 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihao Zhang
LocalTweets to LocalHealth: A Mental Health Surveillance Framework Based on Twitter Data
Feb 21, 2024
Prior research on Twitter (now X) data has provided positive evidence of its utility in developing supplementary health surveillance systems. In this study, we present a new framework to surveil public health, focusing on mental health (MH) outcomes. We hypothesize that locally posted tweets are indicative of local MH outcomes and collect tweets posted from 765 neighborhoods (census block groups) in the USA. We pair these tweets from each neighborhood with the corresponding MH outcome reported by the Center for Disease Control (CDC) to create a benchmark dataset, LocalTweets. With LocalTweets, we present the first population-level evaluation task for Twitter-based MH surveillance systems. We then develop an efficient and effective method, LocalHealth, for predicting MH outcomes based on LocalTweets. When used with GPT3.5, LocalHealth achieves the highest F1-score and accuracy of 0.7429 and 79.78\%, respectively, a 59\% improvement in F1-score over the GPT3.5 in zero-shot setting. We also utilize LocalHealth to extrapolate CDC's estimates to proxy unreported neighborhoods, achieving an F1-score of 0.7291. Our work suggests that Twitter data can be effectively leveraged to simulate neighborhood-level MH outcomes.
VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
Nov 30, 2023Diffusion models have achieved significant success in image and video generation. This motivates a growing interest in video editing tasks, where videos are edited according to provided text descriptions. However, most existing approaches only focus on video editing for short clips and rely on time-consuming tuning or inference. We are the first to propose Video Instruction Diffusion (VIDiff), a unified foundation model designed for a wide range of video tasks. These tasks encompass both understanding tasks (such as language-guided video object segmentation) and generative tasks (video editing and enhancement). Our model can edit and translate the desired results within seconds based on user instructions. Moreover, we design an iterative auto-regressive method to ensure consistency in editing and enhancing long videos. We provide convincing generative results for diverse input videos and written instructions, both qualitatively and quantitatively. More examples can be found at our website https://ChenHsing.github.io/VIDiff.
EHRTutor: Enhancing Patient Understanding of Discharge Instructions
Oct 30, 2023Large language models have shown success as a tutor in education in various fields. Educating patients about their clinical visits plays a pivotal role in patients' adherence to their treatment plans post-discharge. This paper presents EHRTutor, an innovative multi-component framework leveraging the Large Language Model (LLM) for patient education through conversational question-answering. EHRTutor first formulates questions pertaining to the electronic health record discharge instructions. It then educates the patient through conversation by administering each question as a test. Finally, it generates a summary at the end of the conversation. Evaluation results using LLMs and domain experts have shown a clear preference for EHRTutor over the baseline. Moreover, EHRTutor also offers a framework for generating synthetic patient education dialogues that can be used for future in-house system training.
AttT2M: Text-Driven Human Motion Generation with Multi-Perspective Attention Mechanism
Sep 02, 2023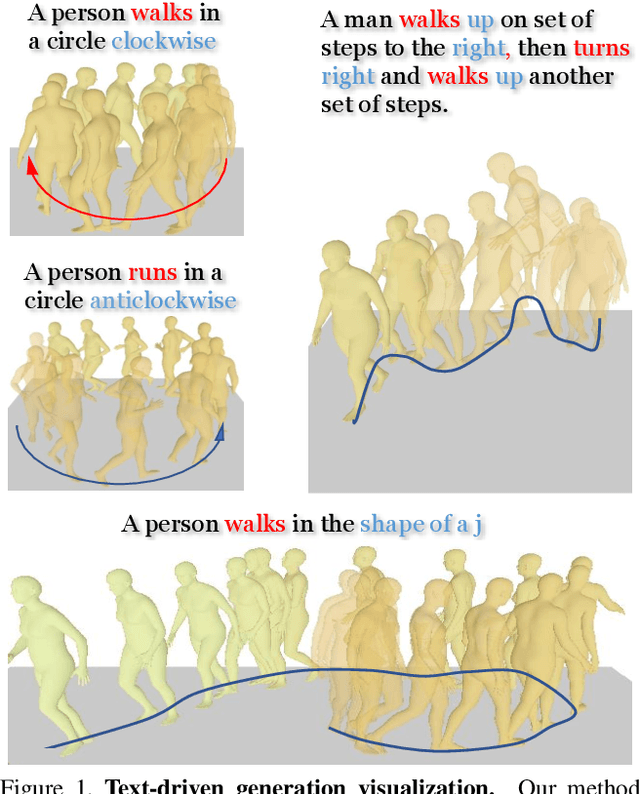
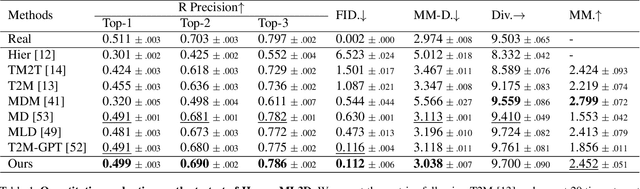

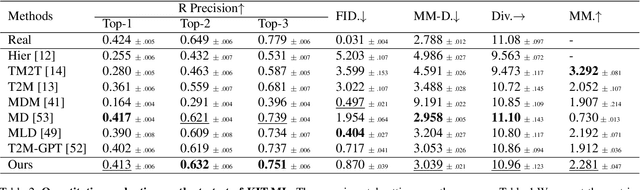
Generating 3D human motion based on textual descriptions has been a research focus in recent years. It requires the generated motion to be diverse, natural, and conform to the textual description. Due to the complex spatio-temporal nature of human motion and the difficulty in learning the cross-modal relationship between text and motion, text-driven motion generation is still a challenging problem. To address these issues, we propose \textbf{AttT2M}, a two-stage method with multi-perspective attention mechanism: \textbf{body-part attention} and \textbf{global-local motion-text attention}. The former focuses on the motion embedding perspective, which means introducing a body-part spatio-temporal encoder into VQ-VAE to learn a more expressive discrete latent space. The latter is from the cross-modal perspective, which is used to learn the sentence-level and word-level motion-text cross-modal relationship. The text-driven motion is finally generated with a generative transformer. Extensive experiments conducted on HumanML3D and KIT-ML demonstrate that our method outperforms the current state-of-the-art works in terms of qualitative and quantitative evaluation, and achieve fine-grained synthesis and action2motion. Our code is in https://github.com/ZcyMonkey/AttT2M
GICI-LIB: A GNSS/INS/Camera Integrated Navigation Library
Jun 23, 2023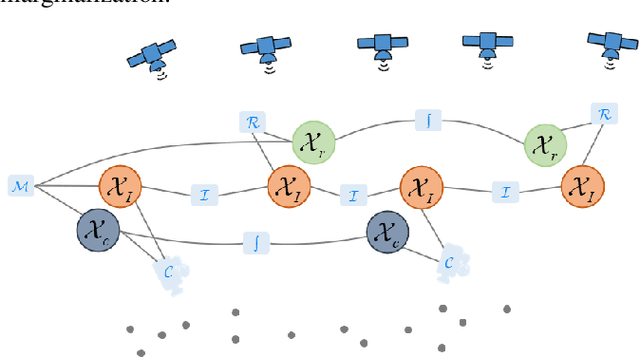

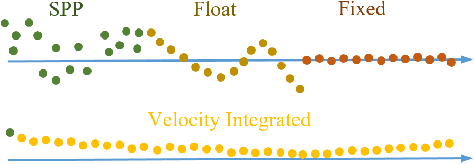

Accurate navigation is essential for autonomous robots and vehicles. In recent years, the integration of the Global Navigation Satellite System (GNSS), Inertial Navigation System (INS), and camera has garnered considerable attention due to its robustness and high accuracy in diverse environments. In such systems, fully utilizing the role of GNSS is cumbersome because of the diverse choices of formulations, error models, satellite constellations, signal frequencies, and service types, which lead to different precision, robustness, and usage dependencies. To clarify the capacity of GNSS algorithms and accelerate the development efficiency of employing GNSS in multi-sensor fusion algorithms, we open source the GNSS/INS/Camera Integration Library (GICI-LIB), together with detailed documentation and a comprehensive land vehicle dataset. A factor graph optimization-based multi-sensor fusion framework is established, which combines almost all GNSS measurement error sources by fully considering temporal and spatial correlations between measurements. The graph structure is designed for flexibility, making it easy to form any kind of integration algorithm. For illustration, four Real-Time Kinematic (RTK)-based algorithms from GICI-LIB are evaluated using our dataset. Results confirm the potential of the GICI system to provide continuous precise navigation solutions in a wide spectrum of urban environments.
Pose-aware Attention Network for Flexible Motion Retargeting by Body Part
Jun 13, 2023Motion retargeting is a fundamental problem in computer graphics and computer vision. Existing approaches usually have many strict requirements, such as the source-target skeletons needing to have the same number of joints or share the same topology. To tackle this problem, we note that skeletons with different structure may have some common body parts despite the differences in joint numbers. Following this observation, we propose a novel, flexible motion retargeting framework. The key idea of our method is to regard the body part as the basic retargeting unit rather than directly retargeting the whole body motion. To enhance the spatial modeling capability of the motion encoder, we introduce a pose-aware attention network (PAN) in the motion encoding phase. The PAN is pose-aware since it can dynamically predict the joint weights within each body part based on the input pose, and then construct a shared latent space for each body part by feature pooling. Extensive experiments show that our approach can generate better motion retargeting results both qualitatively and quantitatively than state-of-the-art methods. Moreover, we also show that our framework can generate reasonable results even for a more challenging retargeting scenario, like retargeting between bipedal and quadrupedal skeletons because of the body part retargeting strategy and PAN. Our code is publicly available.
Robots in the Garden: Artificial Intelligence and Adaptive Landscapes
May 22, 2023
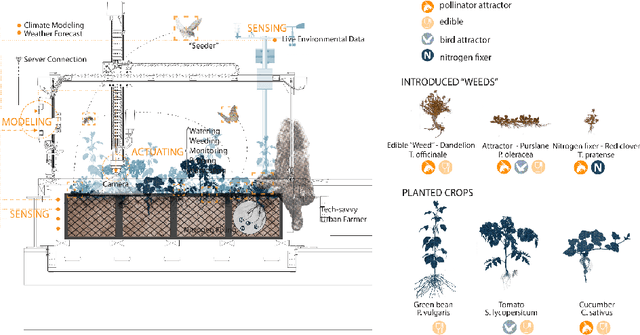
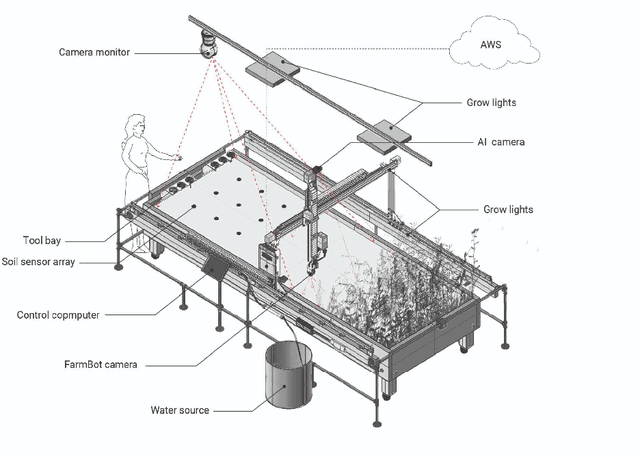
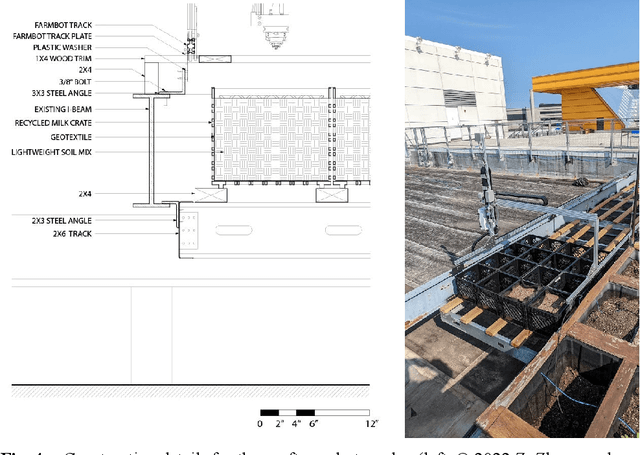
This paper introduces ELUA, the Ecological Laboratory for Urban Agriculture, a collaboration among landscape architects, architects and computer scientists who specialize in artificial intelligence, robotics and computer vision. ELUA has two gantry robots, one indoors and the other outside on the rooftop of a 6-story campus building. Each robot can seed, water, weed, and prune in its garden. To support responsive landscape research, ELUA also includes sensor arrays, an AI-powered camera, and an extensive network infrastructure. This project demonstrates a way to integrate artificial intelligence into an evolving urban ecosystem, and encourages landscape architects to develop an adaptive design framework where design becomes a long-term engagement with the environment.
* 4 figures, 9 pages
Cybernetic Environment: A Historical Reflection on System, Design, and Machine Intelligence
May 03, 2023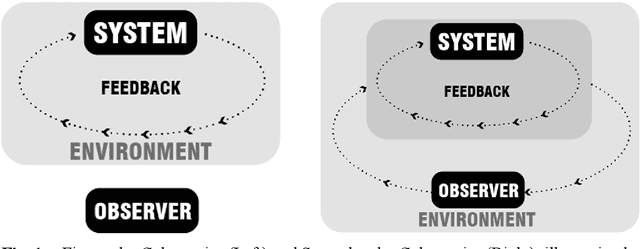
Taking on a historical lens, this paper traces the development of cybernetics and systems thinking back to the 1950s, when a group of interdisciplinary scholars converged to create a new theoretical model based on machines and systems for understanding matters of meaning, information, consciousness, and life. By presenting a genealogy of research in the landscape architecture discipline, the paper argues that landscape architects have been an important part of the development of cybernetics by materializing systems based on cybernetic principles in the environment through ecologically based landscape design. The landscape discipline has developed a design framework that provides transformative insights into understanding machine intelligence. The paper calls for a new paradigm of environmental engagement to understand matters of design and machine intelligence.
* 8 pages, theory/history
Cultivated Wildness: Technodiversity and Wildness in Machines
May 03, 2023This paper investigates the idea of cultivated wildness at the intersection of landscape design and artificial intelligence. The paper posits that contemporary landscape practices should overcome the potentially single understanding on wilderness, and instead explore landscape strategies to cultivate new forms of wild places via ideas and concerns in contemporary Environmental Humanities, Science and Technology Studies, Ecological Sciences, and Landscape Architecture. Drawing cases in environmental engineering, computer science, and landscape architecture research, this paper explores a framework to construct wild places with intelligent machines. In this framework, machines are not understood as a layer of "digital infrastructure" that is used to extend localized human intelligence and agency. Rather machines are conceptualized as active agents who can participate in the intelligence of co-production. Recent developments in cybernetic technologies such as sensing networks, artificial intelligence, and cyberphysical systems can also contribute to establishing the framework. At the heart of this framework is "technodiversity," in parallel with biodiversity, since a singular vision on technological development driven by optimization and efficiency reinforces a monocultural approach that eliminates other possible relationships to construct with the environment. Thus, cultivated wildness is also about recognizing "wildness" in machines.
* English/Chinese, 14 pages, 6 figures
The Future of Artificial Intelligence (AI) and Machine Learning (ML) in Landscape Design: A Case Study in Coastal Virginia, USA
May 03, 2023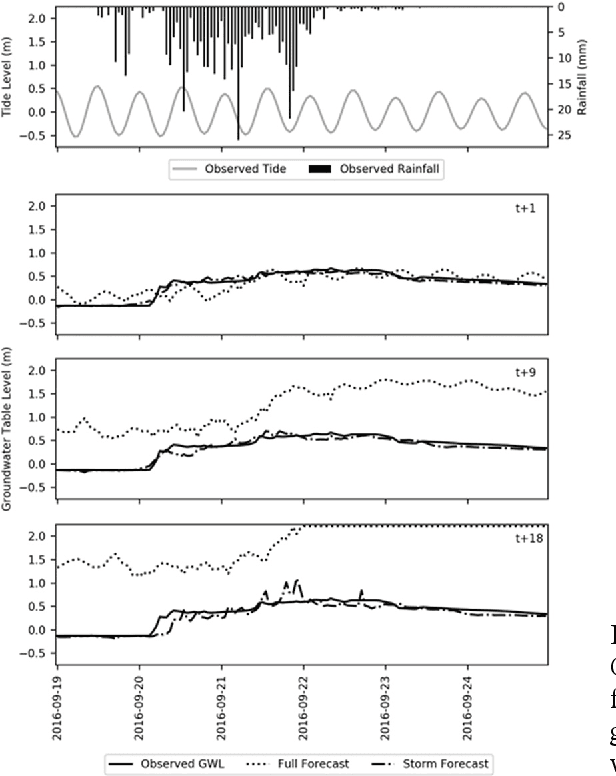
There have been theory-based endeavours that directly engage with AI and ML in the landscape discipline. By presenting a case that uses machine learning techniques to predict variables in a coastal environment, this paper provides empirical evidence of the forthcoming cybernetic environment, in which designers are conceptualized not as authors but as choreographers, catalyst agents, and conductors among many other intelligent agents. Drawing ideas from posthumanism, this paper argues that, to truly understand the cybernetic environment, we have to take on posthumanist ethics and overcome human exceptionalism.
* 8 pages, case study, theory