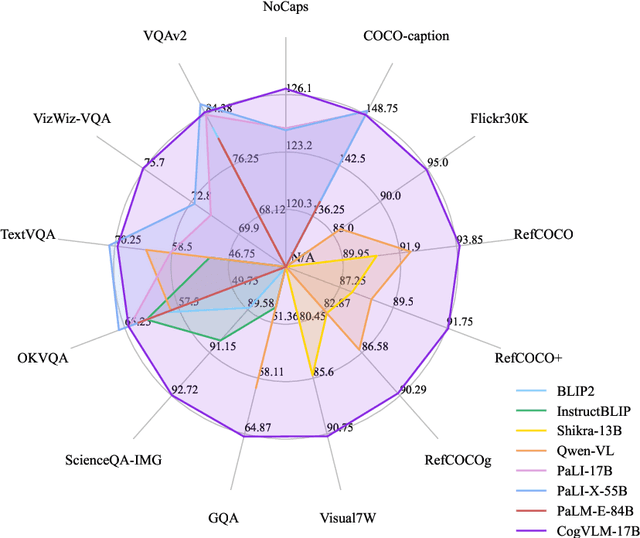
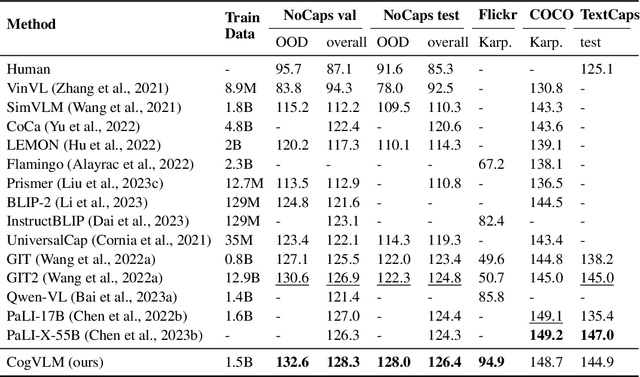

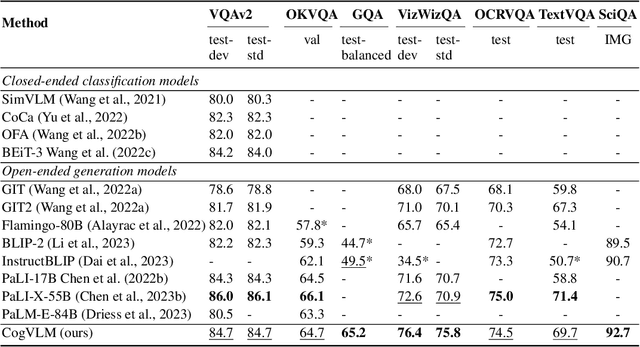
We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B. Codes and checkpoints are available at https://github.com/THUDM/CogVLM.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023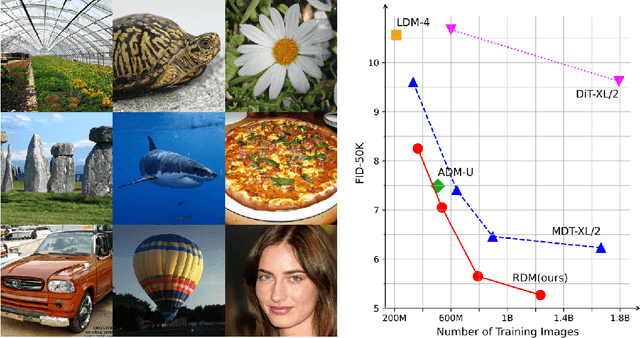

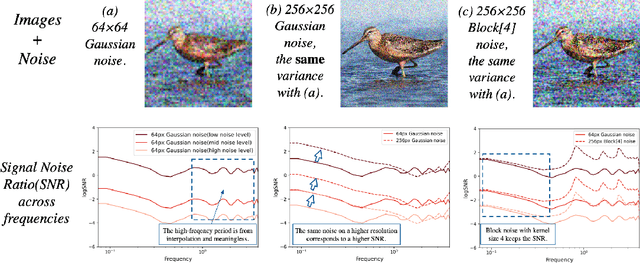
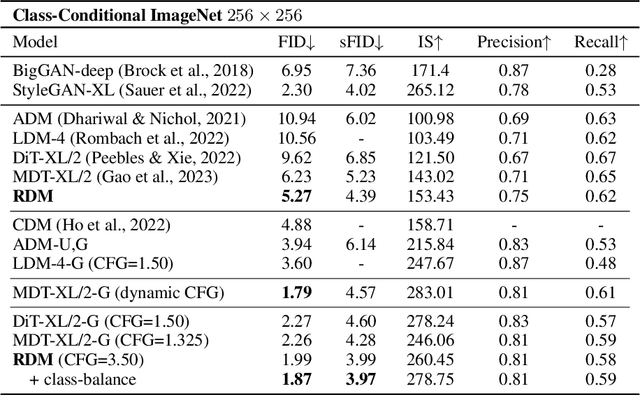
Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
Eloss in the way: A Sensitive Input Quality Metrics for Intelligent Driving
Feb 02, 2023



With the increasing complexity of the traffic environment, the importance of safety perception in intelligent driving is growing. Conventional methods in the robust perception of intelligent driving focus on training models with anomalous data, letting the deep neural network decide how to tackle anomalies. However, these models cannot adapt smoothly to the diverse and complex real-world environment. This paper proposes a new type of metric known as Eloss and offers a novel training strategy to empower perception models from the aspect of anomaly detection. Eloss is designed based on an explanation of the perception model's information compression layers. Specifically, taking inspiration from the design of a communication system, the information transmission process of an information compression network has two expectations: the amount of information changes steadily, and the information entropy continues to decrease. Then Eloss can be obtained according to the above expectations, guiding the update of related network parameters and producing a sensitive metric to identify anomalies while maintaining the model performance. Our experiments demonstrate that Eloss can deviate from the standard value by a factor over 100 with anomalous data and produce distinctive values for similar but different types of anomalies, showing the effectiveness of the proposed method. Our code is available at: (code available after paper accepted).
Parameter-Efficient Tuning Makes a Good Classification Head
Oct 30, 2022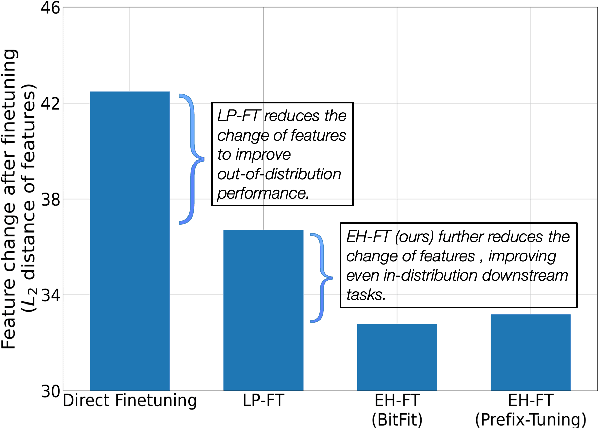
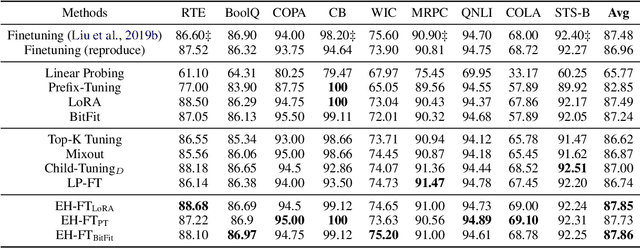
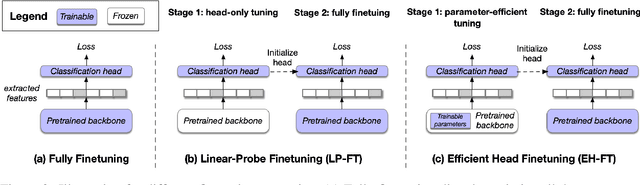

In recent years, pretrained models revolutionized the paradigm of natural language understanding (NLU), where we append a randomly initialized classification head after the pretrained backbone, e.g. BERT, and finetune the whole model. As the pretrained backbone makes a major contribution to the improvement, we naturally expect a good pretrained classification head can also benefit the training. However, the final-layer output of the backbone, i.e. the input of the classification head, will change greatly during finetuning, making the usual head-only pretraining (LP-FT) ineffective. In this paper, we find that parameter-efficient tuning makes a good classification head, with which we can simply replace the randomly initialized heads for a stable performance gain. Our experiments demonstrate that the classification head jointly pretrained with parameter-efficient tuning consistently improves the performance on 9 tasks in GLUE and SuperGLUE.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022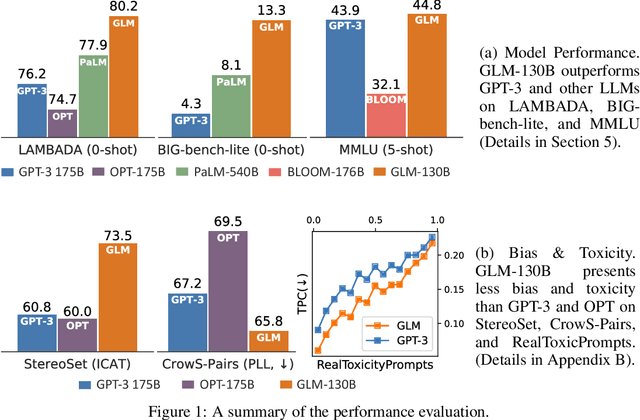
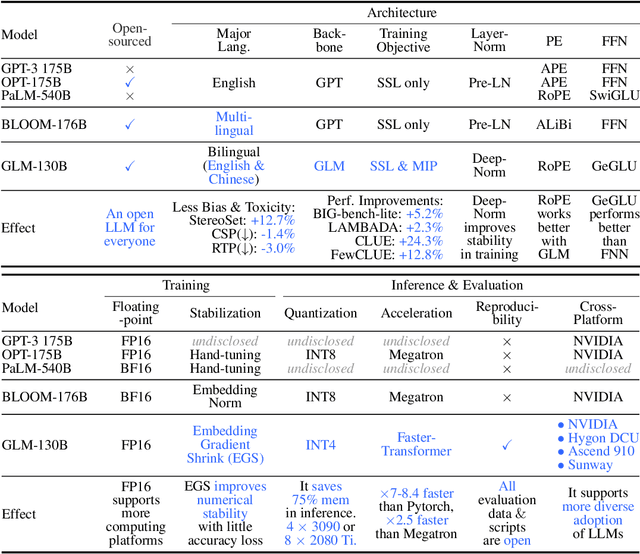

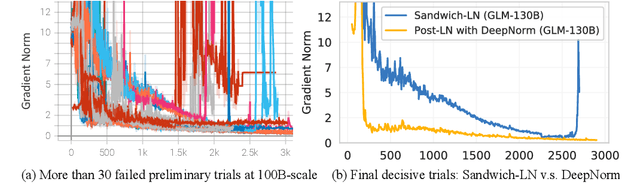
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .
CogView: Mastering Text-to-Image Generation via Transformers
May 28, 2021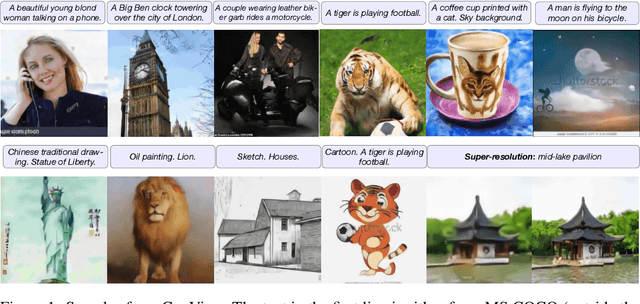
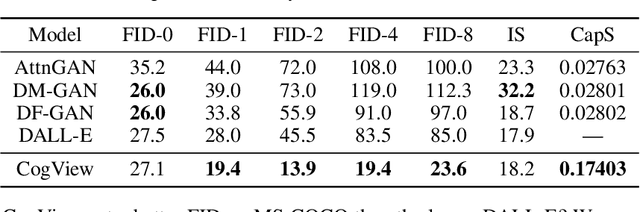
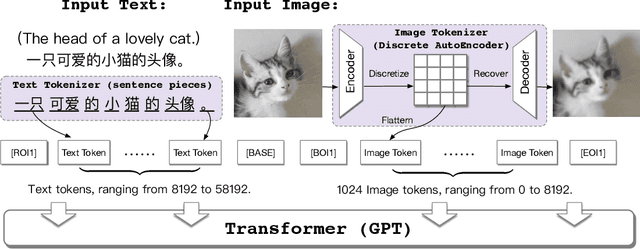

Text-to-Image generation in the general domain has long been an open problem, which requires both a powerful generative model and cross-modal understanding. We propose CogView, a 4-billion-parameter Transformer with VQ-VAE tokenizer to advance this problem. We also demonstrate the finetuning strategies for various downstream tasks, e.g. style learning, super-resolution, text-image ranking and fashion design, and methods to stabilize pretraining, e.g. eliminating NaN losses. CogView (zero-shot) achieves a new state-of-the-art FID on blurred MS COCO, outperforms previous GAN-based models and a recent similar work DALL-E.
Distributed High-dimensional Regression Under a Quantile Loss Function
Jun 13, 2019



This paper studies distributed estimation and support recovery for high-dimensional linear regression model with heavy-tailed noise. To deal with heavy-tailed noise whose variance can be infinite, we adopt the quantile regression loss function instead of the commonly used squared loss. However, the non-smooth quantile loss poses new challenges to high-dimensional distributed estimation in both computation and theoretical development. To address the challenge, we transform the response variable and establish a new connection between quantile regression and ordinary linear regression. Then, we provide a distributed estimator that is both computationally and communicationally efficient, where only the gradient information is communicated at each iteration. Theoretically, we show that, after a constant number of iterations, the proposed estimator achieves a near-oracle convergence rate without any restriction on the number of machines. Moreover, we establish the theoretical guarantee for the support recovery. The simulation analysis is provided to demonstrate the effectiveness of our method.
Distributed Inference for Linear Support Vector Machine
Nov 29, 2018



The growing size of modern data brings many new challenges to existing statistical inference methodologies and theories, and calls for the development of distributed inferential approaches. This paper studies distributed inference for linear support vector machine (SVM) for the binary classification task. Despite a vast literature on SVM, much less is known about the inferential properties of SVM, especially in a distributed setting. In this paper, we propose a multi-round distributed linear-type (MDL) estimator for conducting inference for linear SVM. The proposed estimator is computationally efficient. In particular, it only requires an initial SVM estimator and then successively refines the estimator by solving simple weighted least squares problem. Theoretically, we establish the Bahadur representation of the estimator. Based on the representation, the asymptotic normality is further derived, which shows that the MDL estimator achieves the optimal statistical efficiency, i.e., the same efficiency as the classical linear SVM applying to the entire dataset in a single machine setup. Moreover, our asymptotic result avoids the condition on the number of machines or data batches, which is commonly assumed in distributed estimation literature, and allows the case of diverging dimension. We provide simulation studies to demonstrate the performance of the proposed MDL estimator.