 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZidong Cao
Learning High-Quality Navigation and Zooming on Omnidirectional Images in Virtual Reality
May 01, 2024
Viewing omnidirectional images (ODIs) in virtual reality (VR) represents a novel form of media that provides immersive experiences for users to navigate and interact with digital content. Nonetheless, this sense of immersion can be greatly compromised by a blur effect that masks details and hampers the user's ability to engage with objects of interest. In this paper, we present a novel system, called OmniVR, designed to enhance visual clarity during VR navigation. Our system enables users to effortlessly locate and zoom in on the objects of interest in VR. It captures user commands for navigation and zoom, converting these inputs into parameters for the Mobius transformation matrix. Leveraging these parameters, the ODI is refined using a learning-based algorithm. The resultant ODI is presented within the VR media, effectively reducing blur and increasing user engagement. To verify the effectiveness of our system, we first evaluate our algorithm with state-of-the-art methods on public datasets, which achieves the best performance. Furthermore, we undertake a comprehensive user study to evaluate viewer experiences across diverse scenarios and to gather their qualitative feedback from multiple perspectives. The outcomes reveal that our system enhances user engagement by improving the viewers' recognition, reducing discomfort, and improving the overall immersive experience. Our system makes the navigation and zoom more user-friendly.
Dream360: Diverse and Immersive Outdoor Virtual Scene Creation via Transformer-Based 360 Image Outpainting
Jan 19, 2024360 images, with a field-of-view (FoV) of 180x360, provide immersive and realistic environments for emerging virtual reality (VR) applications, such as virtual tourism, where users desire to create diverse panoramic scenes from a narrow FoV photo they take from a viewpoint via portable devices. It thus brings us to a technical challenge: `How to allow the users to freely create diverse and immersive virtual scenes from a narrow FoV image with a specified viewport?' To this end, we propose a transformer-based 360 image outpainting framework called Dream360, which can generate diverse, high-fidelity, and high-resolution panoramas from user-selected viewports, considering the spherical properties of 360 images. Compared with existing methods, e.g., [3], which primarily focus on inputs with rectangular masks and central locations while overlooking the spherical property of 360 images, our Dream360 offers higher outpainting flexibility and fidelity based on the spherical representation. Dream360 comprises two key learning stages: (I) codebook-based panorama outpainting via Spherical-VQGAN (S-VQGAN), and (II) frequency-aware refinement with a novel frequency-aware consistency loss. Specifically, S-VQGAN learns a sphere-specific codebook from spherical harmonic (SH) values, providing a better representation of spherical data distribution for scene modeling. The frequency-aware refinement matches the resolution and further improves the semantic consistency and visual fidelity of the generated results. Our Dream360 achieves significantly lower Frechet Inception Distance (FID) scores and better visual fidelity than existing methods. We also conducted a user study involving 15 participants to interactively evaluate the quality of the generated results in VR, demonstrating the flexibility and superiority of our Dream360 framework.
Hi-Map: Hierarchical Factorized Radiance Field for High-Fidelity Monocular Dense Mapping
Jan 06, 2024In this paper, we introduce Hi-Map, a novel monocular dense mapping approach based on Neural Radiance Field (NeRF). Hi-Map is exceptional in its capacity to achieve efficient and high-fidelity mapping using only posed RGB inputs. Our method eliminates the need for external depth priors derived from e.g., a depth estimation model. Our key idea is to represent the scene as a hierarchical feature grid that encodes the radiance and then factorizes it into feature planes and vectors. As such, the scene representation becomes simpler and more generalizable for fast and smooth convergence on new observations. This allows for efficient computation while alleviating noise patterns by reducing the complexity of the scene representation. Buttressed by the hierarchical factorized representation, we leverage the Sign Distance Field (SDF) as a proxy of rendering for inferring the volume density, demonstrating high mapping fidelity. Moreover, we introduce a dual-path encoding strategy to strengthen the photometric cues and further boost the mapping quality, especially for the distant and textureless regions. Extensive experiments demonstrate our method's superiority in geometric and textural accuracy over the state-of-the-art NeRF-based monocular mapping methods.
SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events
Sep 22, 2023



Monocular depth estimation is a crucial task to measure distance relative to a camera, which is important for applications, such as robot navigation and self-driving. Traditional frame-based methods suffer from performance drops due to the limited dynamic range and motion blur. Therefore, recent works leverage novel event cameras to complement or guide the frame modality via frame-event feature fusion. However, event streams exhibit spatial sparsity, leaving some areas unperceived, especially in regions with marginal light changes. Therefore, direct fusion methods, e.g., RAMNet, often ignore the contribution of the most confident regions of each modality. This leads to structural ambiguity in the modality fusion process, thus degrading the depth estimation performance. In this paper, we propose a novel Spatial Reliability-oriented Fusion Network (SRFNet), that can estimate depth with fine-grained structure at both daytime and nighttime. Our method consists of two key technical components. Firstly, we propose an attention-based interactive fusion (AIF) module that applies spatial priors of events and frames as the initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused feature are then fed back to enhance the frame and event feature learning. Meanwhile, it utilizes an output head to generate a fused mask, which is iteratively updated for learning consensual spatial priors. Secondly, we propose the Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with the fine-grained structure based on the fused features and masks. We evaluate the effectiveness of our method on the synthetic and real-world datasets, which shows that, even without pretraining, our method outperforms the prior methods, e.g., RAMNet, especially in night scenes. Our project homepage: https://vlislab22.github.io/SRFNet.
OmniZoomer: Learning to Move and Zoom in on Sphere at High-Resolution
Aug 19, 2023



Omnidirectional images (ODIs) have become increasingly popular, as their large field-of-view (FoV) can offer viewers the chance to freely choose the view directions in immersive environments such as virtual reality. The M\"obius transformation is typically employed to further provide the opportunity for movement and zoom on ODIs, but applying it to the image level often results in blurry effect and aliasing problem. In this paper, we propose a novel deep learning-based approach, called \textbf{OmniZoomer}, to incorporate the M\"obius transformation into the network for movement and zoom on ODIs. By learning various transformed feature maps under different conditions, the network is enhanced to handle the increasing edge curvatures, which alleviates the blurry effect. Moreover, to address the aliasing problem, we propose two key components. Firstly, to compensate for the lack of pixels for describing curves, we enhance the feature maps in the high-resolution (HR) space and calculate the transformed index map with a spatial index generation module. Secondly, considering that ODIs are inherently represented in the spherical space, we propose a spherical resampling module that combines the index map and HR feature maps to transform the feature maps for better spherical correlation. The transformed feature maps are decoded to output a zoomed ODI. Experiments show that our method can produce HR and high-quality ODIs with the flexibility to move and zoom in to the object of interest. Project page is available at http://vlislab22.github.io/OmniZoomer/.
FMapping: Factorized Efficient Neural Field Mapping for Real-Time Dense RGB SLAM
Jun 01, 2023



In this paper, we introduce FMapping, an efficient neural field mapping framework that facilitates the continuous estimation of a colorized point cloud map in real-time dense RGB SLAM. To achieve this challenging goal without depth, a hurdle is how to improve efficiency and reduce the mapping uncertainty of the RGB SLAM system. To this end, we first build up a theoretical analysis by decomposing the SLAM system into tracking and mapping parts, and the mapping uncertainty is explicitly defined within the frame of neural representations. Based on the analysis, we then propose an effective factorization scheme for scene representation and introduce a sliding window strategy to reduce the uncertainty for scene reconstruction. Specifically, we leverage the factorized neural field to decompose uncertainty into a lower-dimensional space, which enhances robustness to noise and improves training efficiency. We then propose the sliding window sampler to reduce uncertainty by incorporating coherent geometric cues from observed frames during map initialization to enhance convergence. Our factorized neural mapping approach enjoys some advantages, such as low memory consumption, more efficient computation, and fast convergence during map initialization. Experiments on two benchmark datasets show that our method can update the map of high-fidelity colorized point clouds around 2 seconds in real time while requiring no customized CUDA kernels. Additionally, it utilizes x20 fewer parameters than the most concise neural implicit mapping of prior methods for SLAM, e.g., iMAP [ 31] and around x1000 fewer parameters than the state-of-the-art approach, e.g., NICE-SLAM [ 42]. For more details, please refer to our project homepage: https://vlis2022.github.io/fmap/.
360$^\circ$ High-Resolution Depth Estimation via Uncertainty-aware Structural Knowledge Transfer
Apr 17, 2023



Recently, omnidirectional images (ODIs) have become increasingly popular; however, their angular resolution tends to be lower than that of perspective images.This leads to degraded structural details such as edges, causing difficulty in learning 3D scene understanding tasks, especially monocular depth estimation. Existing methods typically leverage high-resolution (HR) ODI as the input, so as to recover the structural details via fully-supervised learning. However, the HR depth ground truth (GT) maps may be arduous or expensive to be collected due to resource-constrained devices in practice. Therefore, in this paper, we explore for the first time to estimate the HR omnidirectional depth directly from a low-resolution (LR) ODI, when no HR depth GT map is available. Our key idea is to transfer the scene structural knowledge from the readily available HR image modality and the corresponding LR depth maps to achieve the goal of HR depth estimation without extra inference cost. Specifically, we introduce ODI super-resolution (SR) as an auxiliary task and train both tasks collaboratively in a weakly supervised manner to boost the performance of HR depth estimation. The ODI SR task takes an LR ODI as the input to predict an HR image, enabling us to extract the scene structural knowledge via uncertainty estimation. Buttressed by this, a scene structural knowledge transfer (SSKT) module is proposed with two key components. First, we employ a cylindrical implicit interpolation function (CIIF) to learn cylindrical neural interpolation weights for feature up-sampling and share the parameters of CIIFs between the two tasks. Then, we propose a feature distillation (FD) loss that provides extra structural regularization to help the HR depth estimation task learn more scene structural knowledge.
Both Style and Distortion Matter: Dual-Path Unsupervised Domain Adaptation for Panoramic Semantic Segmentation
Mar 25, 2023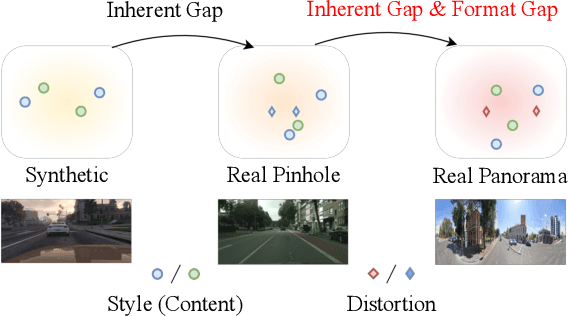
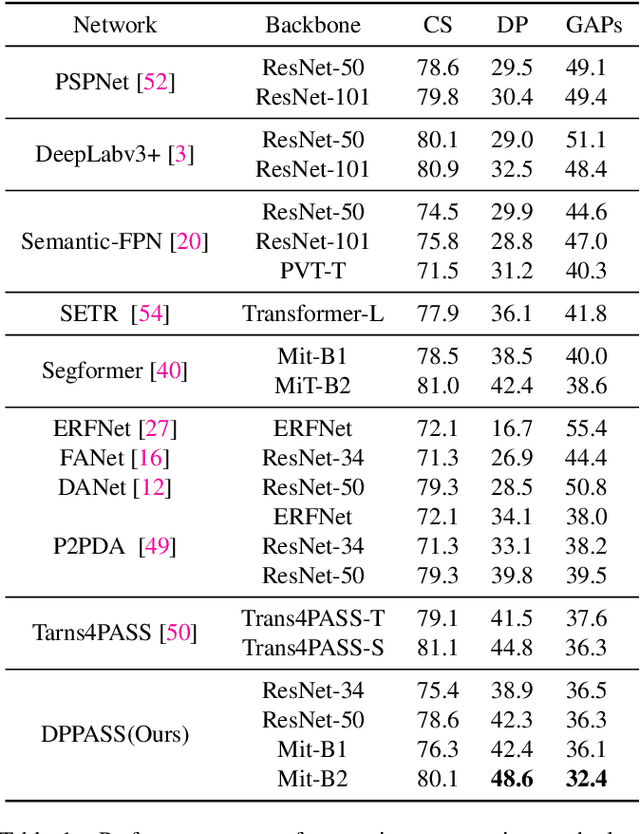
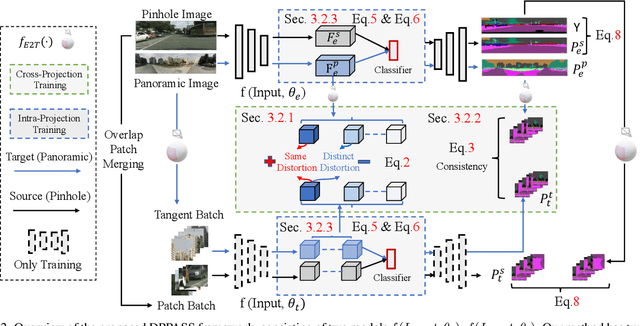
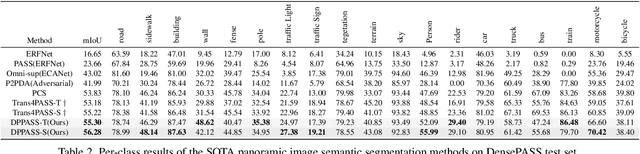
The ability of scene understanding has sparked active research for panoramic image semantic segmentation. However, the performance is hampered by distortion of the equirectangular projection (ERP) and a lack of pixel-wise annotations. For this reason, some works treat the ERP and pinhole images equally and transfer knowledge from the pinhole to ERP images via unsupervised domain adaptation (UDA). However, they fail to handle the domain gaps caused by: 1) the inherent differences between camera sensors and captured scenes; 2) the distinct image formats (e.g., ERP and pinhole images). In this paper, we propose a novel yet flexible dual-path UDA framework, DPPASS, taking ERP and tangent projection (TP) images as inputs. To reduce the domain gaps, we propose cross-projection and intra-projection training. The cross-projection training includes tangent-wise feature contrastive training and prediction consistency training. That is, the former formulates the features with the same projection locations as positive examples and vice versa, for the models' awareness of distortion, while the latter ensures the consistency of cross-model predictions between the ERP and TP. Moreover, adversarial intra-projection training is proposed to reduce the inherent gap, between the features of the pinhole images and those of the ERP and TP images, respectively. Importantly, the TP path can be freely removed after training, leading to no additional inference cost. Extensive experiments on two benchmarks show that our DPPASS achieves +1.06$\%$ mIoU increment than the state-of-the-art approaches.
Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
May 24, 2022



Omnidirectional image (ODI) data is captured with a 360x180 field-of-view, which is much wider than the pinhole cameras and contains richer spatial information than the conventional planar images. Accordingly, omnidirectional vision has attracted booming attention due to its more advantageous performance in numerous applications, such as autonomous driving and virtual reality. In recent years, the availability of customer-level 360 cameras has made omnidirectional vision more popular, and the advance of deep learning (DL) has significantly sparked its research and applications. This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Our work covers four main contents: (i) An introduction to the principle of omnidirectional imaging, the convolution methods on the ODI, and datasets to highlight the differences and difficulties compared with the 2D planar image data; (ii) A structural and hierarchical taxonomy of the DL methods for omnidirectional vision; (iii) A summarization of the latest novel learning strategies and applications; (iv) An insightful discussion of the challenges and open problems by highlighting the potential research directions to trigger more research in the community.