 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoonchang Sung
Asynchronous Task Plan Refinement for Multi-Robot Task and Motion Planning
Sep 16, 2023
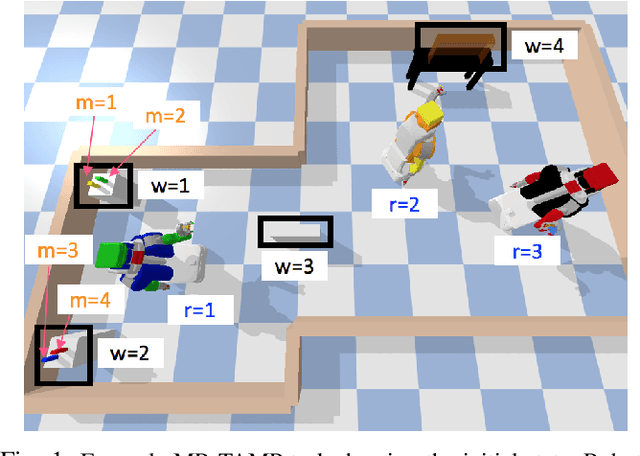
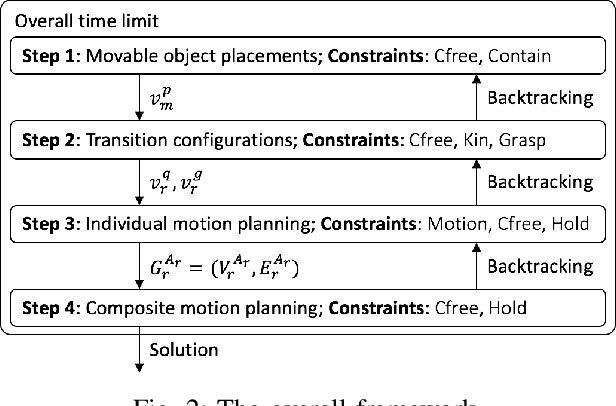
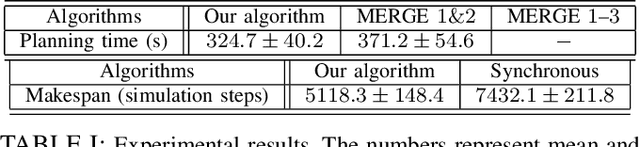
This paper explores general multi-robot task and motion planning, where multiple robots in close proximity manipulate objects while satisfying constraints and a given goal. In particular, we formulate the plan refinement problem--which, given a task plan, finds valid assignments of variables corresponding to solution trajectories--as a hybrid constraint satisfaction problem. The proposed algorithm follows several design principles that yield the following features: (1) efficient solution finding due to sequential heuristics and implicit time and roadmap representations, and (2) maximized feasible solution space obtained by introducing minimally necessary coordination-induced constraints and not relying on prevalent simplifications that exist in the literature. The evaluation results demonstrate the planning efficiency of the proposed algorithm, outperforming the synchronous approach in terms of makespan.
Decision-Theoretic Approaches for Robotic Environmental Monitoring -- A Survey
Aug 04, 2023Robotics has dramatically increased our ability to gather data about our environments. This is an opportune time for the robotics and algorithms community to come together to contribute novel solutions to pressing environmental monitoring problems. In order to do so, it is useful to consider a taxonomy of problems and methods in this realm. We present the first comprehensive summary of decision theoretic approaches that are enabling efficient sampling of various kinds of environmental processes. Representations for different kinds of environments are explored, followed by a discussion of tasks of interest such as learning, localization, or monitoring. Finally, various algorithms to carry out these tasks are presented, along with a few illustrative prior results from the community.
Motion Planning (In)feasibility Detection using a Prior Roadmap via Path and Cut Search
May 18, 2023



Motion planning seeks a collision-free path in a configuration space (C-space), representing all possible robot configurations in the environment. As it is challenging to construct a C-space explicitly for a high-dimensional robot, we generally build a graph structure called a roadmap, a discrete approximation of a complex continuous C-space, to reason about connectivity. Checking collision-free connectivity in the roadmap requires expensive edge-evaluation computations, and thus, reducing the number of evaluations has become a significant research objective. However, in practice, we often face infeasible problems: those in which there is no collision-free path in the roadmap between the start and the goal locations. Existing studies often overlook the possibility of infeasibility, becoming highly inefficient by performing many edge evaluations. In this work, we address this oversight in scenarios where a prior roadmap is available; that is, the edges of the roadmap contain the probability of being a collision-free edge learned from past experience. To this end, we propose an algorithm called iterative path and cut finding (IPC) that iteratively searches for a path and a cut in a prior roadmap to detect infeasibility while reducing expensive edge evaluations as much as possible. We further improve the efficiency of IPC by introducing a second algorithm, iterative decomposition and path and cut finding (IDPC), that leverages the fact that cut-finding algorithms partition the roadmap into smaller subgraphs. We analyze the theoretical properties of IPC and IDPC, such as completeness and computational complexity, and evaluate their performance in terms of completion time and the number of edge evaluations in large-scale simulations.
Learning to Correct Mistakes: Backjumping in Long-Horizon Task and Motion Planning
Nov 15, 2022

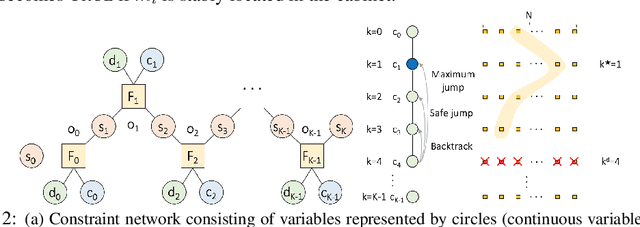

As robots become increasingly capable of manipulation and long-term autonomy, long-horizon task and motion planning problems are becoming increasingly important. A key challenge in such problems is that early actions in the plan may make future actions infeasible. When reaching a dead-end in the search, most existing planners use backtracking, which exhaustively reevaluates motion-level actions, often resulting in inefficient planning, especially when the search depth is large. In this paper, we propose to learn backjumping heuristics which identify the culprit action directly using supervised learning models to guide the task-level search. Based on evaluations on two different tasks, we find that our method significantly improves planning efficiency compared to backtracking and also generalizes to problems with novel numbers of objects.
Towards Optimal Correlational Object Search
Oct 19, 2021
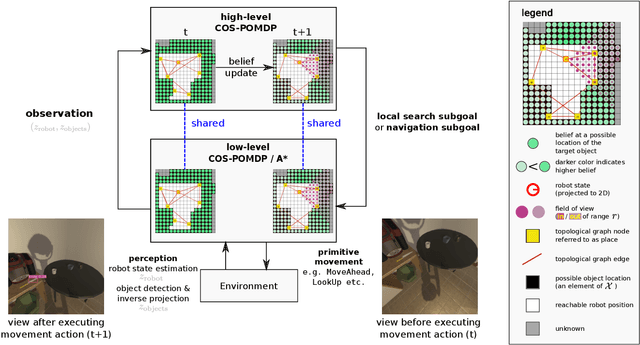


In realistic applications of object search, robots will need to locate target objects in complex environments while coping with unreliable sensors, especially for small or hard-to-detect objects. In such settings, correlational information can be valuable for planning efficiently: when looking for a fork, the robot could start by locating the easier-to-detect refrigerator, since forks would probably be found nearby. Previous approaches to object search with correlational information typically resort to ad-hoc or greedy search strategies. In this paper, we propose the Correlational Object Search POMDP (COS-POMDP), which can be solved to produce search strategies that use correlational information. COS-POMDPs contain a correlation-based observation model that allows us to avoid the exponential blow-up of maintaining a joint belief about all objects, while preserving the optimal solution to this naive, exponential POMDP formulation. We propose a hierarchical planning algorithm to scale up COS-POMDP for practical domains. We conduct experiments using AI2-THOR, a realistic simulator of household environments, as well as YOLOv5, a widely-used object detector. Our results show that, particularly for hard-to-detect objects, such as scrub brush and remote control, our method offers the most robust performance compared to baselines that ignore correlations as well as a greedy, next-best view approach.
Reactive Task and Motion Planning under Temporal Logic Specifications
Mar 26, 2021



We present a task-and-motion planning (TAMP) algorithm robust against a human operator's cooperative or adversarial interventions. Interventions often invalidate the current plan and require replanning on the fly. Replanning can be computationally expensive and often interrupts seamless task execution. We introduce a dynamically reconfigurable planning methodology with behavior tree-based control strategies toward reactive TAMP, which takes the advantage of previous plans and incremental graph search during temporal logic-based reactive synthesis. Our algorithm also shows efficient recovery functionalities that minimize the number of replanning steps. Finally, our algorithm produces a robust, efficient, and complete TAMP solution. Our experimental results show the algorithm results in superior manipulation performance in both simulated and real-world tasks.
Learning When to Quit: Meta-Reasoning for Motion Planning
Mar 07, 2021



Anytime motion planners are widely used in robotics. However, the relationship between their solution quality and computation time is not well understood, and thus, determining when to quit planning and start execution is unclear. In this paper, we address the problem of deciding when to stop deliberation under bounded computational capacity, so called meta-reasoning, for anytime motion planning. We propose data-driven learning methods, model-based and model-free meta-reasoning, that are applicable to different environment distributions and agnostic to the choice of anytime motion planners. As a part of the framework, we design a convolutional neural network-based optimal solution predictor that predicts the optimal path length from a given 2D workspace image. We empirically evaluate the performance of the proposed methods in simulation in comparison with baselines.
Multi-Resolution POMDP Planning for Multi-Object Search in 3D
May 07, 2020
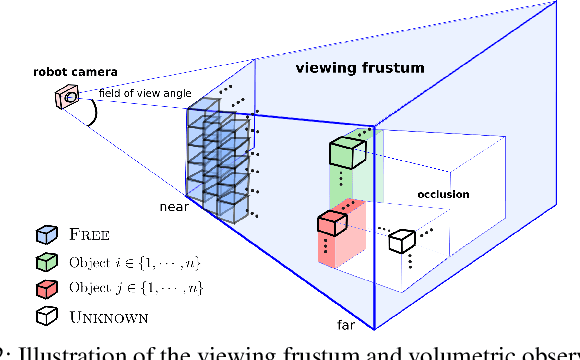
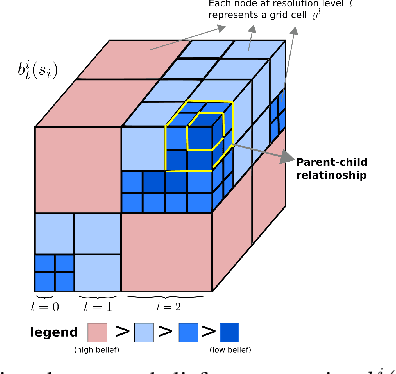
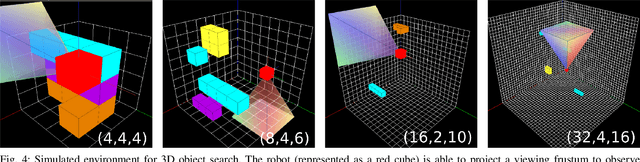
Robots operating in household environments must find objects on shelves, under tables, and in cupboards. Previous work often formulate the object search problem as a POMDP (Partially Observable Markov Decision Process), yet constrain the search space in 2D. We propose a new approach that enables the robot to efficiently search for objects in 3D, taking occlusions into account. We model the problem as an object-oriented POMDP, where the robot receives a volumetric observation from a viewing frustum and must produce a policy to efficiently search for objects. To address the challenge of large state and observation spaces, we first propose a per-voxel observation model which drastically reduces the observation size necessary for planning. Then, we present a novel octree-based belief representation which captures beliefs at different resolutions and supports efficient exact belief update. Finally, we design an online multi-resolution planning algorithm that leverages the resolution layers in the octree structure as levels of abstractions to the original POMDP problem. Our evaluation in a simulated 3D domain shows that, as the problem scales, our approach significantly outperforms baselines without resolution hierarchy by 25%-35% in cumulative reward. We demonstrate the practicality of our approach on a torso-actuated mobile robot searching for objects in areas of a cluttered lab environment where objects appear on surfaces at different heights.
Environmental Hotspot Identification in Limited Time with a UAV Equipped with a Downward-Facing Camera
Sep 18, 2019



We are motivated by environmental monitoring tasks where finding the global maxima (i.e., hotspot) of a spatially varying field is crucial. We investigate the problem of identifying the hotspot for fields that can be sensed using an Unmanned Aerial Vehicle (UAV) equipped with a downward-facing camera. The UAV has a limited time budget which it must use for learning the unknown field and identifying the hotspot. Our first contribution is to show how this problem can be formulated as a novel variant of the Gaussian Process (GP) multi-armed bandit problem. The novelty is two-fold: (i) unlike standard multi-armed bandit settings, the arms ; and (ii) unlike standard GP regression, the measurements in our problem are image (i.e., vector measurements) whose quality depends on the altitude at which the UAV flies. We present a strategy for finding the sequence of UAV sensing locations and empirically compare it with a number of baselines. We also present experimental results using images gathered onboard a UAV.
Tree Search Techniques for Minimizing Detectability and Maximizing Visibility
Feb 22, 2019



We introduce and study the problem of planning a trajectory for an agent to carry out a scouting mission while avoiding being detected by an adversarial guard. This introduces an adversarial version of classical visibility-based planning problems such as the Watchman Route Problem. The agent receives a positive reward for increasing its visibility and a negative penalty when it is detected by the guard. The objective is to find a finite-horizon path for the agent that balances the trade-off maximizing visibility and minimizing detectability. We model this problem as a sequential two-player zero-sum discrete game. A minimax tree search can give the optimal policy for the agent but requires an exponential-time computation and space. We propose several pruning techniques to reduce the computational cost while still preserving optimality guarantees. Simulation results show that the proposed strategy prunes approximately three orders of magnitude nodes as compared to the brute-force strategy.