 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Krishnamurthy": models, code, and papers
Contextual Bandits with Online Neural Regression
Dec 12, 2023
Recent works have shown a reduction from contextual bandits to online regression under a realizability assumption [Foster and Rakhlin, 2020, Foster and Krishnamurthy, 2021]. In this work, we investigate the use of neural networks for such online regression and associated Neural Contextual Bandits (NeuCBs). Using existing results for wide networks, one can readily show a ${\mathcal{O}}(\sqrt{T})$ regret for online regression with square loss, which via the reduction implies a ${\mathcal{O}}(\sqrt{K} T^{3/4})$ regret for NeuCBs. Departing from this standard approach, we first show a $\mathcal{O}(\log T)$ regret for online regression with almost convex losses that satisfy QG (Quadratic Growth) condition, a generalization of the PL (Polyak-\L ojasiewicz) condition, and that have a unique minima. Although not directly applicable to wide networks since they do not have unique minima, we show that adding a suitable small random perturbation to the network predictions surprisingly makes the loss satisfy QG with unique minima. Based on such a perturbed prediction, we show a ${\mathcal{O}}(\log T)$ regret for online regression with both squared loss and KL loss, and subsequently convert these respectively to $\tilde{\mathcal{O}}(\sqrt{KT})$ and $\tilde{\mathcal{O}}(\sqrt{KL^*} + K)$ regret for NeuCB, where $L^*$ is the loss of the best policy. Separately, we also show that existing regret bounds for NeuCBs are $\Omega(T)$ or assume i.i.d. contexts, unlike this work. Finally, our experimental results on various datasets demonstrate that our algorithms, especially the one based on KL loss, persistently outperform existing algorithms.
Corruption-Robust Contextual Search through Density Updates
Jun 15, 2022
We study the problem of contextual search in the adversarial noise model. Let $d$ be the dimension of the problem, $T$ be the time horizon and $C$ be the total amount of noise in the system. For the $\eps$-ball loss, we give a tight regret bound of $O(C + d \log(1/\eps))$ improving over the $O(d^3 \log(1/\eps)) \log^2(T) + C \log(T) \log(1/\eps))$ bound of Krishnamurthy et al (STOC21). For the symmetric loss, we give an efficient algorithm with regret $O(C+d \log T)$. Our techniques are a significant departure from prior approaches. Specifically, we keep track of density functions over the candidate vectors instead of a knowledge set consisting of the candidate vectors consistent with the feedback obtained.
Adapting to misspecification in contextual bandits with offline regression oracles
Feb 26, 2021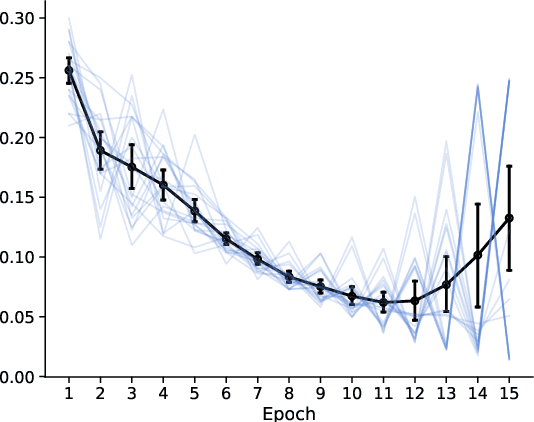
Computationally efficient contextual bandits are often based on estimating a predictive model of rewards given contexts and arms using past data. However, when the reward model is not well-specified, the bandit algorithm may incur unexpected regret, so recent work has focused on algorithms that are robust to misspecification. We propose a simple family of contextual bandit algorithms that adapt to misspecification error by reverting to a good safe policy when there is evidence that misspecification is causing a regret increase. Our algorithm requires only an offline regression oracle to ensure regret guarantees that gracefully degrade in terms of a measure of the average misspecification level. Compared to prior work, we attain similar regret guarantees, but we do no rely on a master algorithm, and do not require more robust oracles like online or constrained regression oracles (e.g., Foster et al. (2020a); Krishnamurthy et al. (2020)). This allows us to design algorithms for more general function approximation classes.
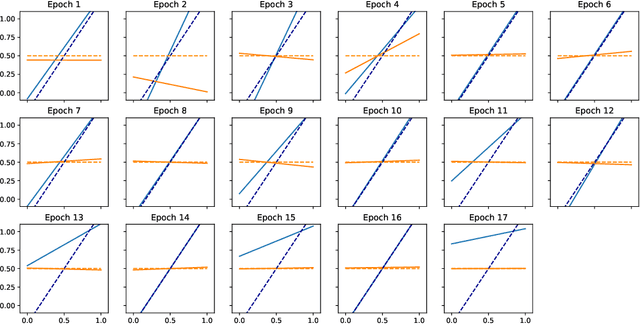
Efficient First-Order Contextual Bandits: Prediction, Allocation, and Triangular Discrimination
Jul 05, 2021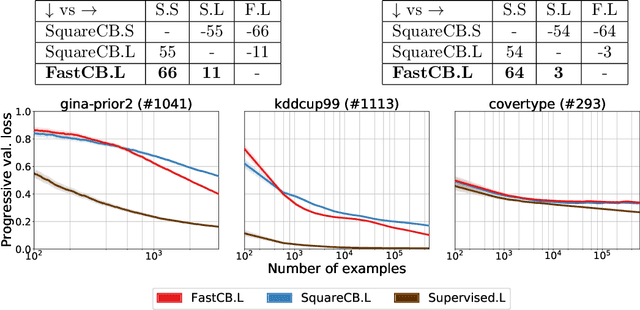
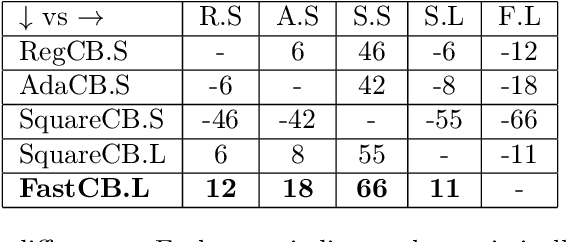
A recurring theme in statistical learning, online learning, and beyond is that faster convergence rates are possible for problems with low noise, often quantified by the performance of the best hypothesis; such results are known as first-order or small-loss guarantees. While first-order guarantees are relatively well understood in statistical and online learning, adapting to low noise in contextual bandits (and more broadly, decision making) presents major algorithmic challenges. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire asked whether first-order guarantees are even possible for contextual bandits and -- if so -- whether they can be attained by efficient algorithms. We give a resolution to this question by providing an optimal and efficient reduction from contextual bandits to online regression with the logarithmic (or, cross-entropy) loss. Our algorithm is simple and practical, readily accommodates rich function classes, and requires no distributional assumptions beyond realizability. In a large-scale empirical evaluation, we find that our approach typically outperforms comparable non-first-order methods. On the technical side, we show that the logarithmic loss and an information-theoretic quantity called the triangular discrimination play a fundamental role in obtaining first-order guarantees, and we combine this observation with new refinements to the regression oracle reduction framework of Foster and Rakhlin. The use of triangular discrimination yields novel results even for the classical statistical learning model, and we anticipate that it will find broader use.
Recovery of Sparse Signals from a Mixture of Linear Samples
Jul 14, 2020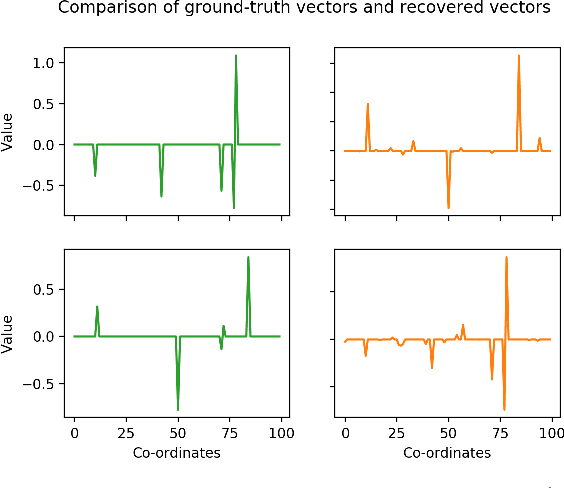
Mixture of linear regressions is a popular learning theoretic model that is used widely to represent heterogeneous data. In the simplest form, this model assumes that the labels are generated from either of two different linear models and mixed together. Recent works of Yin et al. and Krishnamurthy et al., 2019, focus on an experimental design setting of model recovery for this problem. It is assumed that the features can be designed and queried with to obtain their label. When queried, an oracle randomly selects one of the two different sparse linear models and generates a label accordingly. How many such oracle queries are needed to recover both of the models simultaneously? This question can also be thought of as a generalization of the well-known compressed sensing problem (Cand\`es and Tao, 2005, Donoho, 2006). In this work, we address this query complexity problem and provide efficient algorithms that improves on the previously best known results.
Make the Minority Great Again: First-Order Regret Bound for Contextual Bandits
Feb 09, 2018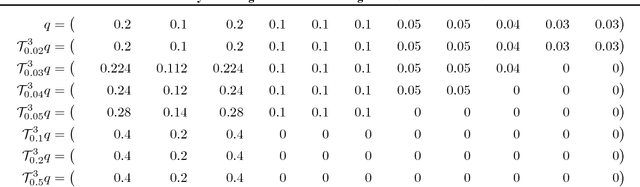
Regret bounds in online learning compare the player's performance to $L^*$, the optimal performance in hindsight with a fixed strategy. Typically such bounds scale with the square root of the time horizon $T$. The more refined concept of first-order regret bound replaces this with a scaling $\sqrt{L^*}$, which may be much smaller than $\sqrt{T}$. It is well known that minor variants of standard algorithms satisfy first-order regret bounds in the full information and multi-armed bandit settings. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire raised the issue that existing techniques do not seem sufficient to obtain first-order regret bounds for the contextual bandit problem. In the present paper, we resolve this open problem by presenting a new strategy based on augmenting the policy space.
Provably Correct Algorithms for Matrix Column Subset Selection with Selectively Sampled Data
Jan 25, 2018
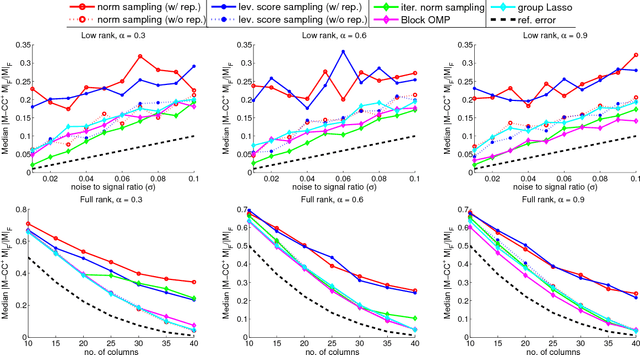
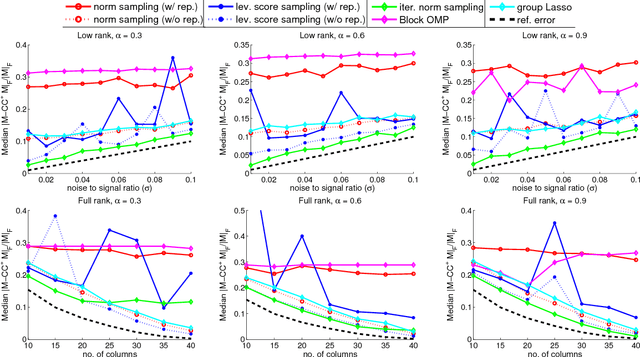

We consider the problem of matrix column subset selection, which selects a subset of columns from an input matrix such that the input can be well approximated by the span of the selected columns. Column subset selection has been applied to numerous real-world data applications such as population genetics summarization, electronic circuits testing and recommendation systems. In many applications the complete data matrix is unavailable and one needs to select representative columns by inspecting only a small portion of the input matrix. In this paper we propose the first provably correct column subset selection algorithms for partially observed data matrices. Our proposed algorithms exhibit different merits and limitations in terms of statistical accuracy, computational efficiency, sample complexity and sampling schemes, which provides a nice exploration of the tradeoff between these desired properties for column subset selection. The proposed methods employ the idea of feedback driven sampling and are inspired by several sampling schemes previously introduced for low-rank matrix approximation tasks (Drineas et al., 2008; Frieze et al., 2004; Deshpande and Vempala, 2006; Krishnamurthy and Singh, 2014). Our analysis shows that, under the assumption that the input data matrix has incoherent rows but possibly coherent columns, all algorithms provably converge to the best low-rank approximation of the original data as number of selected columns increases. Furthermore, two of the proposed algorithms enjoy a relative error bound, which is preferred for column subset selection and matrix approximation purposes. We also demonstrate through both theoretical and empirical analysis the power of feedback driven sampling compared to uniform random sampling on input matrices with highly correlated columns.