 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Ding": models, code, and papers
Repeated Padding as Data Augmentation for Sequential Recommendation
Mar 11, 2024
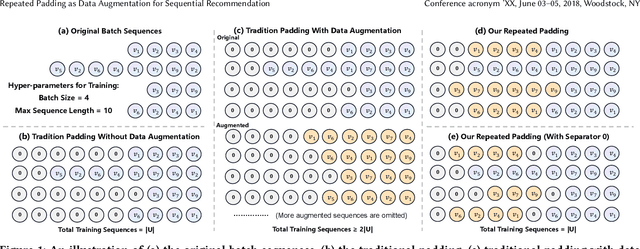


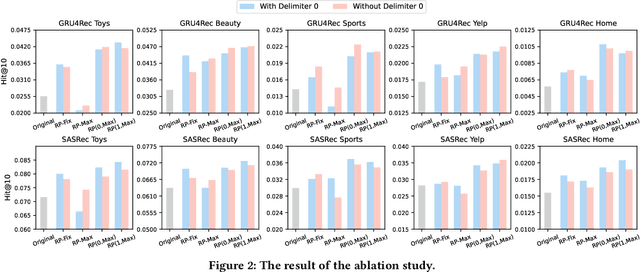
Sequential recommendation aims to provide users with personalized suggestions based on their historical interactions. When training sequential models, padding is a widely adopted technique for two main reasons: 1) The vast majority of models can only handle fixed-length sequences; 2) Batching-based training needs to ensure that the sequences in each batch have the same length. The special value \emph{0} is usually used as the padding content, which does not contain the actual information and is ignored in the model calculations. This common-sense padding strategy leads us to a problem that has never been explored before: \emph{Can we fully utilize this idle input space by padding other content to further improve model performance and training efficiency?} In this paper, we propose a simple yet effective padding method called \textbf{Rep}eated \textbf{Pad}ding (\textbf{RepPad}). Specifically, we use the original interaction sequences as the padding content and fill it to the padding positions during model training. This operation can be performed a finite number of times or repeated until the input sequences' length reaches the maximum limit. Our RepPad can be viewed as a sequence-level data augmentation strategy. Unlike most existing works, our method contains no trainable parameters or hyperparameters and is a plug-and-play data augmentation operation. Extensive experiments on various categories of sequential models and five real-world datasets demonstrate the effectiveness and efficiency of our approach. The average recommendation performance improvement is up to 60.3\% on GRU4Rec and 24.3\% on SASRec. We also provide in-depth analysis and explanation of what makes RepPad effective from multiple perspectives. The source code will be released to ensure the reproducibility of our experiments.
Multilingual transformer and BERTopic for short text topic modeling: The case of Serbian
Feb 05, 2024This paper presents the results of the first application of BERTopic, a state-of-the-art topic modeling technique, to short text written in a morphologi-cally rich language. We applied BERTopic with three multilingual embed-ding models on two levels of text preprocessing (partial and full) to evalu-ate its performance on partially preprocessed short text in Serbian. We also compared it to LDA and NMF on fully preprocessed text. The experiments were conducted on a dataset of tweets expressing hesitancy toward COVID-19 vaccination. Our results show that with adequate parameter setting, BERTopic can yield informative topics even when applied to partially pre-processed short text. When the same parameters are applied in both prepro-cessing scenarios, the performance drop on partially preprocessed text is minimal. Compared to LDA and NMF, judging by the keywords, BERTopic offers more informative topics and gives novel insights when the number of topics is not limited. The findings of this paper can be significant for re-searchers working with other morphologically rich low-resource languages and short text.
A note on the capacity of the binary perceptron
Jan 22, 2024Determining the capacity $\alpha_c$ of the Binary Perceptron is a long-standing problem. Krauth and Mezard (1989) conjectured an explicit value of $\alpha_c$, approximately equal to .833, and a rigorous lower bound matching this prediction was recently established by Ding and Sun (2019). Regarding the upper bound, Kim and Roche (1998) and Talagrand (1999) independently showed that $\alpha_c$ < .996, while Krauth and Mezard outlined an argument which can be used to show that $\alpha_c$ < .847. The purpose of this expository note is to record a complete proof of the bound $\alpha_c$ < .847. The proof is a conditional first moment method combined with known results on the spherical perceptron
Efficiently matching random inhomogeneous graphs via degree profiles
Oct 16, 2023In this paper, we study the problem of recovering the latent vertex correspondence between two correlated random graphs with vastly inhomogeneous and unknown edge probabilities between different pairs of vertices. Inspired by and extending the matching algorithm via degree profiles by Ding, Ma, Wu and Xu (2021), we obtain an efficient matching algorithm as long as the minimal average degree is at least $\Omega(\log^{2} n)$ and the minimal correlation is at least $1 - O(\log^{-2} n)$.
MASA-TCN: Multi-anchor Space-aware Temporal Convolutional Neural Networks for Continuous and Discrete EEG Emotion Recognition
Aug 30, 2023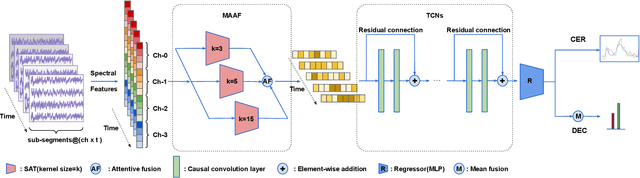
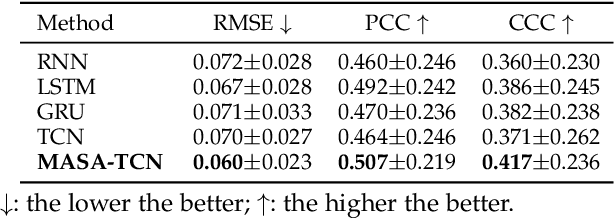
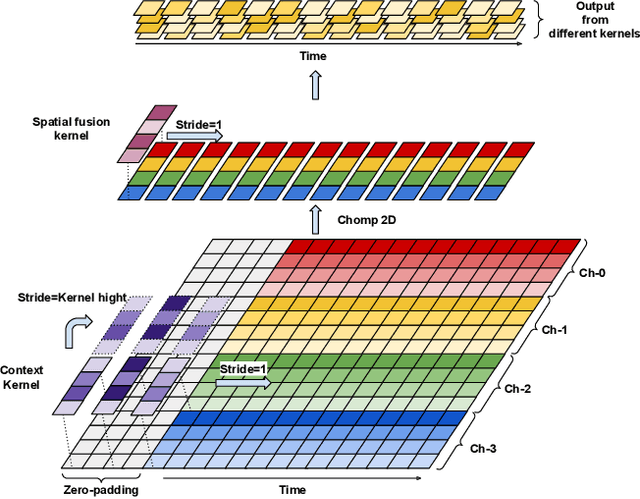
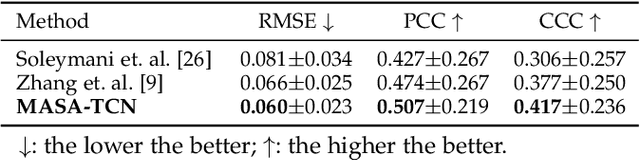
Emotion recognition using electroencephalogram (EEG) mainly has two scenarios: classification of the discrete labels and regression of the continuously tagged labels. Although many algorithms were proposed for classification tasks, there are only a few methods for regression tasks. For emotion regression, the label is continuous in time. A natural method is to learn the temporal dynamic patterns. In previous studies, long short-term memory (LSTM) and temporal convolutional neural networks (TCN) were utilized to learn the temporal contextual information from feature vectors of EEG. However, the spatial patterns of EEG were not effectively extracted. To enable the spatial learning ability of TCN towards better regression and classification performances, we propose a novel unified model, named MASA-TCN, for EEG emotion regression and classification tasks. The space-aware temporal layer enables TCN to additionally learn from spatial relations among EEG electrodes. Besides, a novel multi-anchor block with attentive fusion is proposed to learn dynamic temporal dependencies. Experiments on two publicly available datasets show MASA-TCN achieves higher results than the state-of-the-art methods for both EEG emotion regression and classification tasks. The code is available at https://github.com/yi-ding-cs/MASA-TCN.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023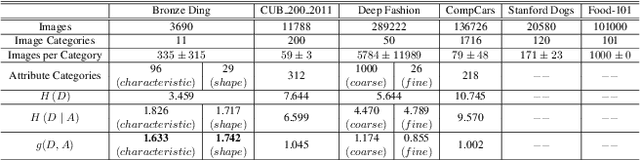

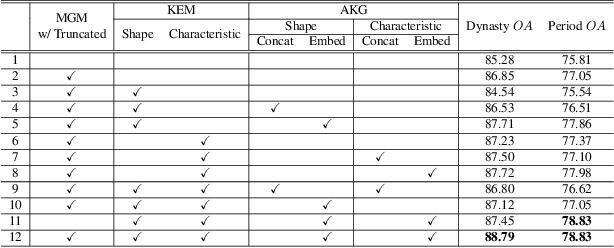
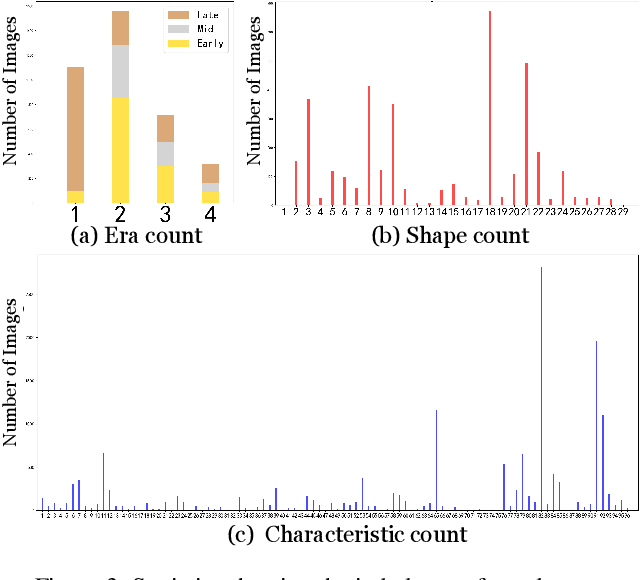
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.
A Multi-Party Dialogue Ressource in French
Jul 25, 2022
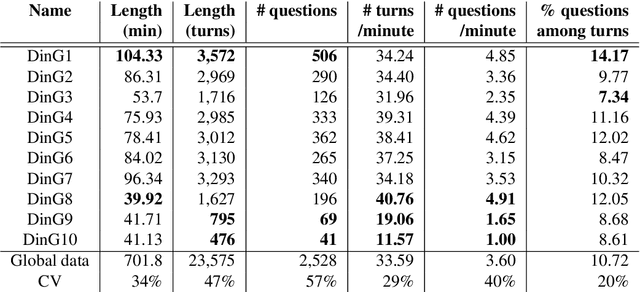
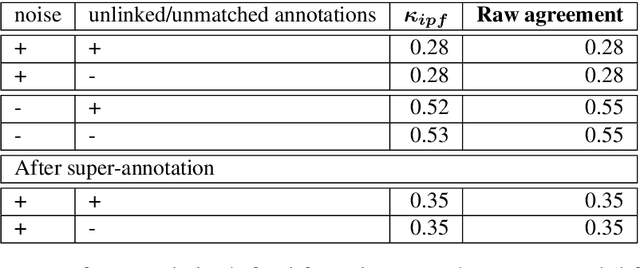

We present Dialogues in Games (DinG), a corpus of manual transcriptions of real-life, oral, spontaneous multi-party dialogues between French-speaking players of the board game Catan. Our objective is to make available a quality resource for French, composed of long dialogues, to facilitate their study in the style of (Asher et al., 2016). In a general dialogue setting, participants share personal information, which makes it impossible to disseminate the resource freely and openly. In DinG, the attention of the participants is focused on the game, which prevents them from talking about themselves. In addition, we are conducting a study on the nature of the questions in dialogue, through annotation (Cruz Blandon et al., 2019), in order to develop more natural automatic dialogue systems.
LANDMARK: Language-guided Representation Enhancement Framework for Scene Graph Generation
Mar 02, 2023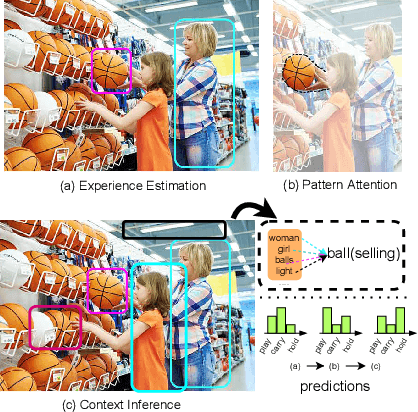
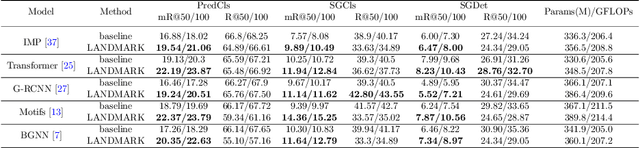
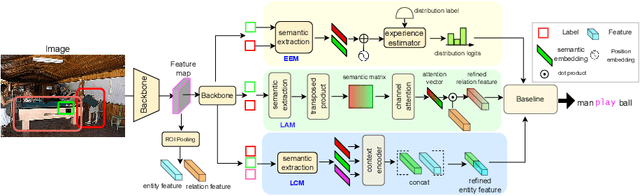
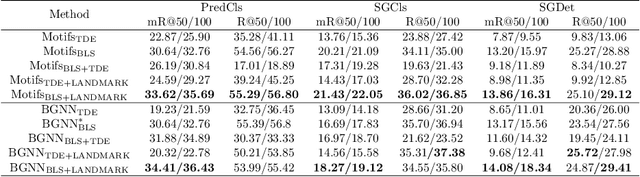
Scene graph generation (SGG) is a sophisticated task that suffers from both complex visual features and dataset long-tail problem. Recently, various unbiased strategies have been proposed by designing novel loss functions and data balancing strategies. Unfortunately, these unbiased methods fail to emphasize language priors in feature refinement perspective. Inspired by the fact that predicates are highly correlated with semantics hidden in subject-object pair and global context, we propose LANDMARK (LANguage-guiDed representationenhanceMent frAmewoRK) that learns predicate-relevant representations from language-vision interactive patterns, global language context and pair-predicate correlation. Specifically, we first project object labels to three distinctive semantic embeddings for different representation learning. Then, Language Attention Module (LAM) and Experience Estimation Module (EEM) process subject-object word embeddings to attention vector and predicate distribution, respectively. Language Context Module (LCM) encodes global context from each word embed-ding, which avoids isolated learning from local information. Finally, modules outputs are used to update visual representations and SGG model's prediction. All language representations are purely generated from object categories so that no extra knowledge is needed. This framework is model-agnostic and consistently improves performance on existing SGG models. Besides, representation-level unbiased strategies endow LANDMARK the advantage of compatibility with other methods. Code is available at https://github.com/rafa-cxg/PySGG-cxg.
The Neural Correlates of Linguistic Structure Building: Comments on Kazanina & Tavano (2022)
Dec 08, 2022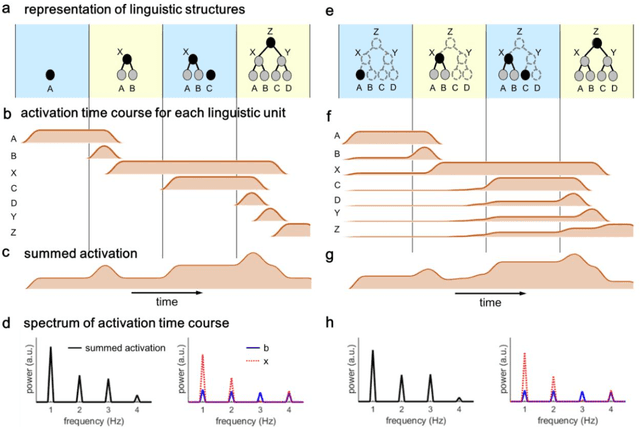
A recent perspective paper by Kazanina & Tavano (referred to as the KT perspective in the following) argues how neural oscillations cannot provide a potential neural correlate for syntactic structure building. The view that neural oscillations can provide a potential neural correlate for syntactic structure building is largely attributed to a study by Ding, Melloni, Zhang, Tian, and Poeppel in 2016 (referred to as the DMZTP study). The KT perspective is thought provoking, but has severe misinterpretations about the arguments in DMZTP and other studies, and contains contradictory conclusions in different parts of the perspective, making it impossible to understand the position of the authors. In the following, I summarize a few misinterpretations and inconsistent arguments in the KT perspective, and put forward a few suggestions for future studies.
Solving clustering as ill-posed problem: experiments with K-Means algorithm
Nov 15, 2022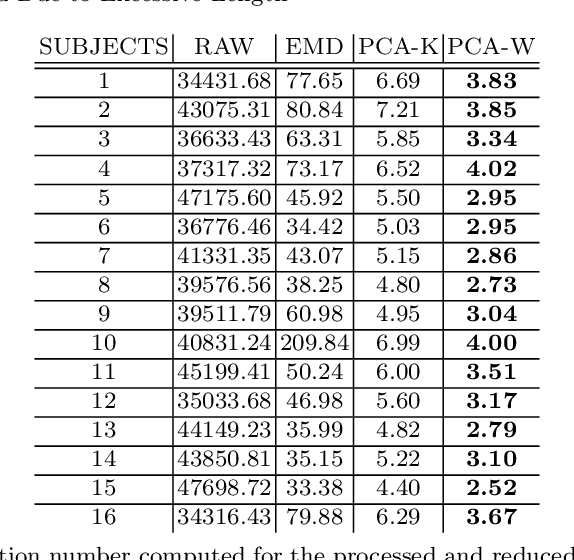
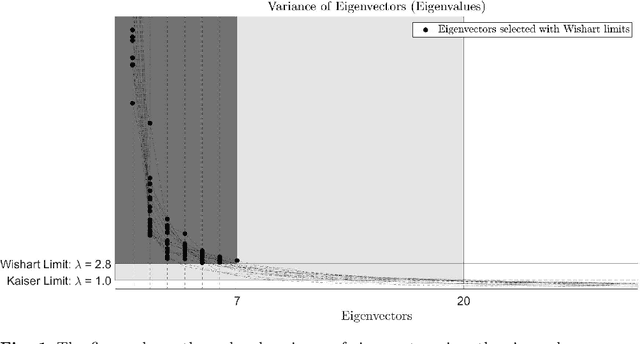
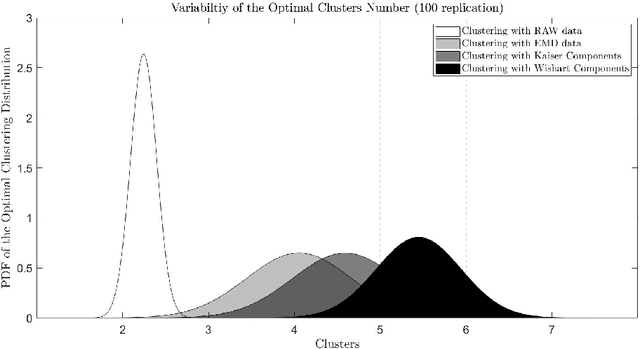
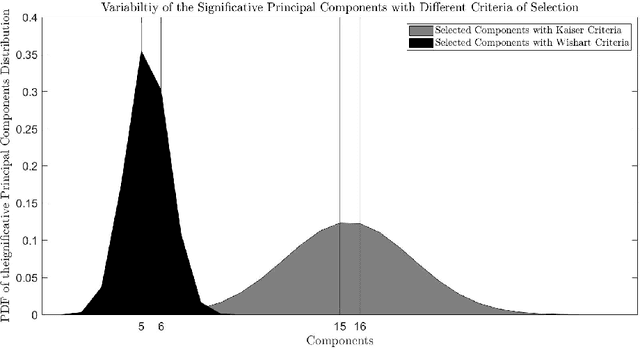
In this contribution, the clustering procedure based on K-Means algorithm is studied as an inverse problem, which is a special case of the illposed problems. The attempts to improve the quality of the clustering inverse problem drive to reduce the input data via Principal Component Analysis (PCA). Since there exists a theorem by Ding and He that links the cardinality of the optimal clusters found with K-Means and the cardinality of the selected informative PCA components, the computational experiments tested the theorem between two quantitative features selection methods: Kaiser criteria (based on imperative decision) versus Wishart criteria (based on random matrix theory). The results suggested that PCA reduction with features selection by Wishart criteria leads to a low matrix condition number and satisfies the relation between clusters and components predicts by the theorem. The data used for the computations are from a neuroscientific repository: it regards healthy and young subjects that performed a task-oriented functional Magnetic Resonance Imaging (fMRI) paradigm.