 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Jorge": models, code, and papers
Jorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
Oct 27, 2023
Despite their better convergence properties compared to first-order optimizers, second-order optimizers for deep learning have been less popular due to their significant computational costs. The primary efficiency bottleneck in such optimizers is matrix inverse calculations in the preconditioning step, which are expensive to compute on GPUs. In this paper, we introduce Jorge, a second-order optimizer that promises the best of both worlds -- rapid convergence benefits of second-order methods, and high computational efficiency typical of first-order methods. We address the primary computational bottleneck of computing matrix inverses by completely eliminating them using an approximation of the preconditioner computation. This makes Jorge extremely efficient on GPUs in terms of wall-clock time. Further, we describe an approach to determine Jorge's hyperparameters directly from a well-tuned SGD baseline, thereby significantly minimizing tuning efforts. Our empirical evaluations demonstrate the distinct advantages of using Jorge, outperforming state-of-the-art optimizers such as SGD, AdamW, and Shampoo across multiple deep learning models, both in terms of sample efficiency and wall-clock time.
Source Code Clone Detection Using Unsupervised Similarity Measures
Jan 19, 2024Assessing similarity in source code has gained significant attention in recent years due to its importance in software engineering tasks such as clone detection and code search and recommendation. This work presents a comparative analysis of unsupervised similarity measures for identifying source code clone detection. The goal is to overview the current state-of-the-art techniques, their strengths, and weaknesses. To do that, we compile the existing unsupervised strategies and evaluate their performance on a benchmark dataset to guide software engineers in selecting appropriate methods for their specific use cases. The source code of this study is available at https://github.com/jorge-martinez-gil/codesim
Borges and AI
Oct 04, 2023Many believe that Large Language Models (LLMs) open the era of Artificial Intelligence (AI). Some see opportunities while others see dangers. Yet both proponents and opponents grasp AI through the imagery popularised by science fiction. Will the machine become sentient and rebel against its creators? Will we experience a paperclip apocalypse? Before answering such questions, we should first ask whether this mental imagery provides a good description of the phenomenon at hand. Understanding weather patterns through the moods of the gods only goes so far. The present paper instead advocates understanding LLMs and their connection to AI through the imagery of Jorge Luis Borges, a master of 20th century literature, forerunner of magical realism, and precursor to postmodern literature. This exercise leads to a new perspective that illuminates the relation between language modelling and artificial intelligence.
Framework to Automatically Determine the Quality of Open Data Catalogs
Aug 14, 2023Data catalogs play a crucial role in modern data-driven organizations by facilitating the discovery, understanding, and utilization of diverse data assets. However, ensuring their quality and reliability is complex, especially in open and large-scale data environments. This paper proposes a framework to automatically determine the quality of open data catalogs, addressing the need for efficient and reliable quality assessment mechanisms. Our framework can analyze various core quality dimensions, such as accuracy, completeness, consistency, scalability, and timeliness, offer several alternatives for the assessment of compatibility and similarity across such catalogs as well as the implementation of a set of non-core quality dimensions such as provenance, readability, and licensing. The goal is to empower data-driven organizations to make informed decisions based on trustworthy and well-curated data assets. The source code that illustrates our approach can be downloaded from https://www.github.com/jorge-martinez-gil/dataq/.
Optimizing Readability Using Genetic Algorithms
Jan 01, 2023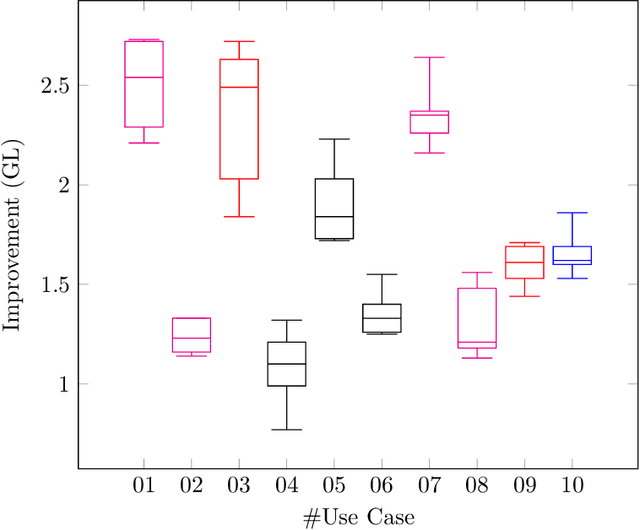
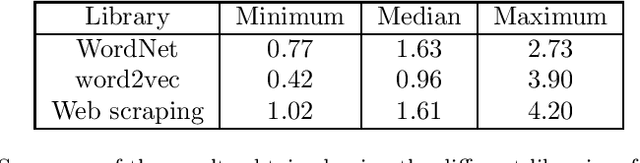
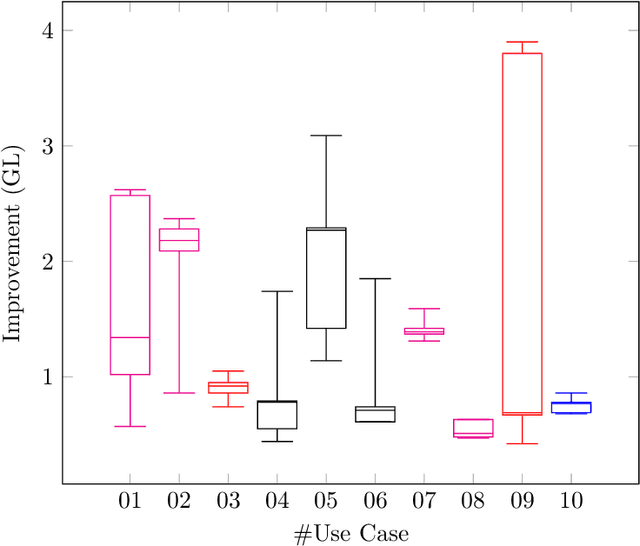
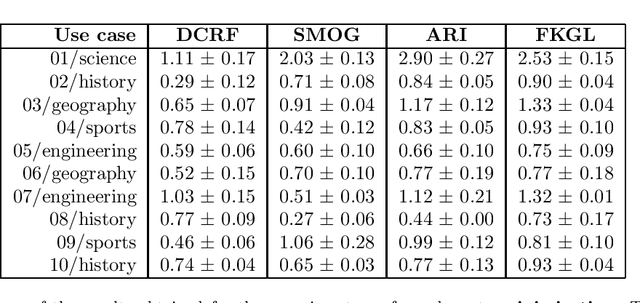
This research presents ORUGA, a method that tries to automatically optimize the readability of any text in English. The core idea behind the method is that certain factors affect the readability of a text, some of which are quantifiable (number of words, syllables, presence or absence of adverbs, and so on). The nature of these factors allows us to implement a genetic learning strategy to replace some existing words with their most suitable synonyms to facilitate optimization. In addition, this research seeks to preserve both the original text's content and form through multi-objective optimization techniques. In this way, neither the text's syntactic structure nor the semantic content of the original message is significantly distorted. An exhaustive study on a substantial number and diversity of texts confirms that our method was able to optimize the degree of readability in all cases without significantly altering their form or meaning. The source code of this approach is available at https://github.com/jorge-martinez-gil/oruga.