 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZichao Li
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Apr 16, 2024
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
Evaluating Dependencies in Fact Editing for Language Models: Specificity and Implication Awareness
Dec 04, 2023The potential of using a large language model (LLM) as a knowledge base (KB) has sparked significant interest. To manage the knowledge acquired by LLMs, we need to ensure that the editing of learned facts respects internal logical constraints, which are known as dependency of knowledge. Existing work on editing LLMs has partially addressed the issue of dependency, when the editing of a fact should apply to its lexical variations without disrupting irrelevant ones. However, they neglect the dependency between a fact and its logical implications. We propose an evaluation protocol with an accompanying question-answering dataset, DepEdit, that provides a comprehensive assessment of the editing process considering the above notions of dependency. Our protocol involves setting up a controlled environment in which we edit facts and monitor their impact on LLMs, along with their implications based on If-Then rules. Extensive experiments on DepEdit show that existing knowledge editing methods are sensitive to the surface form of knowledge, and that they have limited performance in inferring the implications of edited facts.
f-Divergence Minimization for Sequence-Level Knowledge Distillation
Jul 27, 2023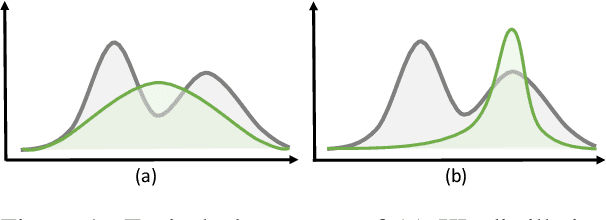
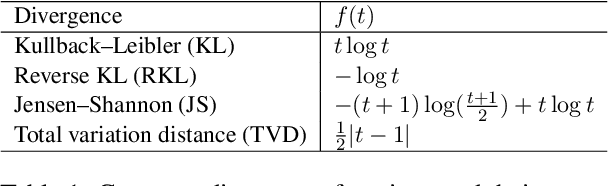
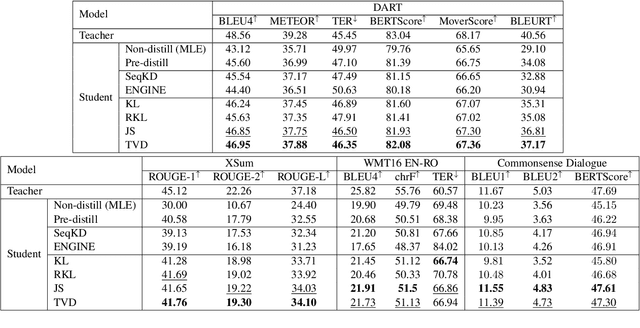
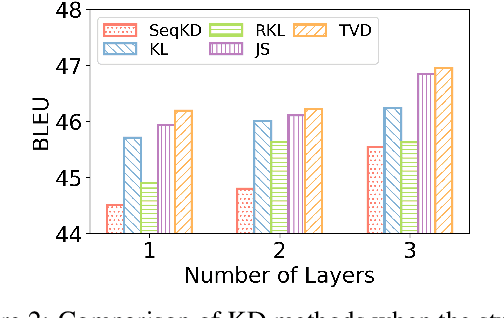
Knowledge distillation (KD) is the process of transferring knowledge from a large model to a small one. It has gained increasing attention in the natural language processing community, driven by the demands of compressing ever-growing language models. In this work, we propose an f-DISTILL framework, which formulates sequence-level knowledge distillation as minimizing a generalized f-divergence function. We propose four distilling variants under our framework and show that existing SeqKD and ENGINE approaches are approximations of our f-DISTILL methods. We further derive step-wise decomposition for our f-DISTILL, reducing intractable sequence-level divergence to word-level losses that can be computed in a tractable manner. Experiments across four datasets show that our methods outperform existing KD approaches, and that our symmetric distilling losses can better force the student to learn from the teacher distribution.
Tied-Augment: Controlling Representation Similarity Improves Data Augmentation
May 22, 2023
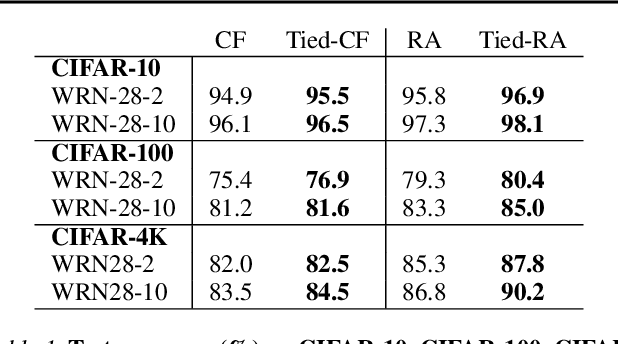
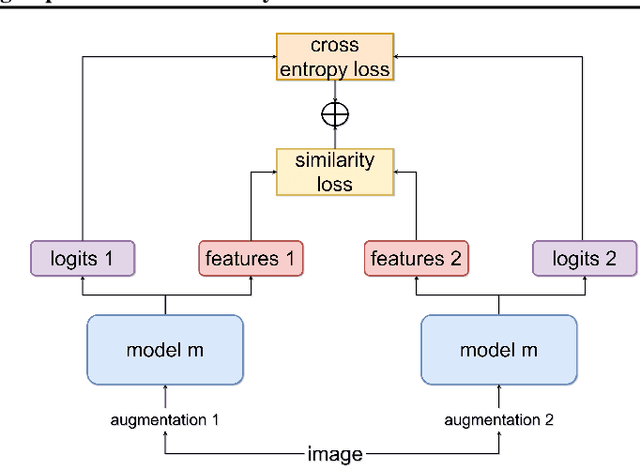
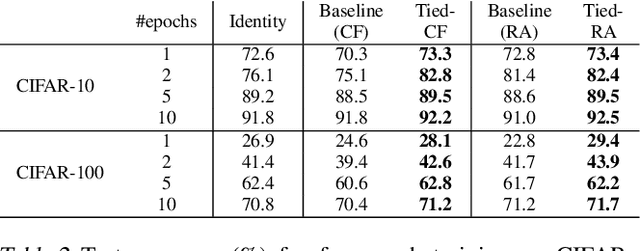
Data augmentation methods have played an important role in the recent advance of deep learning models, and have become an indispensable component of state-of-the-art models in semi-supervised, self-supervised, and supervised training for vision. Despite incurring no additional latency at test time, data augmentation often requires more epochs of training to be effective. For example, even the simple flips-and-crops augmentation requires training for more than 5 epochs to improve performance, whereas RandAugment requires more than 90 epochs. We propose a general framework called Tied-Augment, which improves the efficacy of data augmentation in a wide range of applications by adding a simple term to the loss that can control the similarity of representations under distortions. Tied-Augment can improve state-of-the-art methods from data augmentation (e.g. RandAugment, mixup), optimization (e.g. SAM), and semi-supervised learning (e.g. FixMatch). For example, Tied-RandAugment can outperform RandAugment by 2.0% on ImageNet. Notably, using Tied-Augment, data augmentation can be made to improve generalization even when training for a few epochs and when fine-tuning. We open source our code at https://github.com/ekurtulus/tied-augment/tree/main.
On the Adversarial Robustness of Camera-based 3D Object Detection
Jan 25, 2023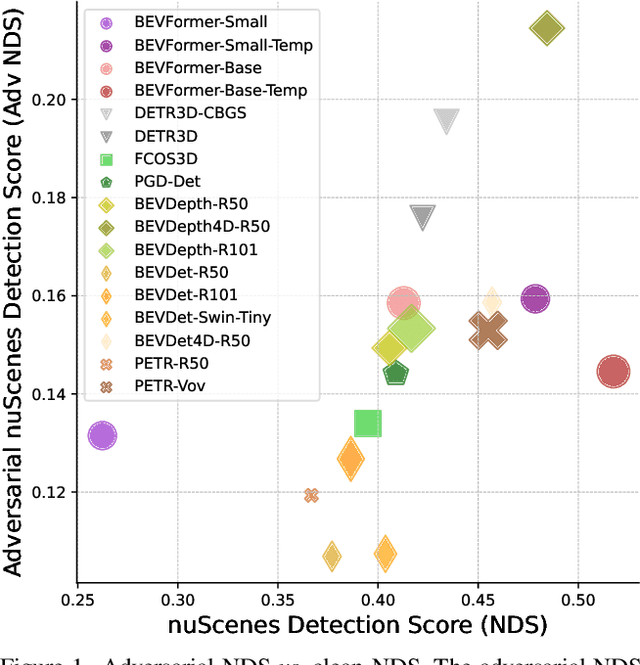
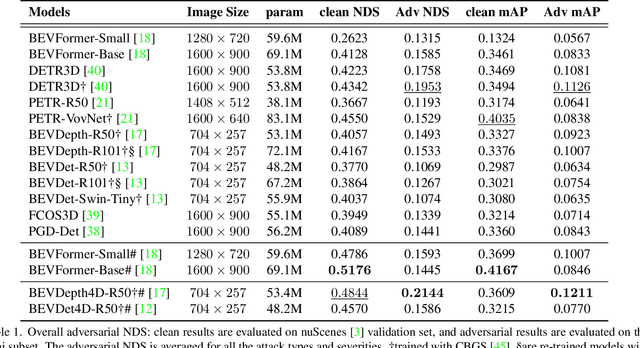

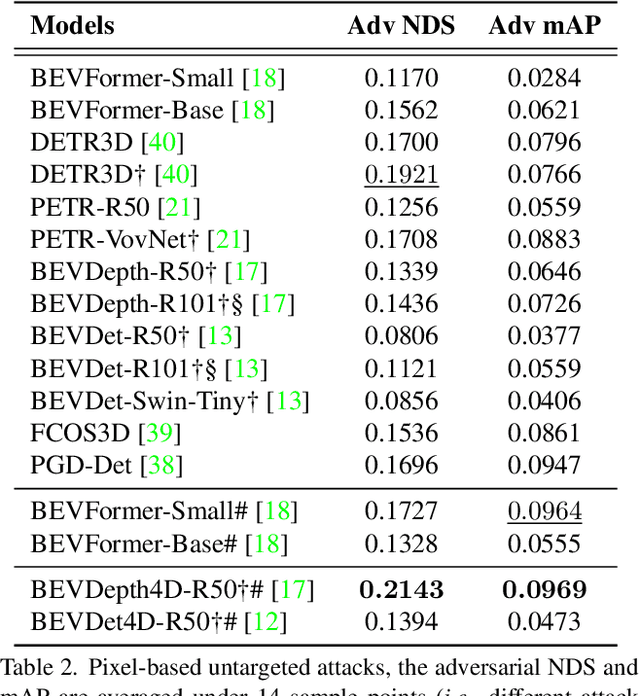
In recent years, camera-based 3D object detection has gained widespread attention for its ability to achieve high performance with low computational cost. However, the robustness of these methods to adversarial attacks has not been thoroughly examined. In this study, we conduct the first comprehensive investigation of the robustness of leading camera-based 3D object detection methods under various adversarial conditions. Our experiments reveal five interesting findings: (a) the use of accurate depth estimation effectively improves robustness; (b) depth-estimation-free approaches do not show superior robustness; (c) bird's-eye-view-based representations exhibit greater robustness against localization attacks; (d) incorporating multi-frame benign inputs can effectively mitigate adversarial attacks; and (e) addressing long-tail problems can enhance robustness. We hope our work can provide guidance for the design of future camera-based object detection modules with improved adversarial robustness.
Bag of Tricks for FGSM Adversarial Training
Sep 06, 2022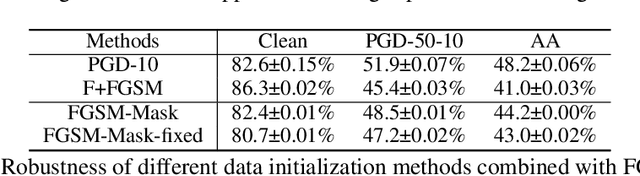
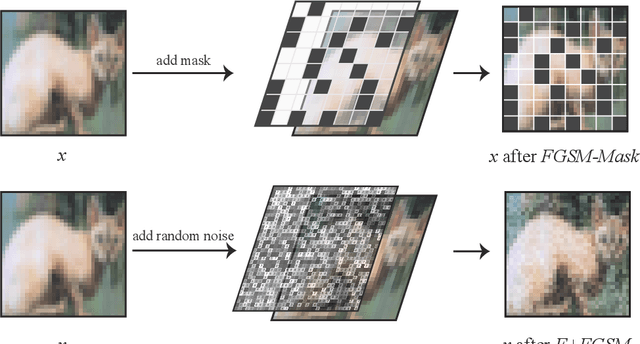
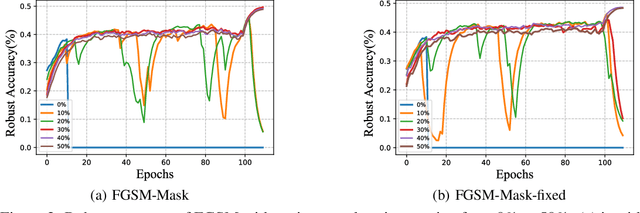
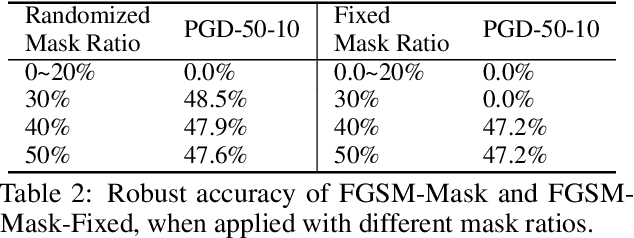
Adversarial training (AT) with samples generated by Fast Gradient Sign Method (FGSM), also known as FGSM-AT, is a computationally simple method to train robust networks. However, during its training procedure, an unstable mode of "catastrophic overfitting" has been identified in arXiv:2001.03994 [cs.LG], where the robust accuracy abruptly drops to zero within a single training step. Existing methods use gradient regularizers or random initialization tricks to attenuate this issue, whereas they either take high computational cost or lead to lower robust accuracy. In this work, we provide the first study, which thoroughly examines a collection of tricks from three perspectives: Data Initialization, Network Structure, and Optimization, to overcome the catastrophic overfitting in FGSM-AT. Surprisingly, we find that simple tricks, i.e., a) masking partial pixels (even without randomness), b) setting a large convolution stride and smooth activation functions, or c) regularizing the weights of the first convolutional layer, can effectively tackle the overfitting issue. Extensive results on a range of network architectures validate the effectiveness of each proposed trick, and the combinations of tricks are also investigated. For example, trained with PreActResNet-18 on CIFAR-10, our method attains 49.8% accuracy against PGD-50 attacker and 46.4% accuracy against AutoAttack, demonstrating that pure FGSM-AT is capable of enabling robust learners. The code and models are publicly available at https://github.com/UCSC-VLAA/Bag-of-Tricks-for-FGSM-AT.
Text Revision by On-the-Fly Representation Optimization
Apr 15, 2022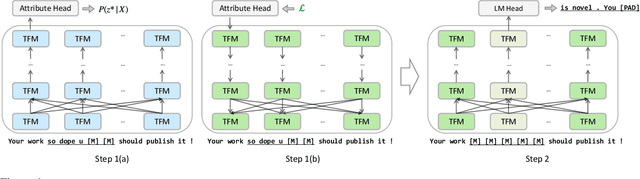
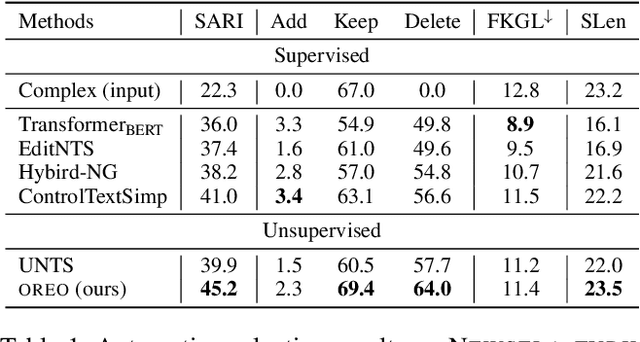
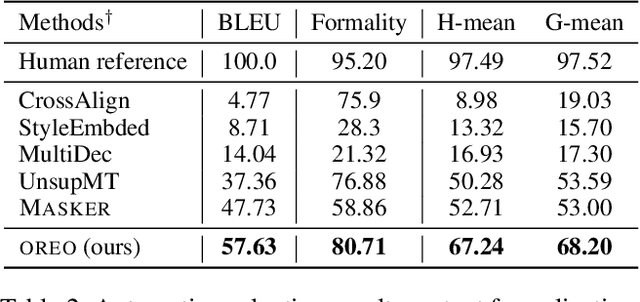
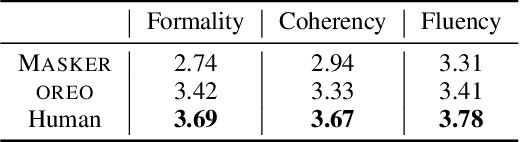
Text revision refers to a family of natural language generation tasks, where the source and target sequences share moderate resemblance in surface form but differentiate in attributes, such as text formality and simplicity. Current state-of-the-art methods formulate these tasks as sequence-to-sequence learning problems, which rely on large-scale parallel training corpus. In this paper, we present an iterative in-place editing approach for text revision, which requires no parallel data. In this approach, we simply fine-tune a pre-trained Transformer with masked language modeling and attribute classification. During inference, the editing at each iteration is realized by two-step span replacement. At the first step, the distributed representation of the text optimizes on the fly towards an attribute function. At the second step, a text span is masked and another new one is proposed conditioned on the optimized representation. The empirical experiments on two typical and important text revision tasks, text formalization and text simplification, show the effectiveness of our approach. It achieves competitive and even better performance than state-of-the-art supervised methods on text simplification, and gains better performance than strong unsupervised methods on text formalization \footnote{Code and model are available at \url{https://github.com/jingjingli01/OREO}}.
Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment
Apr 06, 2022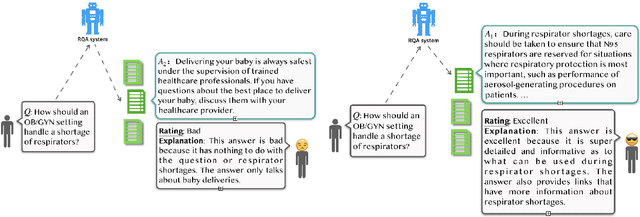
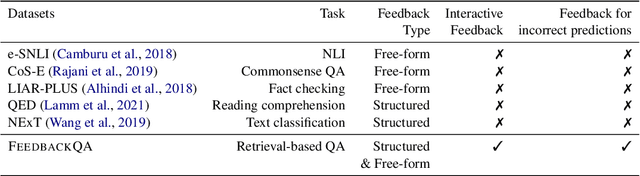
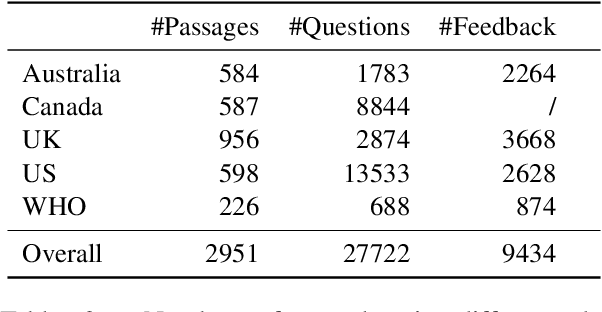
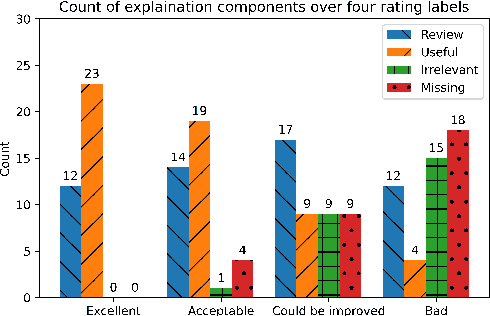
Most research on question answering focuses on the pre-deployment stage; i.e., building an accurate model for deployment. In this paper, we ask the question: Can we improve QA systems further \emph{post-}deployment based on user interactions? We focus on two kinds of improvements: 1) improving the QA system's performance itself, and 2) providing the model with the ability to explain the correctness or incorrectness of an answer. We collect a retrieval-based QA dataset, FeedbackQA, which contains interactive feedback from users. We collect this dataset by deploying a base QA system to crowdworkers who then engage with the system and provide feedback on the quality of its answers. The feedback contains both structured ratings and unstructured natural language explanations. We train a neural model with this feedback data that can generate explanations and re-score answer candidates. We show that feedback data not only improves the accuracy of the deployed QA system but also other stronger non-deployed systems. The generated explanations also help users make informed decisions about the correctness of answers. Project page: https://mcgill-nlp.github.io/feedbackqa/
Beam Search for Feature Selection
Mar 08, 2022



In this paper, we present and prove some consistency results about the performance of classification models using a subset of features. In addition, we propose to use beam search to perform feature selection, which can be viewed as a generalization of forward selection. We apply beam search to both simulated and real-world data, by evaluating and comparing the performance of different classification models using different sets of features. The results demonstrate that beam search could outperform forward selection, especially when the features are correlated so that they have more discriminative power when considered jointly than individually. Moreover, in some cases classification models could obtain comparable performance using only ten features selected by beam search instead of hundreds of original features.