 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZibo Zhao
Non-Uniform Exposure Imaging via Neuromorphic Shutter Control
Apr 22, 2024
By leveraging the blur-noise trade-off, imaging with non-uniform exposures largely extends the image acquisition flexibility in harsh environments. However, the limitation of conventional cameras in perceiving intra-frame dynamic information prevents existing methods from being implemented in the real-world frame acquisition for real-time adaptive camera shutter control. To address this challenge, we propose a novel Neuromorphic Shutter Control (NSC) system to avoid motion blurs and alleviate instant noises, where the extremely low latency of events is leveraged to monitor the real-time motion and facilitate the scene-adaptive exposure. Furthermore, to stabilize the inconsistent Signal-to-Noise Ratio (SNR) caused by the non-uniform exposure times, we propose an event-based image denoising network within a self-supervised learning paradigm, i.e., SEID, exploring the statistics of image noises and inter-frame motion information of events to obtain artificial supervision signals for high-quality imaging in real-world scenes. To illustrate the effectiveness of the proposed NSC, we implement it in hardware by building a hybrid-camera imaging prototype system, with which we collect a real-world dataset containing well-synchronized frames and events in diverse scenarios with different target scenes and motion patterns. Experiments on the synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art approaches.
Apollonion: Profile-centric Dialog Agent
Apr 10, 2024The emergence of Large Language Models (LLMs) has innovated the development of dialog agents. Specially, a well-trained LLM, as a central process unit, is capable of providing fluent and reasonable response for user's request. Besides, auxiliary tools such as external knowledge retrieval, personalized character for vivid response, short/long-term memory for ultra long context management are developed, completing the usage experience for LLM-based dialog agents. However, the above-mentioned techniques does not solve the issue of \textbf{personalization from user perspective}: agents response in a same fashion to different users, without consideration of their features, such as habits, interests and past experience. In another words, current implementation of dialog agents fail in ``knowing the user''. The capacity of well-description and representation of user is under development. In this work, we proposed a framework for dialog agent to incorporate user profiling (initialization, update): user's query and response is analyzed and organized into a structural user profile, which is latter served to provide personal and more precise response. Besides, we proposed a series of evaluation protocols for personalization: to what extend the response is personal to the different users. The framework is named as \method{}, inspired by inscription of ``Know Yourself'' in the temple of Apollo (also known as \method{}) in Ancient Greek. Few works have been conducted on incorporating personalization into LLM, \method{} is a pioneer work on guiding LLM's response to meet individuation via the application of dialog agents, with a set of evaluation methods for measurement in personalization.
Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models
Dec 22, 2023This paper presents Paint3D, a novel coarse-to-fine generative framework that is capable of producing high-resolution, lighting-less, and diverse 2K UV texture maps for untextured 3D meshes conditioned on text or image inputs. The key challenge addressed is generating high-quality textures without embedded illumination information, which allows the textures to be re-lighted or re-edited within modern graphics pipelines. To achieve this, our method first leverages a pre-trained depth-aware 2D diffusion model to generate view-conditional images and perform multi-view texture fusion, producing an initial coarse texture map. However, as 2D models cannot fully represent 3D shapes and disable lighting effects, the coarse texture map exhibits incomplete areas and illumination artifacts. To resolve this, we train separate UV Inpainting and UVHD diffusion models specialized for the shape-aware refinement of incomplete areas and the removal of illumination artifacts. Through this coarse-to-fine process, Paint3D can produce high-quality 2K UV textures that maintain semantic consistency while being lighting-less, significantly advancing the state-of-the-art in texturing 3D objects.
ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Dec 01, 2023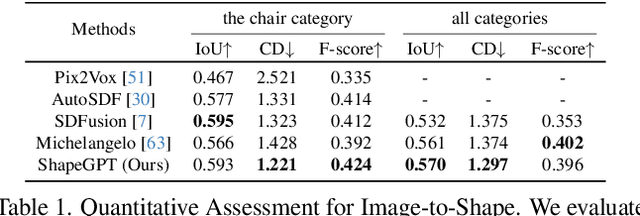
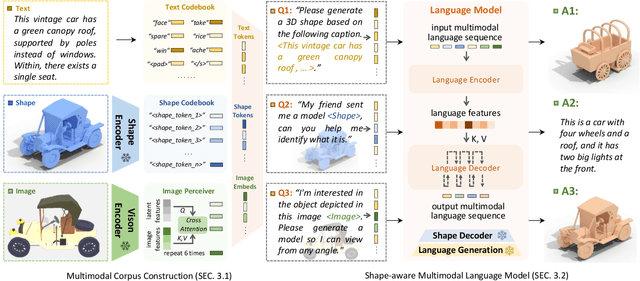
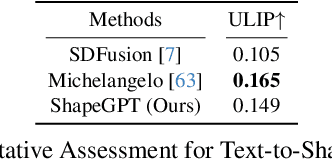
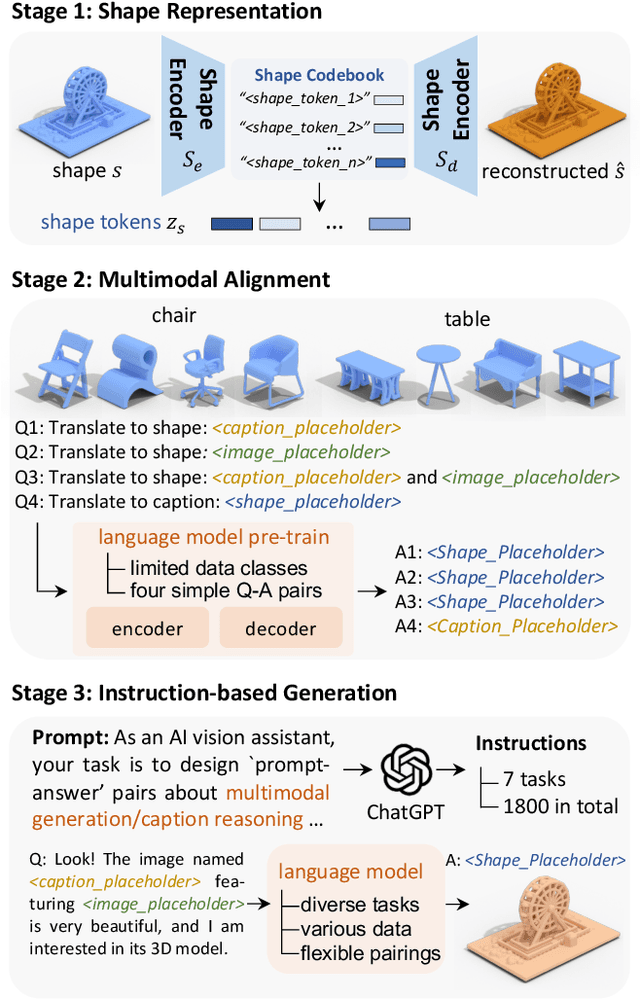
The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
TSP-Transformer: Task-Specific Prompts Boosted Transformer for Holistic Scene Understanding
Nov 06, 2023Holistic scene understanding includes semantic segmentation, surface normal estimation, object boundary detection, depth estimation, etc. The key aspect of this problem is to learn representation effectively, as each subtask builds upon not only correlated but also distinct attributes. Inspired by visual-prompt tuning, we propose a Task-Specific Prompts Transformer, dubbed TSP-Transformer, for holistic scene understanding. It features a vanilla transformer in the early stage and tasks-specific prompts transformer encoder in the lateral stage, where tasks-specific prompts are augmented. By doing so, the transformer layer learns the generic information from the shared parts and is endowed with task-specific capacity. First, the tasks-specific prompts serve as induced priors for each task effectively. Moreover, the task-specific prompts can be seen as switches to favor task-specific representation learning for different tasks. Extensive experiments on NYUD-v2 and PASCAL-Context show that our method achieves state-of-the-art performance, validating the effectiveness of our method for holistic scene understanding. We also provide our code in the following link https://github.com/tb2-sy/TSP-Transformer.
RoomDesigner: Encoding Anchor-latents for Style-consistent and Shape-compatible Indoor Scene Generation
Oct 16, 2023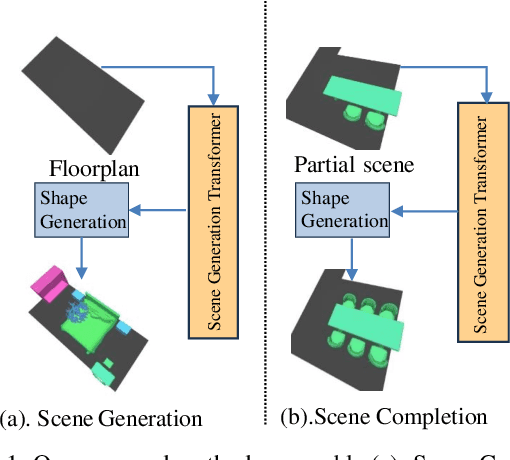
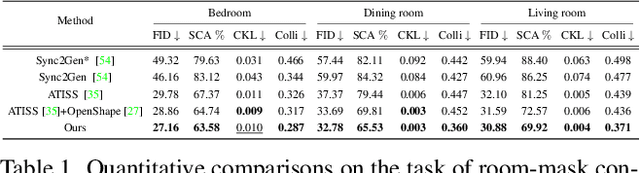
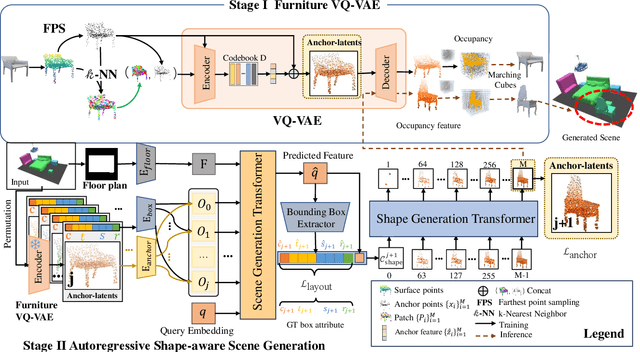
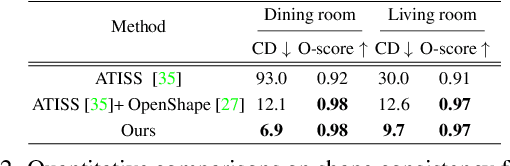
Indoor scene generation aims at creating shape-compatible, style-consistent furniture arrangements within a spatially reasonable layout. However, most existing approaches primarily focus on generating plausible furniture layouts without incorporating specific details related to individual furniture pieces. To address this limitation, we propose a two-stage model integrating shape priors into the indoor scene generation by encoding furniture as anchor latent representations. In the first stage, we employ discrete vector quantization to encode furniture pieces as anchor-latents. Based on the anchor-latents representation, the shape and location information of the furniture was characterized by a concatenation of location, size, orientation, class, and our anchor latent. In the second stage, we leverage a transformer model to predict indoor scenes autoregressively. Thanks to incorporating the proposed anchor-latents representations, our generative model produces shape-compatible and style-consistent furniture arrangements and synthesis furniture in diverse shapes. Furthermore, our method facilitates various human interaction applications, such as style-consistent scene completion, object mismatch correction, and controllable object-level editing. Experimental results on the 3D-Front dataset demonstrate that our approach can generate more consistent and compatible indoor scenes compared to existing methods, even without shape retrieval. Additionally, extensive ablation studies confirm the effectiveness of our design choices in the indoor scene generation model.
Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation
Jul 03, 2023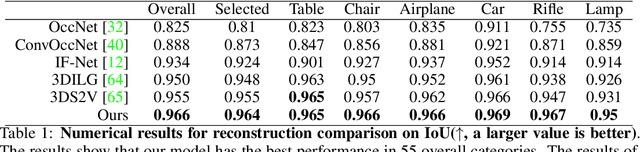
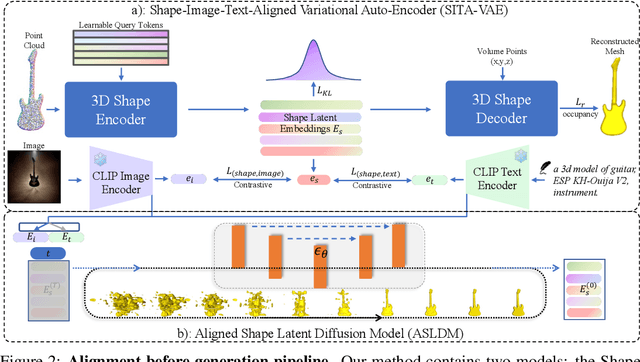
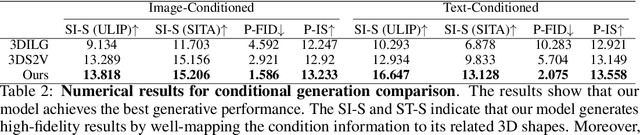

We present a novel alignment-before-generation approach to tackle the challenging task of generating general 3D shapes based on 2D images or texts. Directly learning a conditional generative model from images or texts to 3D shapes is prone to producing inconsistent results with the conditions because 3D shapes have an additional dimension whose distribution significantly differs from that of 2D images and texts. To bridge the domain gap among the three modalities and facilitate multi-modal-conditioned 3D shape generation, we explore representing 3D shapes in a shape-image-text-aligned space. Our framework comprises two models: a Shape-Image-Text-Aligned Variational Auto-Encoder (SITA-VAE) and a conditional Aligned Shape Latent Diffusion Model (ASLDM). The former model encodes the 3D shapes into the shape latent space aligned to the image and text and reconstructs the fine-grained 3D neural fields corresponding to given shape embeddings via the transformer-based decoder. The latter model learns a probabilistic mapping function from the image or text space to the latent shape space. Our extensive experiments demonstrate that our proposed approach can generate higher-quality and more diverse 3D shapes that better semantically conform to the visual or textural conditional inputs, validating the effectiveness of the shape-image-text-aligned space for cross-modality 3D shape generation.