 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Member": models, code, and papers
Design and Analysis of Efficient Attention in Transformers for Social Group Activity Recognition
Apr 15, 2024
Social group activity recognition is a challenging task extended from group activity recognition, where social groups must be recognized with their activities and group members. Existing methods tackle this task by leveraging region features of individuals following existing group activity recognition methods. However, the effectiveness of region features is susceptible to person localization and variable semantics of individual actions. To overcome these issues, we propose leveraging attention modules in transformers to generate social group features. In this method, multiple embeddings are used to aggregate features for a social group, each of which is assigned to a group member without duplication. Due to this non-duplicated assignment, the number of embeddings must be significant to avoid missing group members and thus renders attention in transformers ineffective. To find optimal attention designs with a large number of embeddings, we explore several design choices of queries for feature aggregation and self-attention modules in transformer decoders. Extensive experimental results show that the proposed method achieves state-of-the-art performance and verify that the proposed attention designs are highly effective on social group activity recognition.
Quality check of a sample partition using multinomial distribution
Apr 11, 2024In this paper, we advocate a novel measure for the purpose of checking the quality of a cluster partition for a sample into several distinct classes, and thus, determine the unknown value for the true number of clusters prevailing the provided set of data. Our objective leads us to the development of an approach through applying the multinomial distribution to the distances of data members, clustered in a group, from their respective cluster representatives. This procedure is carried out independently for each of the clusters, and the concerned statistics are combined together to design our targeted measure. Individual clusters separately possess the category-wise probabilities which correspond to different positions of its members in the cluster with respect to a typical member, in the form of cluster-centroid, medoid or mode, referred to as the corresponding cluster representative. Our method is robust in the sense that it is distribution-free, since this is devised irrespective of the parent distribution of the underlying sample. It fulfills one of the rare coveted qualities, present in the existing cluster accuracy measures, of having the capability to investigate whether the assigned sample owns any inherent clusters other than a single group of all members or not. Our measure's simple concept, easy algorithm, fast runtime, good performance, and wide usefulness, demonstrated through extensive simulation and diverse case-studies, make it appealing.
Robust Few-Shot Ensemble Learning with Focal Diversity-Based Pruning
Apr 05, 2024This paper presents FusionShot, a focal diversity optimized few-shot ensemble learning approach for boosting the robustness and generalization performance of pre-trained few-shot models. The paper makes three original contributions. First, we explore the unique characteristics of few-shot learning to ensemble multiple few-shot (FS) models by creating three alternative fusion channels. Second, we introduce the concept of focal error diversity to learn the most efficient ensemble teaming strategy, rather than assuming that an ensemble of a larger number of base models will outperform those sub-ensembles of smaller size. We develop a focal-diversity ensemble pruning method to effectively prune out the candidate ensembles with low ensemble error diversity and recommend top-$K$ FS ensembles with the highest focal error diversity. Finally, we capture the complex non-linear patterns of ensemble few-shot predictions by designing the learn-to-combine algorithm, which can learn the diverse weight assignments for robust ensemble fusion over different member models. Extensive experiments on representative few-shot benchmarks show that the top-K ensembles recommended by FusionShot can outperform the representative SOTA few-shot models on novel tasks (different distributions and unknown at training), and can prevail over existing few-shot learners in both cross-domain settings and adversarial settings. For reproducibility purposes, FusionShot trained models, results, and code are made available at https://github.com/sftekin/fusionshot
A Novel Algorithm for Digital Lithological Mapping-Case Studies in Sri Lanka's Mineral Exploration
Apr 01, 2024Conventional manual lithological mapping (MLM) through field surveys are resource-extensive and time-consuming. Digital lithological mapping (DLM), harnessing remotely sensed spectral imaging techniques, provides an effective strategy to streamline target locations for MLM or an efficient alternative to MLM. DLM relies on laboratory-generated generic end-member signatures of minerals for spectral analysis. Thus, the accuracy of DLM may be limited due to the presence of site-specific impurities. A strategy, based on a hybrid machine-learning and signal-processing algorithm, is proposed in this paper to tackle this problem of site-specific impurities. In addition, a soil pixel alignment strategy is proposed here to visualize the relative purity of the target minerals. The proposed methodologies are validated via case studies for mapping of Limestone deposits in Jaffna, Ilmenite deposits in Pulmoddai and Mannar, and Montmorillonite deposits in Murunkan, Sri Lanka. The results of satellite-based spectral imaging analysis were corroborated with X-ray diffraction (XRD) and Magnetic Separation (MS) analysis of soil samples collected from those sites via field surveys. There exists a good correspondence between the relative availability of the minerals with the XRD and MS results. In particular, correlation coefficients of 0.8115 and 0.9853 were found for the sites in Pulmoddai and Jaffna respectively.
Posterior Uncertainty Quantification in Neural Networks using Data Augmentation
Mar 18, 2024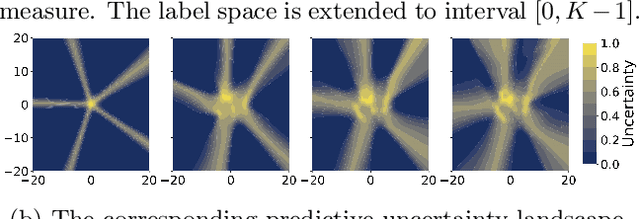
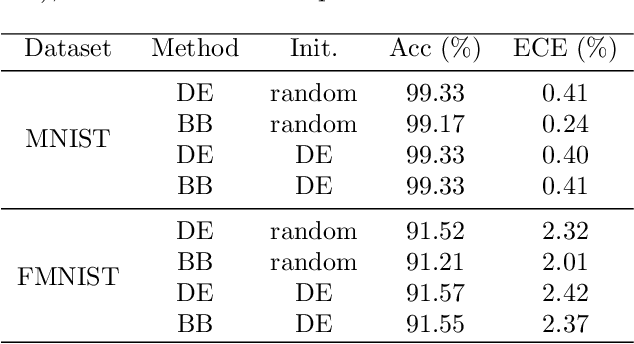

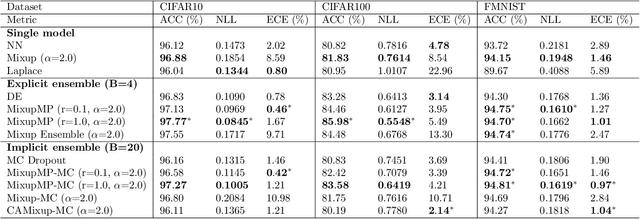
In this paper, we approach the problem of uncertainty quantification in deep learning through a predictive framework, which captures uncertainty in model parameters by specifying our assumptions about the predictive distribution of unseen future data. Under this view, we show that deep ensembling (Lakshminarayanan et al., 2017) is a fundamentally mis-specified model class, since it assumes that future data are supported on existing observations only -- a situation rarely encountered in practice. To address this limitation, we propose MixupMP, a method that constructs a more realistic predictive distribution using popular data augmentation techniques. MixupMP operates as a drop-in replacement for deep ensembles, where each ensemble member is trained on a random simulation from this predictive distribution. Grounded in the recently-proposed framework of Martingale posteriors (Fong et al., 2023), MixupMP returns samples from an implicitly defined Bayesian posterior. Our empirical analysis showcases that MixupMP achieves superior predictive performance and uncertainty quantification on various image classification datasets, when compared with existing Bayesian and non-Bayesian approaches.
AI-enhanced Collective Intelligence: The State of the Art and Prospects
Mar 19, 2024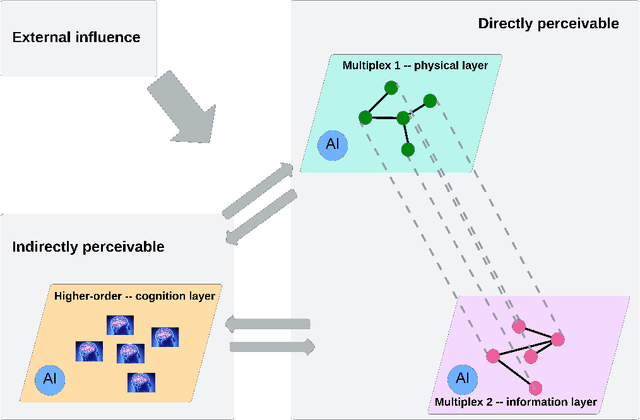
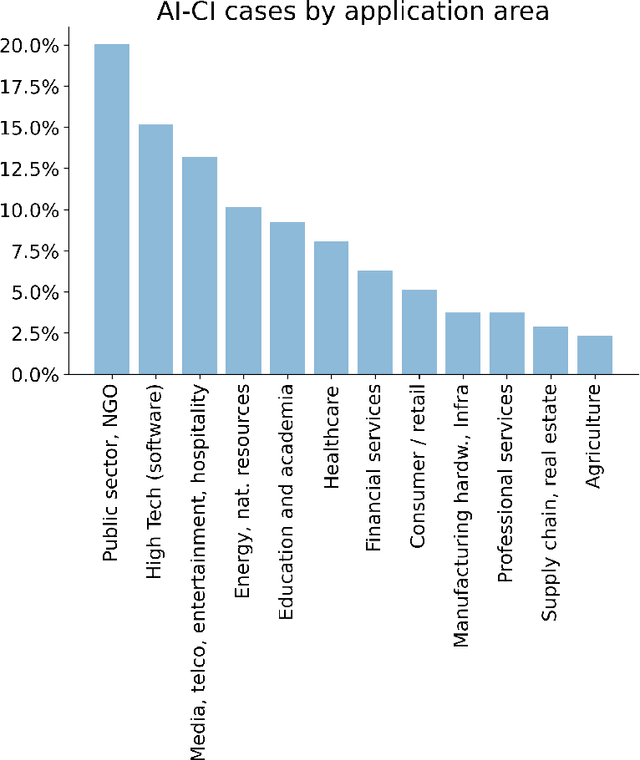
The current societal challenges exceed the capacity of human individual or collective effort alone. As AI evolves, its role within human collectives is poised to vary from an assistive tool to a participatory member. Humans and AI possess complementary capabilities that, when synergized, can achieve a level of collective intelligence that surpasses the collective capabilities of either humans or AI in isolation. However, the interactions in human-AI systems are inherently complex, involving intricate processes and interdependencies. This review incorporates perspectives from network science to conceptualize a multilayer representation of human-AI collective intelligence, comprising a cognition layer, a physical layer, and an information layer. Within this multilayer network, humans and AI agents exhibit varying characteristics; humans differ in diversity from surface-level to deep-level attributes, while AI agents range in degrees of functionality and anthropomorphism. The interplay among these agents shapes the overall structure and dynamics of the system. We explore how agents' diversity and interactions influence the system's collective intelligence. Furthermore, we present an analysis of real-world instances of AI-enhanced collective intelligence. We conclude by addressing the potential challenges in AI-enhanced collective intelligence and offer perspectives on future developments in this field.
LinkSAGE: Optimizing Job Matching Using Graph Neural Networks
Feb 20, 2024We present LinkSAGE, an innovative framework that integrates Graph Neural Networks (GNNs) into large-scale personalized job matching systems, designed to address the complex dynamics of LinkedIns extensive professional network. Our approach capitalizes on a novel job marketplace graph, the largest and most intricate of its kind in industry, with billions of nodes and edges. This graph is not merely extensive but also richly detailed, encompassing member and job nodes along with key attributes, thus creating an expansive and interwoven network. A key innovation in LinkSAGE is its training and serving methodology, which effectively combines inductive graph learning on a heterogeneous, evolving graph with an encoder-decoder GNN model. This methodology decouples the training of the GNN model from that of existing Deep Neural Nets (DNN) models, eliminating the need for frequent GNN retraining while maintaining up-to-date graph signals in near realtime, allowing for the effective integration of GNN insights through transfer learning. The subsequent nearline inference system serves the GNN encoder within a real-world setting, significantly reducing online latency and obviating the need for costly real-time GNN infrastructure. Validated across multiple online A/B tests in diverse product scenarios, LinkSAGE demonstrates marked improvements in member engagement, relevance matching, and member retention, confirming its generalizability and practical impact.
NuNER: Entity Recognition Encoder Pre-training via LLM-Annotated Data
Feb 23, 2024Large Language Models (LLMs) have shown impressive abilities in data annotation, opening the way for new approaches to solve classic NLP problems. In this paper, we show how to use LLMs to create NuNER, a compact language representation model specialized in the Named Entity Recognition (NER) task. NuNER can be fine-tuned to solve downstream NER problems in a data-efficient way, outperforming similar-sized foundation models in the few-shot regime and competing with much larger LLMs. We find that the size and entity-type diversity of the pre-training dataset are key to achieving good performance. We view NuNER as a member of the broader family of task-specific foundation models, recently unlocked by LLMs.
Learning to Retrieve for Job Matching
Feb 21, 2024Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
LongAgent: Scaling Language Models to 128k Context through Multi-Agent Collaboration
Feb 18, 2024Large language models (LLMs) have demonstrated impressive performance in understanding language and executing complex reasoning tasks. However, LLMs with long context windows have been notorious for their expensive training costs and high inference latency. Even the most advanced models such as GPT-4 and Claude2 often make mistakes when processing inputs of over $100k$ tokens, a phenomenon also known as \textit{lost in the middle}. In this paper, we propose \textsc{LongAgent}, a method based on multi-agent collaboration, which scales LLMs (e.g., LLaMA) to a context of 128K and demonstrates potential superiority in long-text processing compared to GPT-4. In \textsc{LongAgent}, a leader is responsible for understanding user intent and directing team members to acquire information from documents. Due to members' hallucinations, it is non-trivial for a leader to obtain accurate information from the responses of dozens to hundreds of members. To address this, we develop an \textit{inter-member communication} mechanism to resolve response conflicts caused by hallucinations through information sharing. Our experimental results indicate that \textsc{LongAgent} offers a promising alternative for long-text processing. The agent team instantiated with LLaMA-7B achieves significant improvements in tasks such as 128k-long text retrieval, multi-hop question answering, compared to GPT-4.