 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Chen": models, code, and papers
Randomly Pivoted Partial Cholesky: Random How?
Apr 17, 2024
We consider the problem of finding good low rank approximations of symmetric, positive-definite $A \in \mathbb{R}^{n \times n}$. Chen-Epperly-Tropp-Webber showed, among many other things, that the randomly pivoted partial Cholesky algorithm that chooses the $i-$th row with probability proportional to the diagonal entry $A_{ii}$ leads to a universal contraction of the trace norm (the Schatten 1-norm) in expectation for each step. We show that if one chooses the $i-$th row with likelihood proportional to $A_{ii}^2$ one obtains the same result in the Frobenius norm (the Schatten 2-norm). Implications for the greedy pivoting rule and pivot selection strategies are discussed.
Cryptographic Hardness of Score Estimation
Apr 04, 2024We show that $L^2$-accurate score estimation, in the absence of strong assumptions on the data distribution, is computationally hard even when sample complexity is polynomial in the relevant problem parameters. Our reduction builds on the result of Chen et al. (ICLR 2023), who showed that the problem of generating samples from an unknown data distribution reduces to $L^2$-accurate score estimation. Our hard-to-estimate distributions are the "Gaussian pancakes" distributions, originally due to Diakonikolas et al. (FOCS 2017), which have been shown to be computationally indistinguishable from the standard Gaussian under widely believed hardness assumptions from lattice-based cryptography (Bruna et al., STOC 2021; Gupte et al., FOCS 2022).
IITK at SemEval-2024 Task 4: Hierarchical Embeddings for Detection of Persuasion Techniques in Memes
Apr 06, 2024Memes are one of the most popular types of content used in an online disinformation campaign. They are primarily effective on social media platforms since they can easily reach many users. Memes in a disinformation campaign achieve their goal of influencing the users through several rhetorical and psychological techniques, such as causal oversimplification, name-calling, and smear. The SemEval 2024 Task 4 \textit{Multilingual Detection of Persuasion Technique in Memes} on identifying such techniques in the memes is divided across three sub-tasks: ($\mathbf{1}$) Hierarchical multi-label classification using only textual content of the meme, ($\mathbf{2}$) Hierarchical multi-label classification using both, textual and visual content of the meme and ($\mathbf{3}$) Binary classification of whether the meme contains a persuasion technique or not using it's textual and visual content. This paper proposes an ensemble of Class Definition Prediction (CDP) and hyperbolic embeddings-based approaches for this task. We enhance meme classification accuracy and comprehensiveness by integrating HypEmo's hierarchical label embeddings (Chen et al., 2023) and a multi-task learning framework for emotion prediction. We achieve a hierarchical F1-score of 0.60, 0.67, and 0.48 on the respective sub-tasks.
Rademacher Complexity of Neural ODEs via Chen-Fliess Series
Jan 31, 2024We show how continuous-depth neural ODE models can be framed as single-layer, infinite-width nets using the Chen--Fliess series expansion for nonlinear ODEs. In this net, the output "weights" are taken from the signature of the control input -- a tool used to represent infinite-dimensional paths as a sequence of tensors -- which comprises iterated integrals of the control input over a simplex. The "features" are taken to be iterated Lie derivatives of the output function with respect to the vector fields in the controlled ODE model. The main result of this work applies this framework to derive compact expressions for the Rademacher complexity of ODE models that map an initial condition to a scalar output at some terminal time. The result leverages the straightforward analysis afforded by single-layer architectures. We conclude with some examples instantiating the bound for some specific systems and discuss potential follow-up work.
Using Interpretation Methods for Model Enhancement
Apr 02, 2024In the age of neural natural language processing, there are plenty of works trying to derive interpretations of neural models. Intuitively, when gold rationales exist during training, one can additionally train the model to match its interpretation with the rationales. However, this intuitive idea has not been fully explored. In this paper, we propose a framework of utilizing interpretation methods and gold rationales to enhance models. Our framework is very general in the sense that it can incorporate various interpretation methods. Previously proposed gradient-based methods can be shown as an instance of our framework. We also propose two novel instances utilizing two other types of interpretation methods, erasure/replace-based and extractor-based methods, for model enhancement. We conduct comprehensive experiments on a variety of tasks. Experimental results show that our framework is effective especially in low-resource settings in enhancing models with various interpretation methods, and our two newly-proposed methods outperform gradient-based methods in most settings. Code is available at https://github.com/Chord-Chen-30/UIMER.
* EMNLP 2023
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
Apr 01, 2024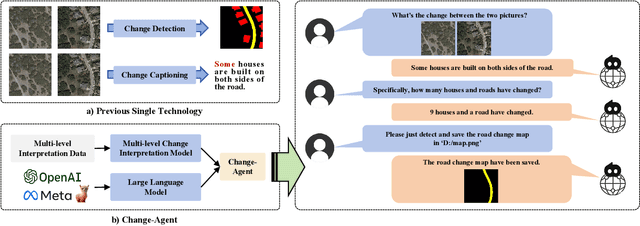
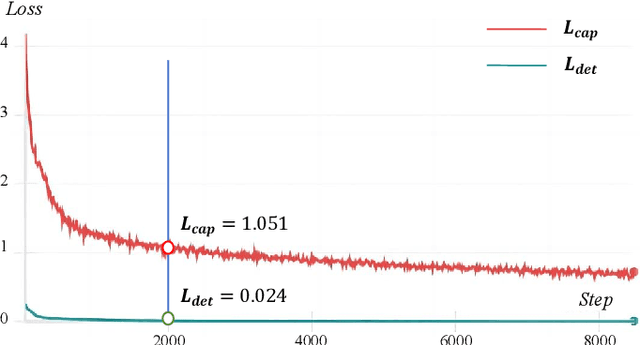
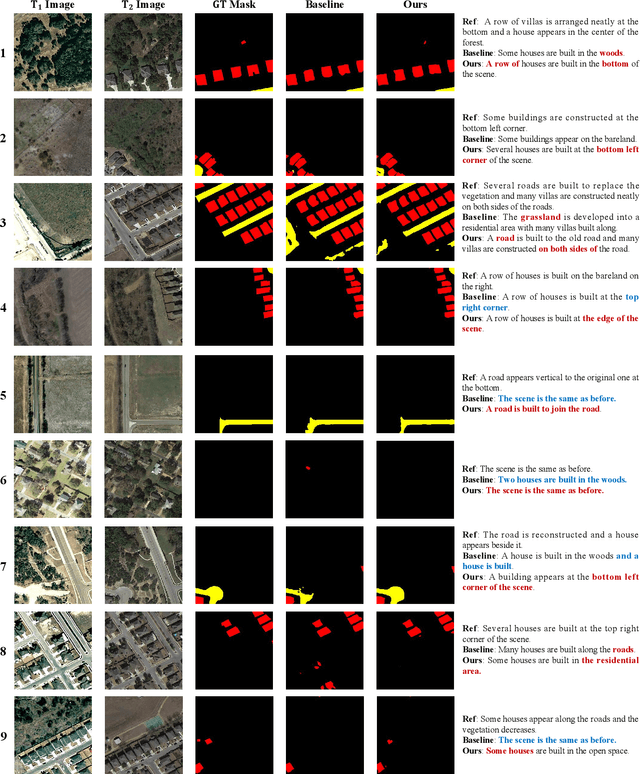
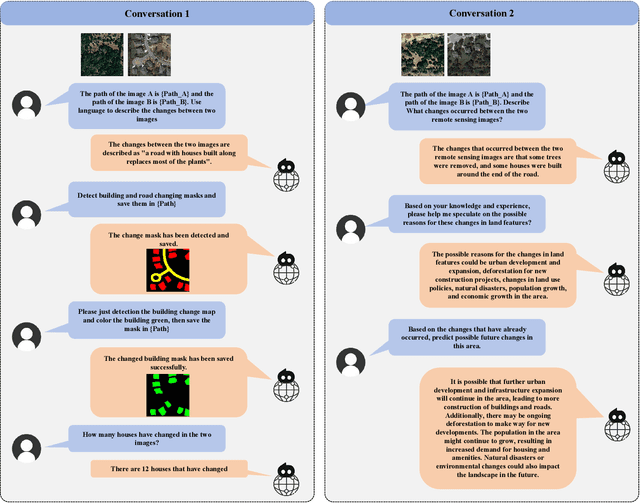
Monitoring changes in the Earth's surface is crucial for understanding natural processes and human impacts, necessitating precise and comprehensive interpretation methodologies. Remote sensing satellite imagery offers a unique perspective for monitoring these changes, leading to the emergence of remote sensing image change interpretation (RSICI) as a significant research focus. Current RSICI technology encompasses change detection and change captioning, each with its limitations in providing comprehensive interpretation. To address this, we propose an interactive Change-Agent, which can follow user instructions to achieve comprehensive change interpretation and insightful analysis according to user instructions, such as change detection and change captioning, change object counting, change cause analysis, etc. The Change-Agent integrates a multi-level change interpretation (MCI) model as the eyes and a large language model (LLM) as the brain. The MCI model contains two branches of pixel-level change detection and semantic-level change captioning, in which multiple BI-temporal Iterative Interaction (BI3) layers utilize Local Perception Enhancement (LPE) and the Global Difference Fusion Attention (GDFA) modules to enhance the model's discriminative feature representation capabilities. To support the training of the MCI model, we build the LEVIR-MCI dataset with a large number of change masks and captions of changes. Extensive experiments demonstrate the effectiveness of the proposed MCI model and highlight the promising potential of our Change-Agent in facilitating comprehensive and intelligent interpretation of surface changes. To facilitate future research, we will make our dataset and codebase of the MCI model and Change-Agent publicly available at https://github.com/Chen-Yang-Liu/Change-Agent
A Differentially Private Clustering Algorithm for Well-Clustered Graphs
Mar 21, 2024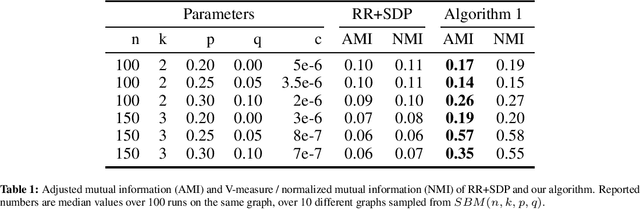
We study differentially private (DP) algorithms for recovering clusters in well-clustered graphs, which are graphs whose vertex set can be partitioned into a small number of sets, each inducing a subgraph of high inner conductance and small outer conductance. Such graphs have widespread application as a benchmark in the theoretical analysis of spectral clustering. We provide an efficient ($\epsilon$,$\delta$)-DP algorithm tailored specifically for such graphs. Our algorithm draws inspiration from the recent work of Chen et al., who developed DP algorithms for recovery of stochastic block models in cases where the graph comprises exactly two nearly-balanced clusters. Our algorithm works for well-clustered graphs with $k$ nearly-balanced clusters, and the misclassification ratio almost matches the one of the best-known non-private algorithms. We conduct experimental evaluations on datasets with known ground truth clusters to substantiate the prowess of our algorithm. We also show that any (pure) $\epsilon$-DP algorithm would result in substantial error.
When Semantic Segmentation Meets Frequency Aliasing
Mar 25, 2024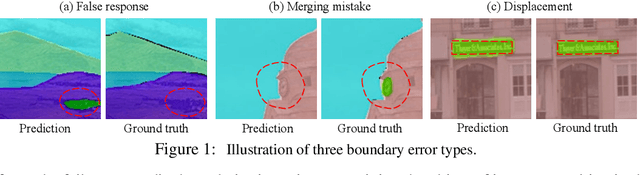
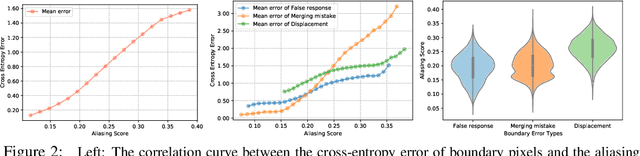

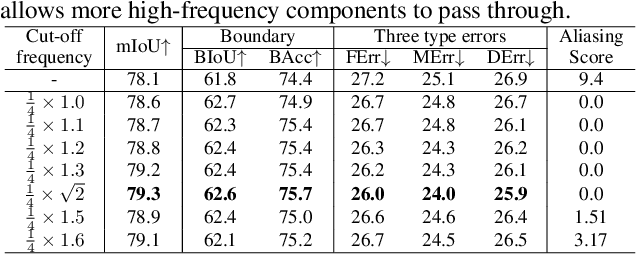
Despite recent advancements in semantic segmentation, where and what pixels are hard to segment remains largely unexplored. Existing research only separates an image into easy and hard regions and empirically observes the latter are associated with object boundaries. In this paper, we conduct a comprehensive analysis of hard pixel errors, categorizing them into three types: false responses, merging mistakes, and displacements. Our findings reveal a quantitative association between hard pixels and aliasing, which is distortion caused by the overlapping of frequency components in the Fourier domain during downsampling. To identify the frequencies responsible for aliasing, we propose using the equivalent sampling rate to calculate the Nyquist frequency, which marks the threshold for aliasing. Then, we introduce the aliasing score as a metric to quantify the extent of aliasing. While positively correlated with the proposed aliasing score, three types of hard pixels exhibit different patterns. Here, we propose two novel de-aliasing filter (DAF) and frequency mixing (FreqMix) modules to alleviate aliasing degradation by accurately removing or adjusting frequencies higher than the Nyquist frequency. The DAF precisely removes the frequencies responsible for aliasing before downsampling, while the FreqMix dynamically selects high-frequency components within the encoder block. Experimental results demonstrate consistent improvements in semantic segmentation and low-light instance segmentation tasks. The code is available at: https://github.com/Linwei-Chen/Seg-Aliasing.
A Lie Group Approach to Riemannian Batch Normalization
Mar 17, 2024

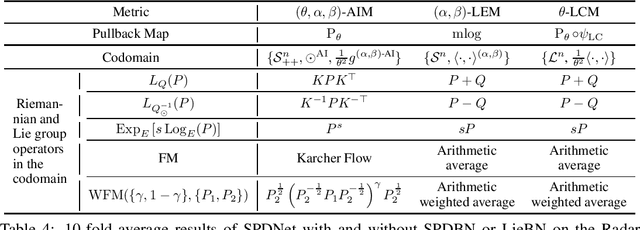
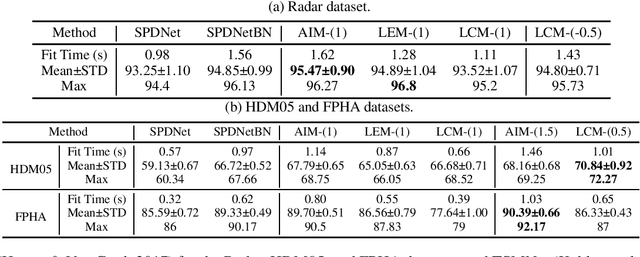
Manifold-valued measurements exist in numerous applications within computer vision and machine learning. Recent studies have extended Deep Neural Networks (DNNs) to manifolds, and concomitantly, normalization techniques have also been adapted to several manifolds, referred to as Riemannian normalization. Nonetheless, most of the existing Riemannian normalization methods have been derived in an ad hoc manner and only apply to specific manifolds. This paper establishes a unified framework for Riemannian Batch Normalization (RBN) techniques on Lie groups. Our framework offers the theoretical guarantee of controlling both the Riemannian mean and variance. Empirically, we focus on Symmetric Positive Definite (SPD) manifolds, which possess three distinct types of Lie group structures. Using the deformation concept, we generalize the existing Lie groups on SPD manifolds into three families of parameterized Lie groups. Specific normalization layers induced by these Lie groups are then proposed for SPD neural networks. We demonstrate the effectiveness of our approach through three sets of experiments: radar recognition, human action recognition, and electroencephalography (EEG) classification. The code is available at https://github.com/GitZH-Chen/LieBN.git.