 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongze Lian
DreamDrone
Dec 17, 2023
We introduce DreamDrone, an innovative method for generating unbounded flythrough scenes from textual prompts. Central to our method is a novel feature-correspondence-guidance diffusion process, which utilizes the strong correspondence of intermediate features in the diffusion model. Leveraging this guidance strategy, we further propose an advanced technique for editing the intermediate latent code, enabling the generation of subsequent novel views with geometric consistency. Extensive experiments reveal that DreamDrone significantly surpasses existing methods, delivering highly authentic scene generation with exceptional visual quality. This approach marks a significant step in zero-shot perpetual view generation from textual prompts, enabling the creation of diverse scenes, including natural landscapes like oases and caves, as well as complex urban settings such as Lego-style street views. Our code is publicly available.
TSP-Transformer: Task-Specific Prompts Boosted Transformer for Holistic Scene Understanding
Nov 06, 2023Holistic scene understanding includes semantic segmentation, surface normal estimation, object boundary detection, depth estimation, etc. The key aspect of this problem is to learn representation effectively, as each subtask builds upon not only correlated but also distinct attributes. Inspired by visual-prompt tuning, we propose a Task-Specific Prompts Transformer, dubbed TSP-Transformer, for holistic scene understanding. It features a vanilla transformer in the early stage and tasks-specific prompts transformer encoder in the lateral stage, where tasks-specific prompts are augmented. By doing so, the transformer layer learns the generic information from the shared parts and is endowed with task-specific capacity. First, the tasks-specific prompts serve as induced priors for each task effectively. Moreover, the task-specific prompts can be seen as switches to favor task-specific representation learning for different tasks. Extensive experiments on NYUD-v2 and PASCAL-Context show that our method achieves state-of-the-art performance, validating the effectiveness of our method for holistic scene understanding. We also provide our code in the following link https://github.com/tb2-sy/TSP-Transformer.
GraphAdapter: Tuning Vision-Language Models With Dual Knowledge Graph
Sep 24, 2023Adapter-style efficient transfer learning (ETL) has shown excellent performance in the tuning of vision-language models (VLMs) under the low-data regime, where only a few additional parameters are introduced to excavate the task-specific knowledge based on the general and powerful representation of VLMs. However, most adapter-style works face two limitations: (i) modeling task-specific knowledge with a single modality only; and (ii) overlooking the exploitation of the inter-class relationships in downstream tasks, thereby leading to sub-optimal solutions. To mitigate that, we propose an effective adapter-style tuning strategy, dubbed GraphAdapter, which performs the textual adapter by explicitly modeling the dual-modality structure knowledge (i.e., the correlation of different semantics/classes in textual and visual modalities) with a dual knowledge graph. In particular, the dual knowledge graph is established with two sub-graphs, i.e., a textual knowledge sub-graph, and a visual knowledge sub-graph, where the nodes and edges represent the semantics/classes and their correlations in two modalities, respectively. This enables the textual feature of each prompt to leverage the task-specific structure knowledge from both textual and visual modalities, yielding a more effective classifier for downstream tasks. Extensive experimental results on 11 benchmark datasets reveal that our GraphAdapter significantly outperforms previous adapter-based methods. The code will be released at https://github.com/lixinustc/GraphAdapter
Priority-Centric Human Motion Generation in Discrete Latent Space
Aug 30, 2023
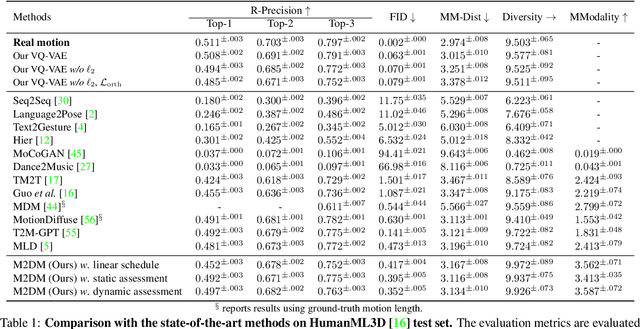
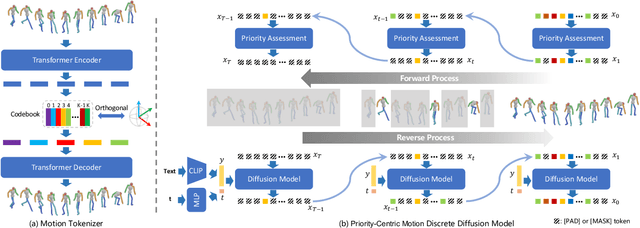
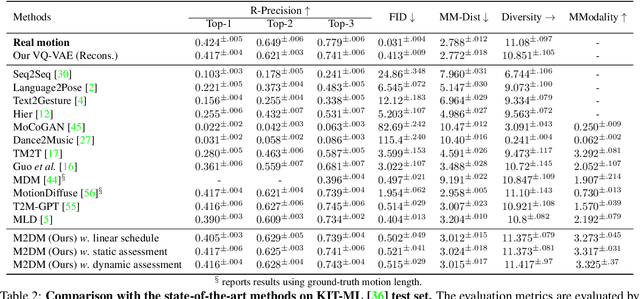
Text-to-motion generation is a formidable task, aiming to produce human motions that align with the input text while also adhering to human capabilities and physical laws. While there have been advancements in diffusion models, their application in discrete spaces remains underexplored. Current methods often overlook the varying significance of different motions, treating them uniformly. It is essential to recognize that not all motions hold the same relevance to a particular textual description. Some motions, being more salient and informative, should be given precedence during generation. In response, we introduce a Priority-Centric Motion Discrete Diffusion Model (M2DM), which utilizes a Transformer-based VQ-VAE to derive a concise, discrete motion representation, incorporating a global self-attention mechanism and a regularization term to counteract code collapse. We also present a motion discrete diffusion model that employs an innovative noise schedule, determined by the significance of each motion token within the entire motion sequence. This approach retains the most salient motions during the reverse diffusion process, leading to more semantically rich and varied motions. Additionally, we formulate two strategies to gauge the importance of motion tokens, drawing from both textual and visual indicators. Comprehensive experiments on the HumanML3D and KIT-ML datasets confirm that our model surpasses existing techniques in fidelity and diversity, particularly for intricate textual descriptions.
Dataset Quantization
Aug 21, 2023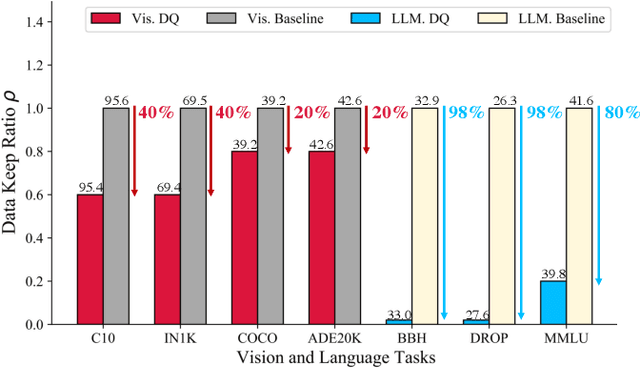



State-of-the-art deep neural networks are trained with large amounts (millions or even billions) of data. The expensive computation and memory costs make it difficult to train them on limited hardware resources, especially for recent popular large language models (LLM) and computer vision models (CV). Recent popular dataset distillation methods are thus developed, aiming to reduce the number of training samples via synthesizing small-scale datasets via gradient matching. However, as the gradient calculation is coupled with the specific network architecture, the synthesized dataset is biased and performs poorly when used for training unseen architectures. To address these limitations, we present dataset quantization (DQ), a new framework to compress large-scale datasets into small subsets which can be used for training any neural network architectures. Extensive experiments demonstrate that DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training. To the best of our knowledge, DQ is the first method that can successfully distill large-scale datasets such as ImageNet-1k with a state-of-the-art compression ratio. Notably, with 60% data from ImageNet and 20% data from Alpaca's instruction tuning data, the models can be trained with negligible or no performance drop for both vision tasks (including classification, semantic segmentation, and object detection) as well as language tasks (including instruction tuning tasks such as BBH and DROP).
Revisiting Event-based Video Frame Interpolation
Jul 24, 2023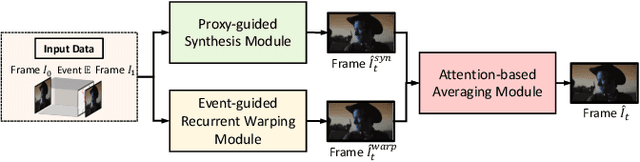
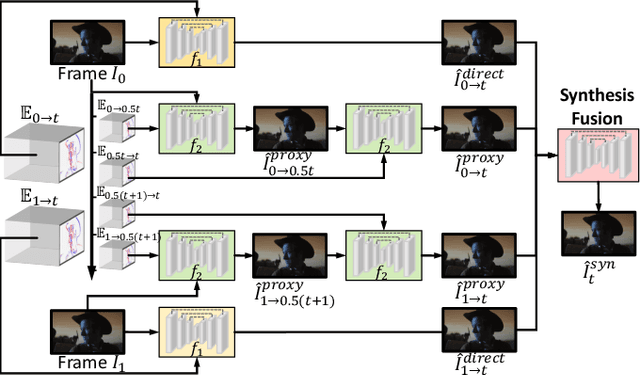
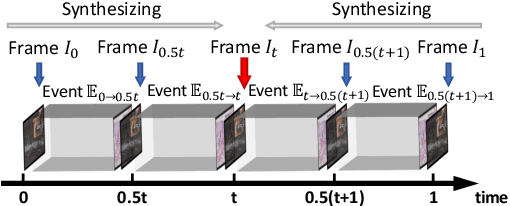
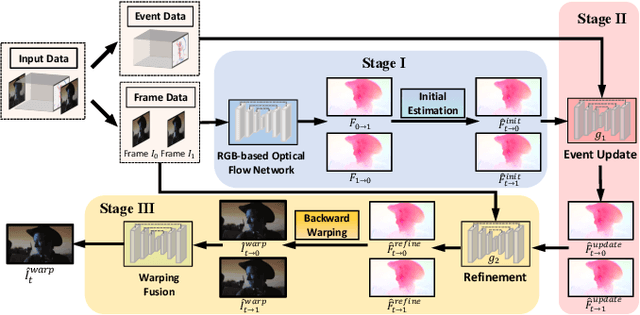
Dynamic vision sensors or event cameras provide rich complementary information for video frame interpolation. Existing state-of-the-art methods follow the paradigm of combining both synthesis-based and warping networks. However, few of those methods fully respect the intrinsic characteristics of events streams. Given that event cameras only encode intensity changes and polarity rather than color intensities, estimating optical flow from events is arguably more difficult than from RGB information. We therefore propose to incorporate RGB information in an event-guided optical flow refinement strategy. Moreover, in light of the quasi-continuous nature of the time signals provided by event cameras, we propose a divide-and-conquer strategy in which event-based intermediate frame synthesis happens incrementally in multiple simplified stages rather than in a single, long stage. Extensive experiments on both synthetic and real-world datasets show that these modifications lead to more reliable and realistic intermediate frame results than previous video frame interpolation methods. Our findings underline that a careful consideration of event characteristics such as high temporal density and elevated noise benefits interpolation accuracy.
TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration
Apr 05, 2023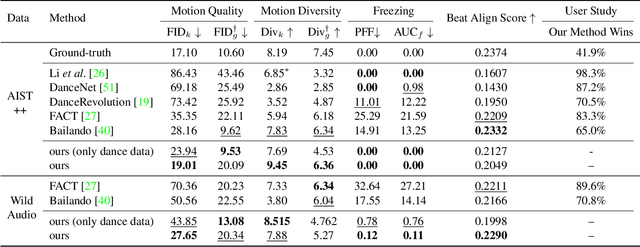
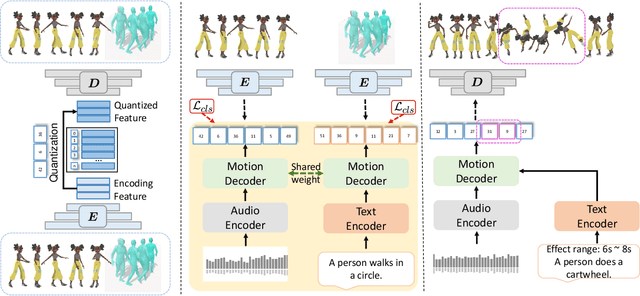

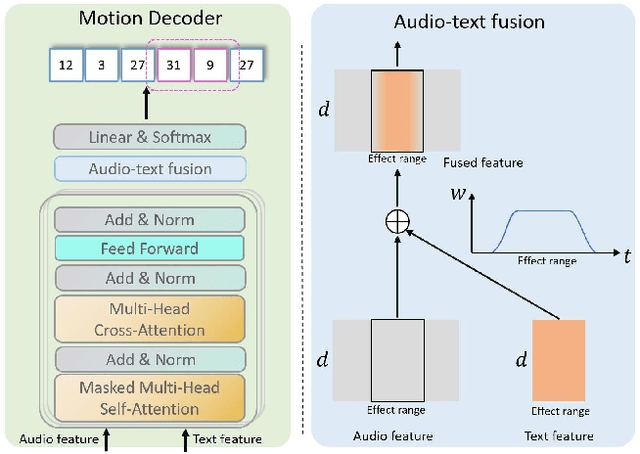
We propose a novel task for generating 3D dance movements that simultaneously incorporate both text and music modalities. Unlike existing works that generate dance movements using a single modality such as music, our goal is to produce richer dance movements guided by the instructive information provided by the text. However, the lack of paired motion data with both music and text modalities limits the ability to generate dance movements that integrate both. To alleviate this challenge, we propose to utilize a 3D human motion VQ-VAE to project the motions of the two datasets into a latent space consisting of quantized vectors, which effectively mix the motion tokens from the two datasets with different distributions for training. Additionally, we propose a cross-modal transformer to integrate text instructions into motion generation architecture for generating 3D dance movements without degrading the performance of music-conditioned dance generation. To better evaluate the quality of the generated motion, we introduce two novel metrics, namely Motion Prediction Distance (MPD) and Freezing Score, to measure the coherence and freezing percentage of the generated motion. Extensive experiments show that our approach can generate realistic and coherent dance movements conditioned on both text and music while maintaining comparable performance with the two single modalities. Code will be available at: https://garfield-kh.github.io/TM2D/.
Weakly Supervised Video Representation Learning with Unaligned Text for Sequential Videos
Mar 28, 2023



Sequential video understanding, as an emerging video understanding task, has driven lots of researchers' attention because of its goal-oriented nature. This paper studies weakly supervised sequential video understanding where the accurate time-stamp level text-video alignment is not provided. We solve this task by borrowing ideas from CLIP. Specifically, we use a transformer to aggregate frame-level features for video representation and use a pre-trained text encoder to encode the texts corresponding to each action and the whole video, respectively. To model the correspondence between text and video, we propose a multiple granularity loss, where the video-paragraph contrastive loss enforces matching between the whole video and the complete script, and a fine-grained frame-sentence contrastive loss enforces the matching between each action and its description. As the frame-sentence correspondence is not available, we propose to use the fact that video actions happen sequentially in the temporal domain to generate pseudo frame-sentence correspondence and supervise the network training with the pseudo labels. Extensive experiments on video sequence verification and text-to-video matching show that our method outperforms baselines by a large margin, which validates the effectiveness of our proposed approach. Code is available at https://github.com/svip-lab/WeakSVR
iQuery: Instruments as Queries for Audio-Visual Sound Separation
Dec 08, 2022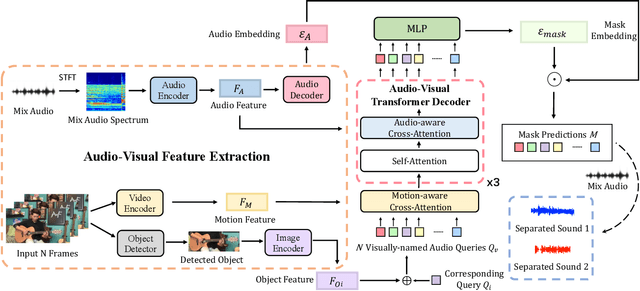
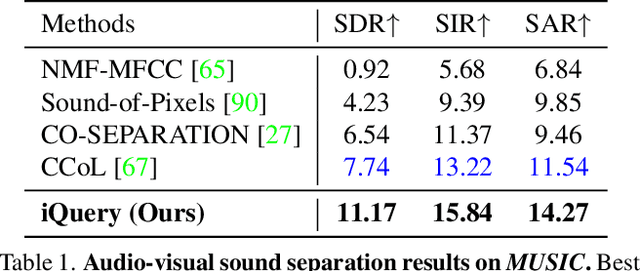
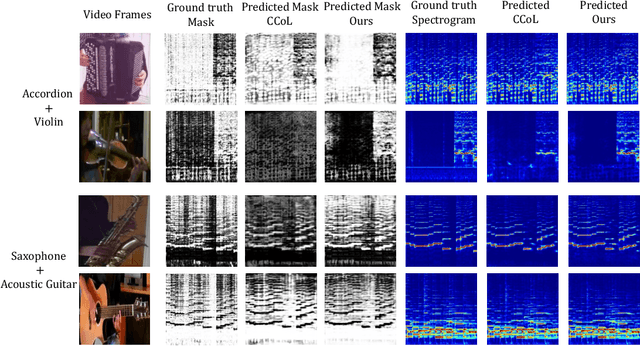
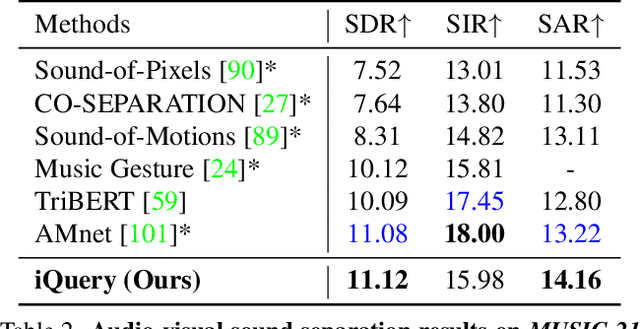
Current audio-visual separation methods share a standard architecture design where an audio encoder-decoder network is fused with visual encoding features at the encoder bottleneck. This design confounds the learning of multi-modal feature encoding with robust sound decoding for audio separation. To generalize to a new instrument: one must finetune the entire visual and audio network for all musical instruments. We re-formulate visual-sound separation task and propose Instrument as Query (iQuery) with a flexible query expansion mechanism. Our approach ensures cross-modal consistency and cross-instrument disentanglement. We utilize "visually named" queries to initiate the learning of audio queries and use cross-modal attention to remove potential sound source interference at the estimated waveforms. To generalize to a new instrument or event class, drawing inspiration from the text-prompt design, we insert an additional query as an audio prompt while freezing the attention mechanism. Experimental results on three benchmarks demonstrate that our iQuery improves audio-visual sound source separation performance.
Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning
Oct 17, 2022



Existing fine-tuning methods either tune all parameters of the pre-trained model (full fine-tuning), which is not efficient, or only tune the last linear layer (linear probing), which suffers a significant accuracy drop compared to the full fine-tuning. In this paper, we propose a new parameter-efficient fine-tuning method termed as SSF, representing that researchers only need to Scale and Shift the deep Features extracted by a pre-trained model to catch up with the performance of full fine-tuning. In this way, SSF also surprisingly outperforms other parameter-efficient fine-tuning approaches even with a smaller number of tunable parameters. Furthermore, different from some existing parameter-efficient fine-tuning methods (e.g., Adapter or VPT) that introduce the extra parameters and computational cost in the training and inference stages, SSF only adds learnable parameters during the training stage, and these additional parameters can be merged into the original pre-trained model weights via re-parameterization in the inference phase. With the proposed SSF, our model obtains 2.46% (90.72% vs. 88.54%) and 11.48% (73.10% vs. 65.57%) performance improvement on FGVC and VTAB-1k in terms of Top-1 accuracy compared to the full fine-tuning but only fine-tuning about 0.3M parameters. We also conduct amounts of experiments in various model families (CNNs, Transformers, and MLPs) and datasets. Results on 26 image classification datasets in total and 3 robustness & out-of-distribution datasets show the effectiveness of SSF. Code is available at https://github.com/dongzelian/SSF.