 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihao Xiao
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024
3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
Learning Part Segmentation from Synthetic Animals
Nov 30, 2023Semantic part segmentation provides an intricate and interpretable understanding of an object, thereby benefiting numerous downstream tasks. However, the need for exhaustive annotations impedes its usage across diverse object types. This paper focuses on learning part segmentation from synthetic animals, leveraging the Skinned Multi-Animal Linear (SMAL) models to scale up existing synthetic data generated by computer-aided design (CAD) animal models. Compared to CAD models, SMAL models generate data with a wider range of poses observed in real-world scenarios. As a result, our first contribution is to construct a synthetic animal dataset of tigers and horses with more pose diversity, termed Synthetic Animal Parts (SAP). We then benchmark Syn-to-Real animal part segmentation from SAP to PartImageNet, namely SynRealPart, with existing semantic segmentation domain adaptation methods and further improve them as our second contribution. Concretely, we examine three Syn-to-Real adaptation methods but observe relative performance drop due to the innate difference between the two tasks. To address this, we propose a simple yet effective method called Class-Balanced Fourier Data Mixing (CB-FDM). Fourier Data Mixing aligns the spectral amplitudes of synthetic images with real images, thereby making the mixed images have more similar frequency content to real images. We further use Class-Balanced Pseudo-Label Re-Weighting to alleviate the imbalanced class distribution. We demonstrate the efficacy of CB-FDM on SynRealPart over previous methods with significant performance improvements. Remarkably, our third contribution is to reveal that the learned parts from synthetic tiger and horse are transferable across all quadrupeds in PartImageNet, further underscoring the utility and potential applications of animal part segmentation.
Self-Supervised Transformer with Domain Adaptive Reconstruction for General Face Forgery Video Detection
Sep 09, 2023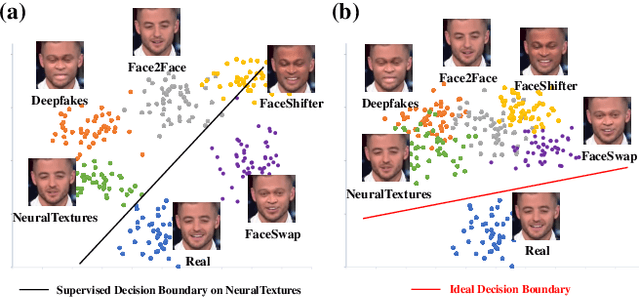
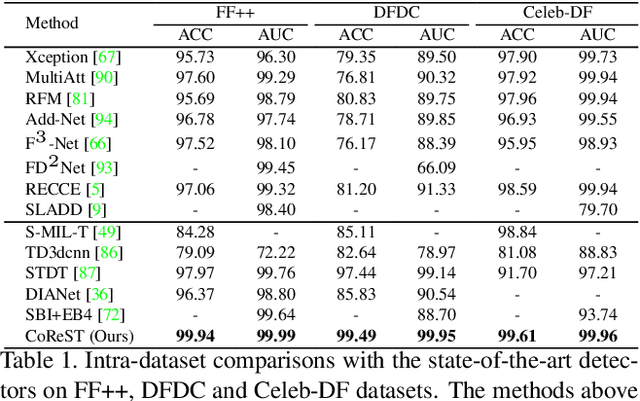
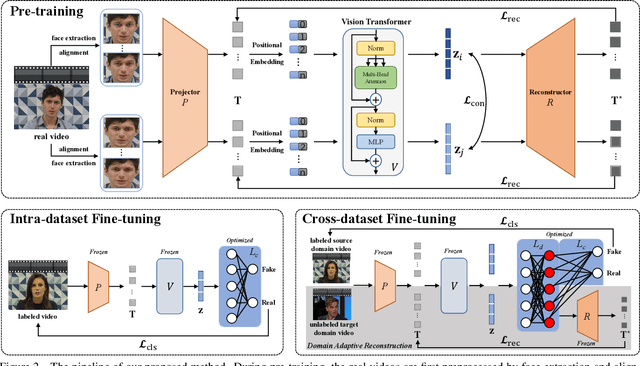
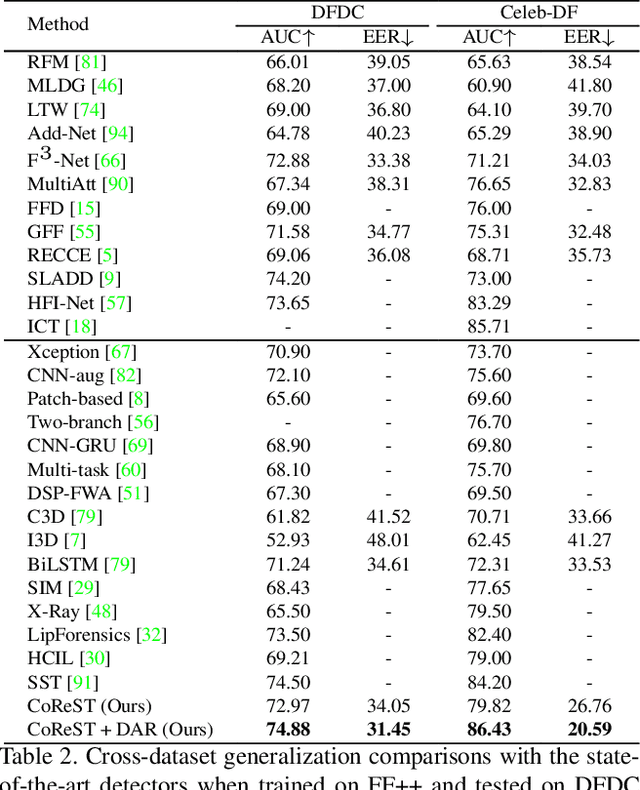
Face forgery videos have caused severe social public concern, and various detectors have been proposed recently. However, most of them are trained in a supervised manner with limited generalization when detecting videos from different forgery methods or real source videos. To tackle this issue, we explore to take full advantage of the difference between real and forgery videos by only exploring the common representation of real face videos. In this paper, a Self-supervised Transformer cooperating with Contrastive and Reconstruction learning (CoReST) is proposed, which is first pre-trained only on real face videos in a self-supervised manner, and then fine-tuned a linear head on specific face forgery video datasets. Two specific auxiliary tasks incorporated contrastive and reconstruction learning are designed to enhance the representation learning. Furthermore, a Domain Adaptive Reconstruction (DAR) module is introduced to bridge the gap between different forgery domains by reconstructing on unlabeled target videos when fine-tuning. Extensive experiments on public datasets demonstrate that our proposed method performs even better than the state-of-the-art supervised competitors with impressive generalization.
PREIM3D: 3D Consistent Precise Image Attribute Editing from a Single Image
Apr 20, 2023
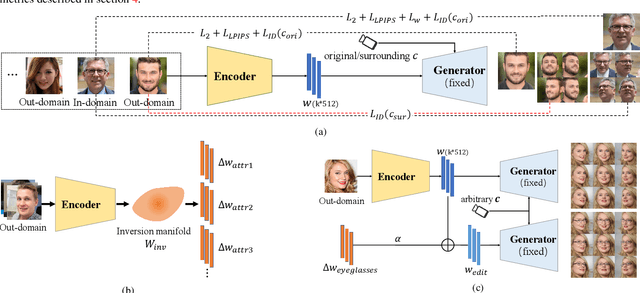
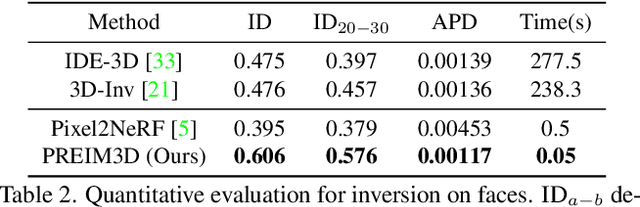
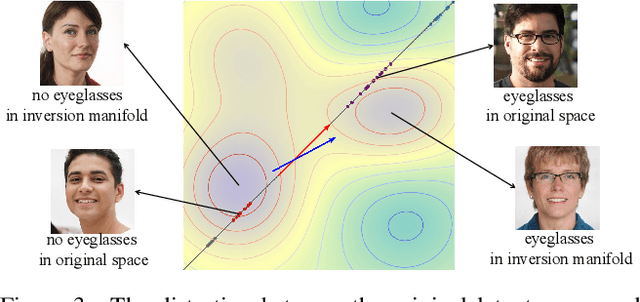
We study the 3D-aware image attribute editing problem in this paper, which has wide applications in practice. Recent methods solved the problem by training a shared encoder to map images into a 3D generator's latent space or by per-image latent code optimization and then edited images in the latent space. Despite their promising results near the input view, they still suffer from the 3D inconsistency of produced images at large camera poses and imprecise image attribute editing, like affecting unspecified attributes during editing. For more efficient image inversion, we train a shared encoder for all images. To alleviate 3D inconsistency at large camera poses, we propose two novel methods, an alternating training scheme and a multi-view identity loss, to maintain 3D consistency and subject identity. As for imprecise image editing, we attribute the problem to the gap between the latent space of real images and that of generated images. We compare the latent space and inversion manifold of GAN models and demonstrate that editing in the inversion manifold can achieve better results in both quantitative and qualitative evaluations. Extensive experiments show that our method produces more 3D consistent images and achieves more precise image editing than previous work. Source code and pretrained models can be found on our project page: https://mybabyyh.github.io/Preim3D/
Generating Adversarial Examples with Better Transferability via Masking Unimportant Parameters of Surrogate Model
Apr 14, 2023
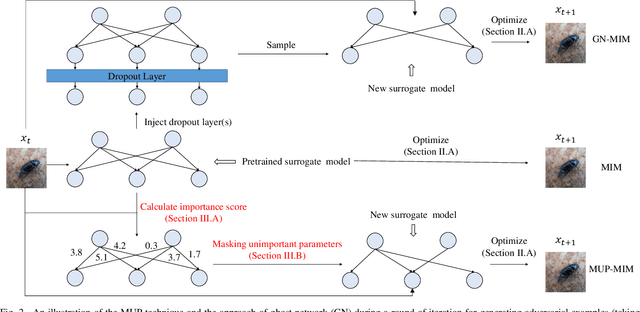
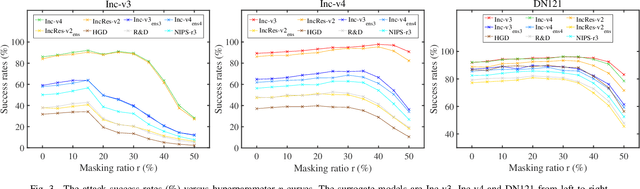
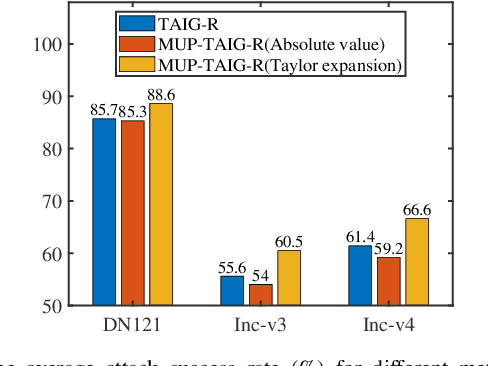
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples. Moreover, the transferability of the adversarial examples has received broad attention in recent years, which means that adversarial examples crafted by a surrogate model can also attack unknown models. This phenomenon gave birth to the transfer-based adversarial attacks, which aim to improve the transferability of the generated adversarial examples. In this paper, we propose to improve the transferability of adversarial examples in the transfer-based attack via masking unimportant parameters (MUP). The key idea in MUP is to refine the pretrained surrogate models to boost the transfer-based attack. Based on this idea, a Taylor expansion-based metric is used to evaluate the parameter importance score and the unimportant parameters are masked during the generation of adversarial examples. This process is simple, yet can be naturally combined with various existing gradient-based optimizers for generating adversarial examples, thus further improving the transferability of the generated adversarial examples. Extensive experiments are conducted to validate the effectiveness of the proposed MUP-based methods.
Learning Road Scene-level Representations via Semantic Region Prediction
Jan 02, 2023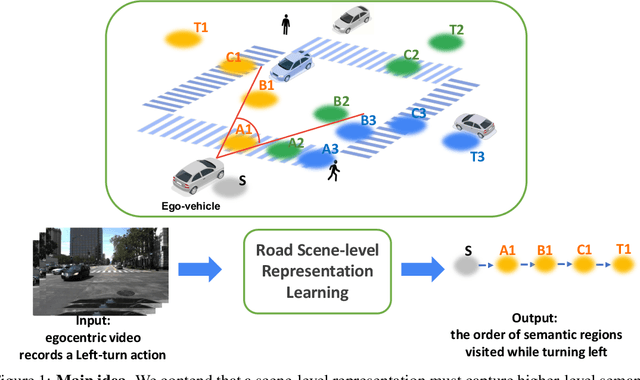
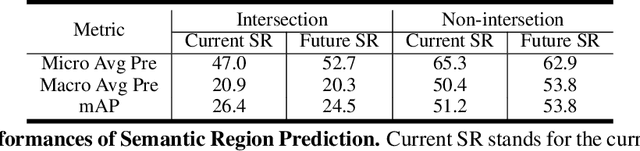
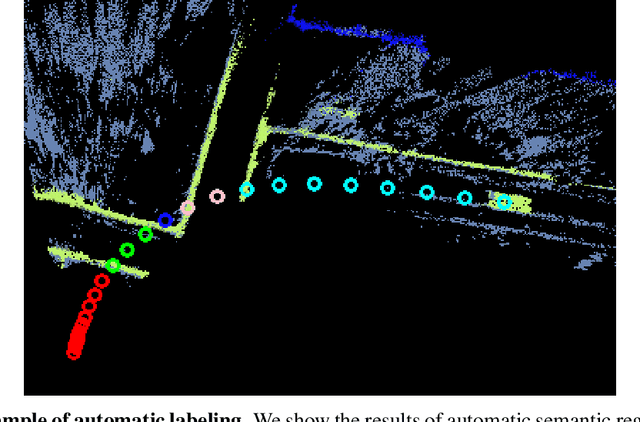
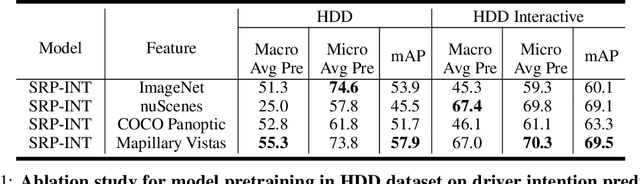
In this work, we tackle two vital tasks in automated driving systems, i.e., driver intent prediction and risk object identification from egocentric images. Mainly, we investigate the question: what would be good road scene-level representations for these two tasks? We contend that a scene-level representation must capture higher-level semantic and geometric representations of traffic scenes around ego-vehicle while performing actions to their destinations. To this end, we introduce the representation of semantic regions, which are areas where ego-vehicles visit while taking an afforded action (e.g., left-turn at 4-way intersections). We propose to learn scene-level representations via a novel semantic region prediction task and an automatic semantic region labeling algorithm. Extensive evaluations are conducted on the HDD and nuScenes datasets, and the learned representations lead to state-of-the-art performance for driver intention prediction and risk object identification.
Boosting the Adversarial Transferability of Surrogate Model with Dark Knowledge
Jun 16, 2022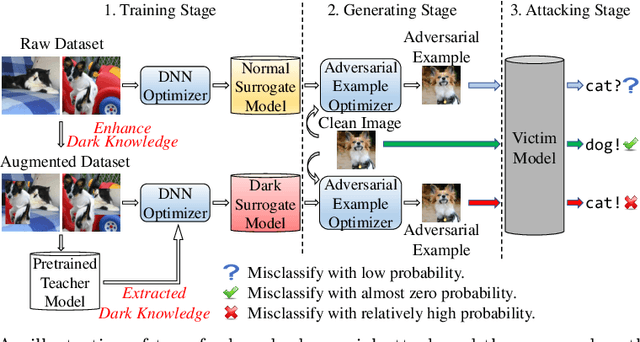
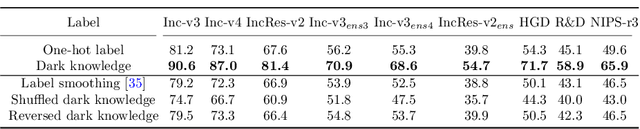
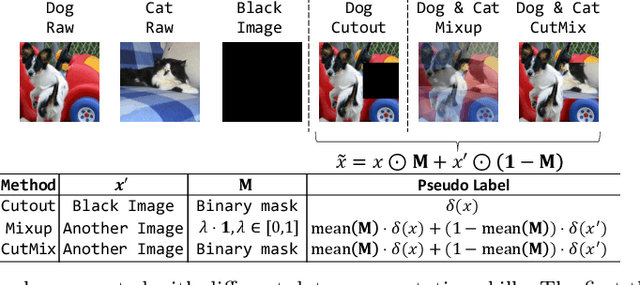
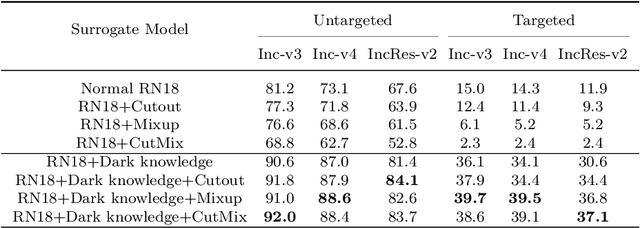
Deep neural networks (DNNs) for image classification are known to be vulnerable to adversarial examples. And, the adversarial examples have transferability, which means an adversarial example for a DNN model can fool another black-box model with a non-trivial probability. This gave birth of the transfer-based adversarial attack where the adversarial examples generated by a pretrained or known model (called surrogate model) are used to conduct black-box attack. There are some work on how to generate the adversarial examples from a given surrogate model to achieve better transferability. However, training a special surrogate model to generate adversarial examples with better transferability is relatively under-explored. In this paper, we propose a method of training a surrogate model with abundant dark knowledge to boost the adversarial transferability of the adversarial examples generated by the surrogate model. This trained surrogate model is named dark surrogate model (DSM), and the proposed method to train DSM consists of two key components: a teacher model extracting dark knowledge and providing soft labels, and the mixing augmentation skill which enhances the dark knowledge of training data. Extensive experiments have been conducted to show that the proposed method can substantially improve the adversarial transferability of surrogate model across different architectures of surrogate model and optimizers for generating adversarial examples. We also show that the proposed method can be applied to other scenarios of transfer-based attack that contain dark knowledge, like face verification.
Controllable Evaluation and Generation of Physical Adversarial Patch on Face Recognition
Mar 10, 2022
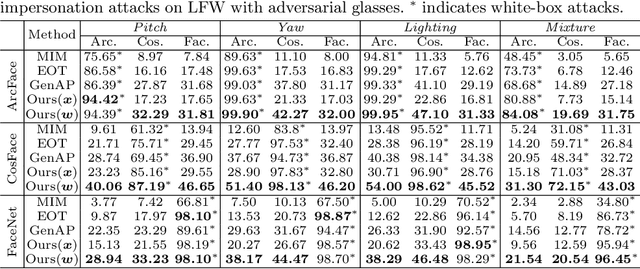
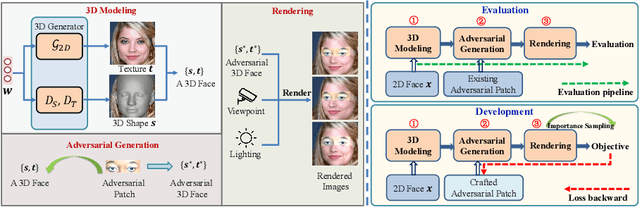
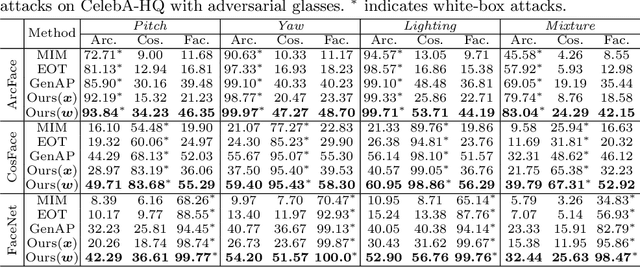
Recent studies have revealed the vulnerability of face recognition models against physical adversarial patches, which raises security concerns about the deployed face recognition systems. However, it is still challenging to ensure the reproducibility for most attack algorithms under complex physical conditions, which leads to the lack of a systematic evaluation of the existing methods. It is therefore imperative to develop a framework that can enable a comprehensive evaluation of the vulnerability of face recognition in the physical world. To this end, we propose to simulate the complex transformations of faces in the physical world via 3D-face modeling, which serves as a digital counterpart of physical faces. The generic framework allows us to control different face variations and physical conditions to conduct reproducible evaluations comprehensively. With this digital simulator, we further propose a Face3DAdv method considering the 3D face transformations and realistic physical variations. Extensive experiments validate that Face3DAdv can significantly improve the effectiveness of diverse physically realizable adversarial patches in both simulated and physical environments, against various white-box and black-box face recognition models.
Nuisance-Label Supervision: Robustness Improvement by Free Labels
Oct 14, 2021
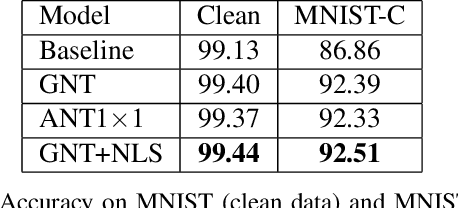
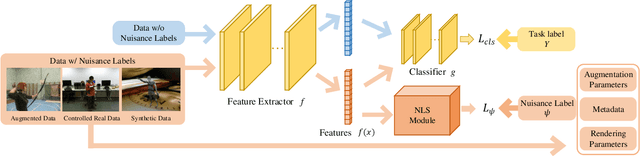

In this paper, we present a Nuisance-label Supervision (NLS) module, which can make models more robust to nuisance factor variations. Nuisance factors are those irrelevant to a task, and an ideal model should be invariant to them. For example, an activity recognition model should perform consistently regardless of the change of clothes and background. But our experiments show existing models are far from this capability. So we explicitly supervise a model with nuisance labels to make extracted features less dependent on nuisance factors. Although the values of nuisance factors are rarely annotated, we demonstrate that besides existing annotations, nuisance labels can be acquired freely from data augmentation and synthetic data. Experiments show consistent improvement in robustness towards image corruption and appearance change in action recognition.
Improving Transferability of Adversarial Patches on Face Recognition with Generative Models
Jun 29, 2021
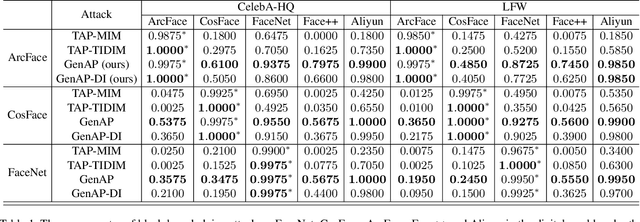
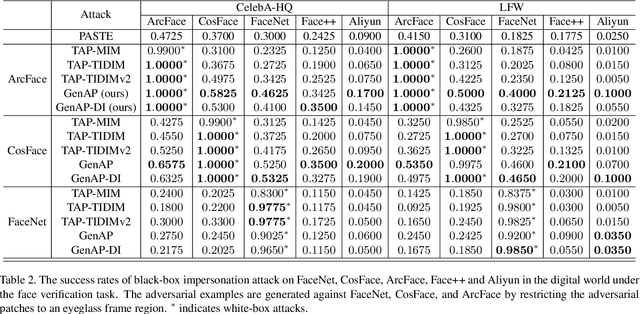
Face recognition is greatly improved by deep convolutional neural networks (CNNs). Recently, these face recognition models have been used for identity authentication in security sensitive applications. However, deep CNNs are vulnerable to adversarial patches, which are physically realizable and stealthy, raising new security concerns on the real-world applications of these models. In this paper, we evaluate the robustness of face recognition models using adversarial patches based on transferability, where the attacker has limited accessibility to the target models. First, we extend the existing transfer-based attack techniques to generate transferable adversarial patches. However, we observe that the transferability is sensitive to initialization and degrades when the perturbation magnitude is large, indicating the overfitting to the substitute models. Second, we propose to regularize the adversarial patches on the low dimensional data manifold. The manifold is represented by generative models pre-trained on legitimate human face images. Using face-like features as adversarial perturbations through optimization on the manifold, we show that the gaps between the responses of substitute models and the target models dramatically decrease, exhibiting a better transferability. Extensive digital world experiments are conducted to demonstrate the superiority of the proposed method in the black-box setting. We apply the proposed method in the physical world as well.