 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZizhao Wang
Dyna-LfLH: Learning Agile Navigation in Dynamic Environments from Learned Hallucination
Mar 25, 2024



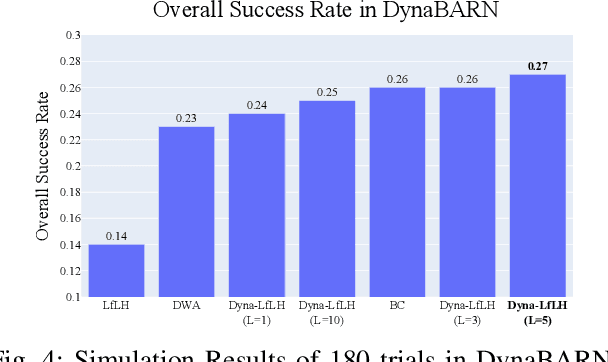
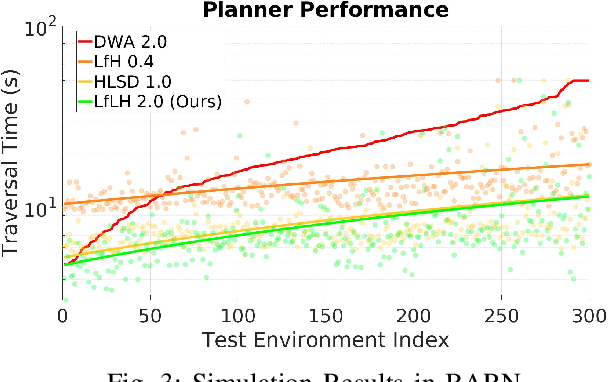
This paper presents a self-supervised learning method to safely learn a motion planner for ground robots to navigate environments with dense and dynamic obstacles. When facing highly-cluttered, fast-moving, hard-to-predict obstacles, classical motion planners may not be able to keep up with limited onboard computation. For learning-based planners, high-quality demonstrations are difficult to acquire for imitation learning while reinforcement learning becomes inefficient due to the high probability of collision during exploration. To safely and efficiently provide training data, the Learning from Hallucination (LfH) approaches synthesize difficult navigation environments based on past successful navigation experiences in relatively easy or completely open ones, but unfortunately cannot address dynamic obstacles. In our new Dynamic Learning from Learned Hallucination (Dyna-LfLH), we design and learn a novel latent distribution and sample dynamic obstacles from it, so the generated training data can be used to learn a motion planner to navigate in dynamic environments. Dyna-LfLH is evaluated on a ground robot in both simulated and physical environments and achieves up to 25% better success rate compared to baselines.
Building Minimal and Reusable Causal State Abstractions for Reinforcement Learning
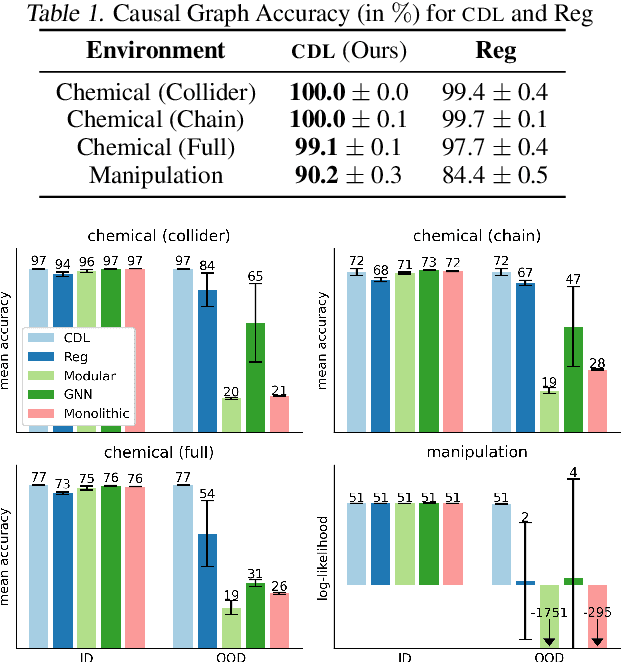
Jan 23, 2024Two desiderata of reinforcement learning (RL) algorithms are the ability to learn from relatively little experience and the ability to learn policies that generalize to a range of problem specifications. In factored state spaces, one approach towards achieving both goals is to learn state abstractions, which only keep the necessary variables for learning the tasks at hand. This paper introduces Causal Bisimulation Modeling (CBM), a method that learns the causal relationships in the dynamics and reward functions for each task to derive a minimal, task-specific abstraction. CBM leverages and improves implicit modeling to train a high-fidelity causal dynamics model that can be reused for all tasks in the same environment. Empirical validation on manipulation environments and Deepmind Control Suite reveals that CBM's learned implicit dynamics models identify the underlying causal relationships and state abstractions more accurately than explicit ones. Furthermore, the derived state abstractions allow a task learner to achieve near-oracle levels of sample efficiency and outperform baselines on all tasks.
ELDEN: Exploration via Local Dependencies
Oct 12, 2023

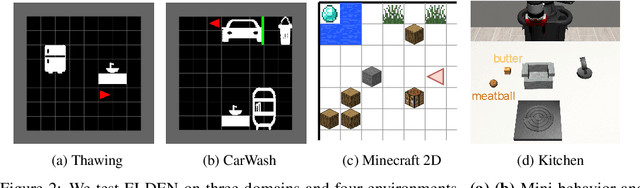

Tasks with large state space and sparse rewards present a longstanding challenge to reinforcement learning. In these tasks, an agent needs to explore the state space efficiently until it finds a reward. To deal with this problem, the community has proposed to augment the reward function with intrinsic reward, a bonus signal that encourages the agent to visit interesting states. In this work, we propose a new way of defining interesting states for environments with factored state spaces and complex chained dependencies, where an agent's actions may change the value of one entity that, in order, may affect the value of another entity. Our insight is that, in these environments, interesting states for exploration are states where the agent is uncertain whether (as opposed to how) entities such as the agent or objects have some influence on each other. We present ELDEN, Exploration via Local DepENdencies, a novel intrinsic reward that encourages the discovery of new interactions between entities. ELDEN utilizes a novel scheme -- the partial derivative of the learned dynamics to model the local dependencies between entities accurately and computationally efficiently. The uncertainty of the predicted dependencies is then used as an intrinsic reward to encourage exploration toward new interactions. We evaluate the performance of ELDEN on four different domains with complex dependencies, ranging from 2D grid worlds to 3D robotic tasks. In all domains, ELDEN correctly identifies local dependencies and learns successful policies, significantly outperforming previous state-of-the-art exploration methods.
Learning to Correct Mistakes: Backjumping in Long-Horizon Task and Motion Planning
Nov 15, 2022

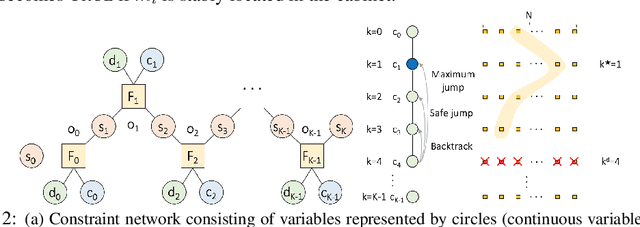

As robots become increasingly capable of manipulation and long-term autonomy, long-horizon task and motion planning problems are becoming increasingly important. A key challenge in such problems is that early actions in the plan may make future actions infeasible. When reaching a dead-end in the search, most existing planners use backtracking, which exhaustively reevaluates motion-level actions, often resulting in inefficient planning, especially when the search depth is large. In this paper, we propose to learn backjumping heuristics which identify the culprit action directly using supervised learning models to guide the task-level search. Based on evaluations on two different tasks, we find that our method significantly improves planning efficiency compared to backtracking and also generalizes to problems with novel numbers of objects.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The BARN Challenge at ICRA 2022
Aug 22, 2022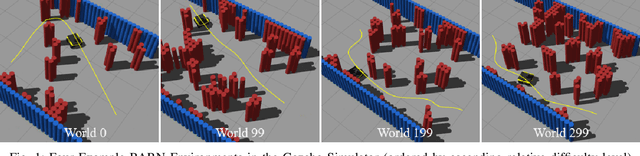


The BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2022 IEEE International Conference on Robotics and Automation (ICRA 2022) in Philadelphia, PA. The aim of the challenge was to evaluate state-of-the-art autonomous ground navigation systems for moving robots through highly constrained environments in a safe and efficient manner. Specifically, the task was to navigate a standardized, differential-drive ground robot from a predefined start location to a goal location as quickly as possible without colliding with any obstacles, both in simulation and in the real world. Five teams from all over the world participated in the qualifying simulation competition, three of which were invited to compete with each other at a set of physical obstacle courses at the conference center in Philadelphia. The competition results suggest that autonomous ground navigation in highly constrained spaces, despite seeming ostensibly simple even for experienced roboticists, is actually far from being a solved problem. In this article, we discuss the challenge, the approaches used by the top three winning teams, and lessons learned to direct future research.
Causal Dynamics Learning for Task-Independent State Abstraction
Jun 27, 2022
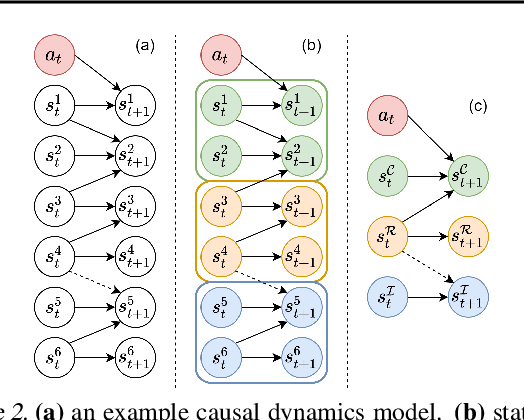

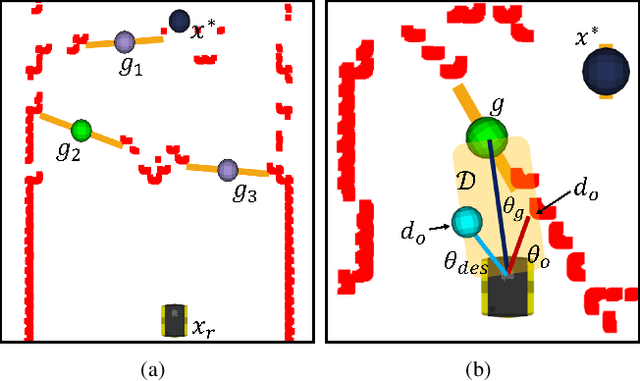
Learning dynamics models accurately is an important goal for Model-Based Reinforcement Learning (MBRL), but most MBRL methods learn a dense dynamics model which is vulnerable to spurious correlations and therefore generalizes poorly to unseen states. In this paper, we introduce Causal Dynamics Learning for Task-Independent State Abstraction (CDL), which first learns a theoretically proved causal dynamics model that removes unnecessary dependencies between state variables and the action, thus generalizing well to unseen states. A state abstraction can then be derived from the learned dynamics, which not only improves sample efficiency but also applies to a wider range of tasks than existing state abstraction methods. Evaluated on two simulated environments and downstream tasks, both the dynamics model and policies learned by the proposed method generalize well to unseen states and the derived state abstraction improves sample efficiency compared to learning without it.
APPLE: Adaptive Planner Parameter Learning from Evaluative Feedback
Aug 22, 2021


Classical autonomous navigation systems can control robots in a collision-free manner, oftentimes with verifiable safety and explainability. When facing new environments, however, fine-tuning of the system parameters by an expert is typically required before the system can navigate as expected. To alleviate this requirement, the recently-proposed Adaptive Planner Parameter Learning paradigm allows robots to \emph{learn} how to dynamically adjust planner parameters using a teleoperated demonstration or corrective interventions from non-expert users. However, these interaction modalities require users to take full control of the moving robot, which requires the users to be familiar with robot teleoperation. As an alternative, we introduce \textsc{apple}, Adaptive Planner Parameter Learning from \emph{Evaluative Feedback} (real-time, scalar-valued assessments of behavior), which represents a less-demanding modality of interaction. Simulated and physical experiments show \textsc{apple} can achieve better performance compared to the planner with static default parameters and even yield improvement over learned parameters from richer interaction modalities.
From Agile Ground to Aerial Navigation: Learning from Learned Hallucination
Aug 22, 2021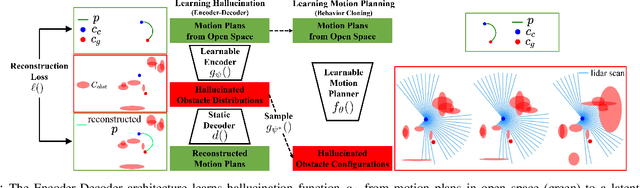


This paper presents a self-supervised Learning from Learned Hallucination (LfLH) method to learn fast and reactive motion planners for ground and aerial robots to navigate through highly constrained environments. The recent Learning from Hallucination (LfH) paradigm for autonomous navigation executes motion plans by random exploration in completely safe obstacle-free spaces, uses hand-crafted hallucination techniques to add imaginary obstacles to the robot's perception, and then learns motion planners to navigate in realistic, highly-constrained, dangerous spaces. However, current hand-crafted hallucination techniques need to be tailored for specific robot types (e.g., a differential drive ground vehicle), and use approximations heavily dependent on certain assumptions (e.g., a short planning horizon). In this work, instead of manually designing hallucination functions, LfLH learns to hallucinate obstacle configurations, where the motion plans from random exploration in open space are optimal, in a self-supervised manner. LfLH is robust to different robot types and does not make assumptions about the planning horizon. Evaluated in both simulated and physical environments with a ground and an aerial robot, LfLH outperforms or performs comparably to previous hallucination approaches, along with sampling- and optimization-based classical methods.
APPL: Adaptive Planner Parameter Learning
May 17, 2021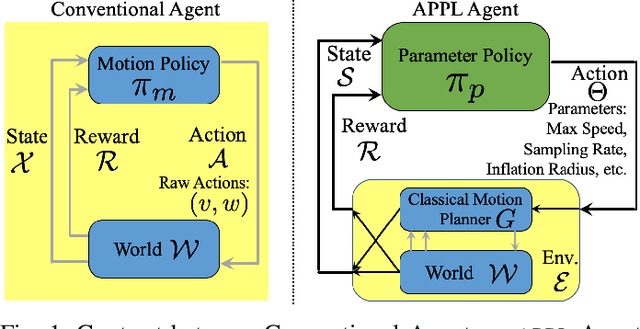

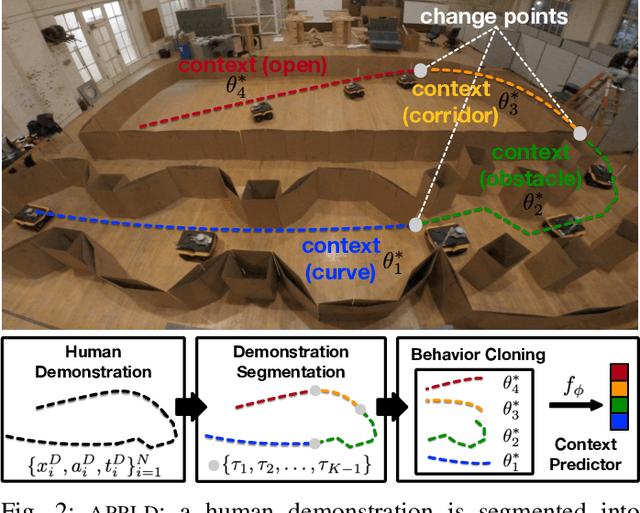
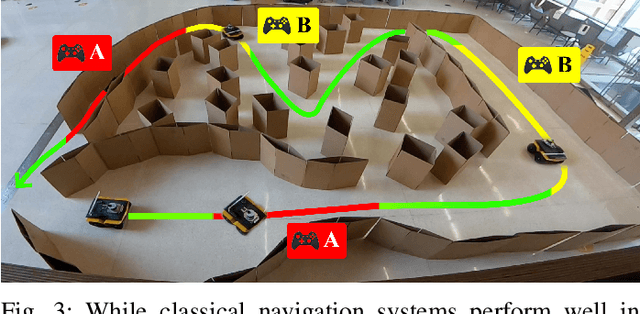
While current autonomous navigation systems allow robots to successfully drive themselves from one point to another in specific environments, they typically require extensive manual parameter re-tuning by human robotics experts in order to function in new environments. Furthermore, even for just one complex environment, a single set of fine-tuned parameters may not work well in different regions of that environment. These problems prohibit reliable mobile robot deployment by non-expert users. As a remedy, we propose Adaptive Planner Parameter Learning (APPL), a machine learning framework that can leverage non-expert human interaction via several modalities -- including teleoperated demonstrations, corrective interventions, and evaluative feedback -- and also unsupervised reinforcement learning to learn a parameter policy that can dynamically adjust the parameters of classical navigation systems in response to changes in the environment. APPL inherits safety and explainability from classical navigation systems while also enjoying the benefits of machine learning, i.e., the ability to adapt and improve from experience. We present a suite of individual APPL methods and also a unifying cycle-of-learning scheme that combines all the proposed methods in a framework that can improve navigation performance through continual, iterative human interaction and simulation training.
CLAMGen: Closed-Loop Arm Motion Generation via Multi-view Vision-Based RL
Mar 24, 2021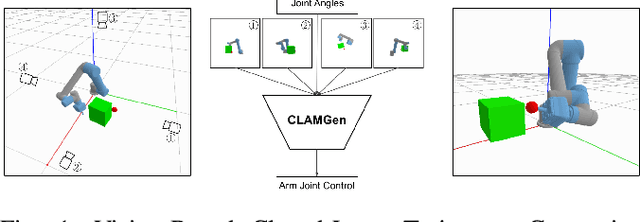
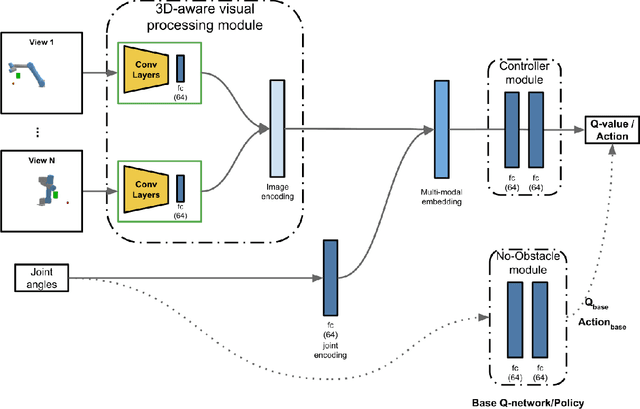
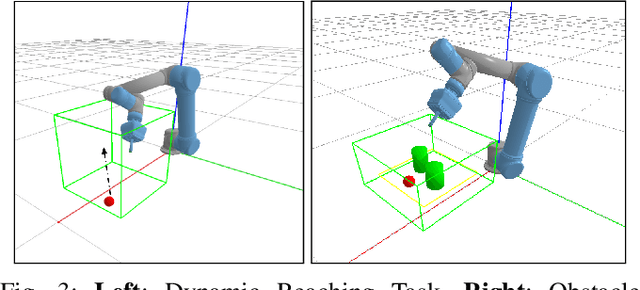

We propose a vision-based reinforcement learning (RL) approach for closed-loop trajectory generation in an arm reaching problem. Arm trajectory generation is a fundamental robotics problem which entails finding collision-free paths to move the robot's body (e.g. arm) in order to satisfy a goal (e.g. place end-effector at a point). While classical methods typically require the model of the environment to solve a planning, search or optimization problem, learning-based approaches hold the promise of directly mapping from observations to robot actions. However, learning a collision-avoidance policy using RL remains a challenge for various reasons, including, but not limited to, partial observability, poor exploration, low sample efficiency, and learning instabilities. To address these challenges, we present a residual-RL method that leverages a greedy goal-reaching RL policy as the base to improve exploration, and the base policy is augmented with residual state-action values and residual actions learned from images to avoid obstacles. Further more, we introduce novel learning objectives and techniques to improve 3D understanding from multiple image views and sample efficiency of our algorithm. Compared to RL baselines, our method achieves superior performance in terms of success rate.