 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmartya Sanyal
Provable Privacy with Non-Private Pre-Processing
Mar 19, 2024

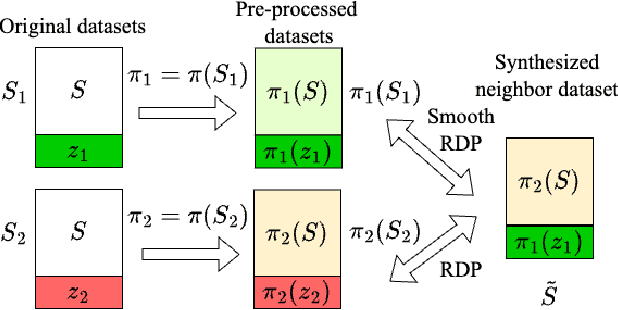

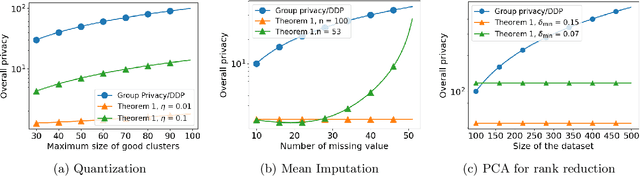
When analysing Differentially Private (DP) machine learning pipelines, the potential privacy cost of data-dependent pre-processing is frequently overlooked in privacy accounting. In this work, we propose a general framework to evaluate the additional privacy cost incurred by non-private data-dependent pre-processing algorithms. Our framework establishes upper bounds on the overall privacy guarantees by utilising two new technical notions: a variant of DP termed Smooth DP and the bounded sensitivity of the pre-processing algorithms. In addition to the generic framework, we provide explicit overall privacy guarantees for multiple data-dependent pre-processing algorithms, such as data imputation, quantization, deduplication and PCA, when used in combination with several DP algorithms. Notably, this framework is also simple to implement, allowing direct integration into existing DP pipelines.
On the Growth of Mistakes in Differentially Private Online Learning: A Lower Bound Perspective
Feb 26, 2024In this paper, we provide lower bounds for Differentially Private (DP) Online Learning algorithms. Our result shows that, for a broad class of $(\varepsilon,\delta)$-DP online algorithms, for $T$ such that $\log T\leq O(1 / \delta)$, the expected number of mistakes incurred by the algorithm grows as $\Omega(\log \frac{T}{\delta})$. This matches the upper bound obtained by Golowich and Livni (2021) and is in contrast to non-private online learning where the number of mistakes is independent of $T$. To the best of our knowledge, our work is the first result towards settling lower bounds for DP-Online learning and partially addresses the open question in Sanyal and Ramponi (2022).
Corrective Machine Unlearning
Feb 21, 2024Machine Learning models increasingly face data integrity challenges due to the use of large-scale training datasets drawn from the internet. We study what model developers can do if they detect that some data was manipulated or incorrect. Such manipulated data can cause adverse effects like vulnerability to backdoored samples, systematic biases, and in general, reduced accuracy on certain input domains. Often, all manipulated training samples are not known, and only a small, representative subset of the affected data is flagged. We formalize "Corrective Machine Unlearning" as the problem of mitigating the impact of data affected by unknown manipulations on a trained model, possibly knowing only a subset of impacted samples. We demonstrate that the problem of corrective unlearning has significantly different requirements from traditional privacy-oriented unlearning. We find most existing unlearning methods, including the gold-standard retraining-from-scratch, require most of the manipulated data to be identified for effective corrective unlearning. However, one approach, SSD, achieves limited success in unlearning adverse effects with just a small portion of the manipulated samples, showing the tractability of this setting. We hope our work spurs research towards developing better methods for corrective unlearning and offers practitioners a new strategy to handle data integrity challenges arising from web-scale training.
Can semi-supervised learning use all the data effectively? A lower bound perspective
Nov 30, 2023Prior works have shown that semi-supervised learning algorithms can leverage unlabeled data to improve over the labeled sample complexity of supervised learning (SL) algorithms. However, existing theoretical analyses focus on regimes where the unlabeled data is sufficient to learn a good decision boundary using unsupervised learning (UL) alone. This begs the question: Can SSL algorithms simultaneously improve upon both UL and SL? To this end, we derive a tight lower bound for 2-Gaussian mixture models that explicitly depends on the labeled and the unlabeled dataset size as well as the signal-to-noise ratio of the mixture distribution. Surprisingly, our result implies that no SSL algorithm can improve upon the minimax-optimal statistical error rates of SL or UL algorithms for these distributions. Nevertheless, we show empirically on real-world data that SSL algorithms can still outperform UL and SL methods. Therefore, our work suggests that, while proving performance gains for SSL algorithms is possible, it requires careful tracking of constants.
How robust accuracy suffers from certified training with convex relaxations
Jun 12, 2023

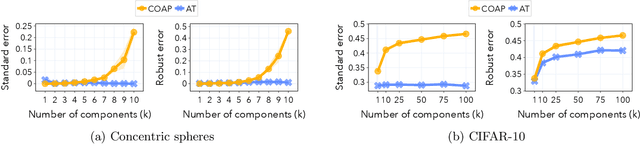
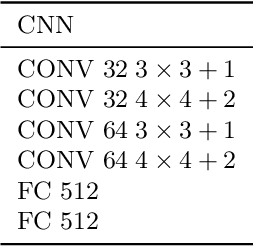
Adversarial attacks pose significant threats to deploying state-of-the-art classifiers in safety-critical applications. Two classes of methods have emerged to address this issue: empirical defences and certified defences. Although certified defences come with robustness guarantees, empirical defences such as adversarial training enjoy much higher popularity among practitioners. In this paper, we systematically compare the standard and robust error of these two robust training paradigms across multiple computer vision tasks. We show that in most tasks and for both $\mathscr{l}_\infty$-ball and $\mathscr{l}_2$-ball threat models, certified training with convex relaxations suffers from worse standard and robust error than adversarial training. We further explore how the error gap between certified and adversarial training depends on the threat model and the data distribution. In particular, besides the perturbation budget, we identify as important factors the shape of the perturbation set and the implicit margin of the data distribution. We support our arguments with extensive ablations on both synthetic and image datasets.
PILLAR: How to make semi-private learning more effective
Jun 06, 2023
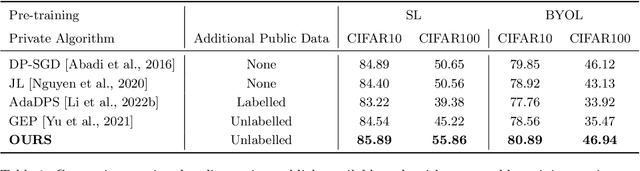
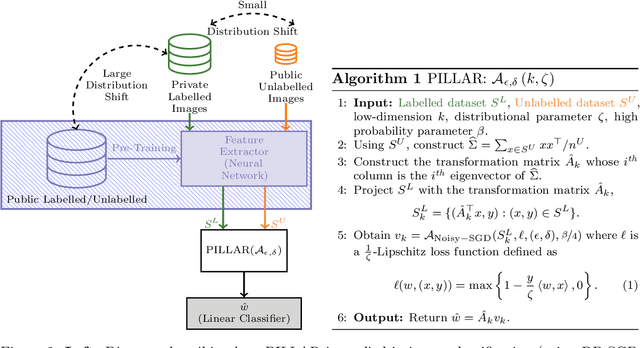

In Semi-Supervised Semi-Private (SP) learning, the learner has access to both public unlabelled and private labelled data. We propose a computationally efficient algorithm that, under mild assumptions on the data, provably achieves significantly lower private labelled sample complexity and can be efficiently run on real-world datasets. For this purpose, we leverage the features extracted by networks pre-trained on public (labelled or unlabelled) data, whose distribution can significantly differ from the one on which SP learning is performed. To validate its empirical effectiveness, we propose a wide variety of experiments under tight privacy constraints ($\epsilon = 0.1$) and with a focus on low-data regimes. In all of these settings, our algorithm exhibits significantly improved performance over available baselines that use similar amounts of public data.
Certifying Ensembles: A General Certification Theory with S-Lipschitzness
Apr 25, 2023
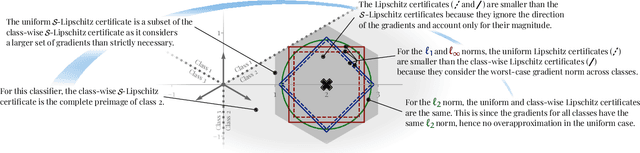
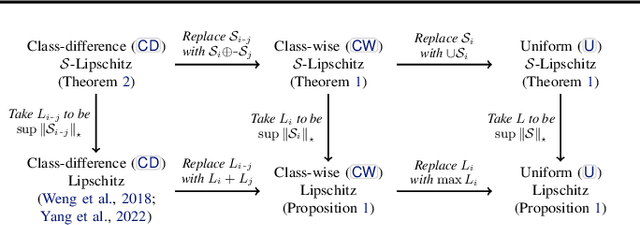
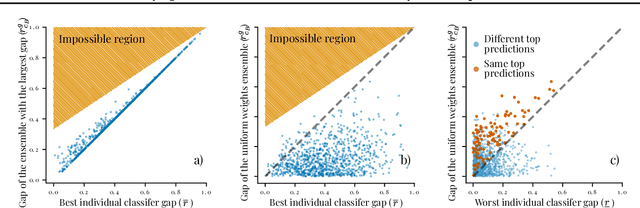
Improving and guaranteeing the robustness of deep learning models has been a topic of intense research. Ensembling, which combines several classifiers to provide a better model, has shown to be beneficial for generalisation, uncertainty estimation, calibration, and mitigating the effects of concept drift. However, the impact of ensembling on certified robustness is less well understood. In this work, we generalise Lipschitz continuity by introducing S-Lipschitz classifiers, which we use to analyse the theoretical robustness of ensembles. Our results are precise conditions when ensembles of robust classifiers are more robust than any constituent classifier, as well as conditions when they are less robust.
Do you pay for Privacy in Online learning?
Oct 10, 2022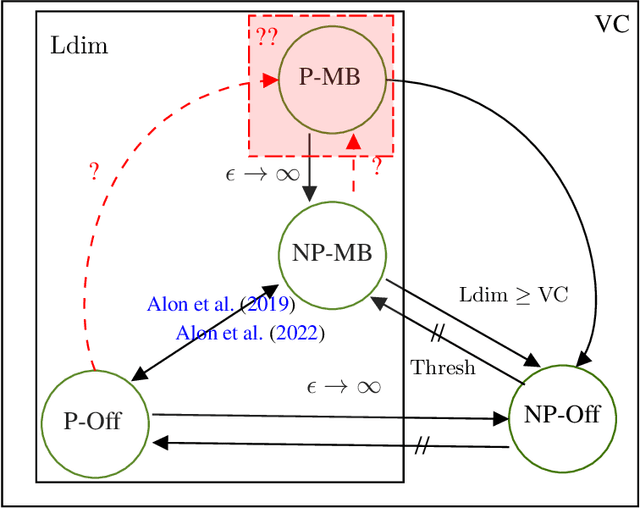
Online learning, in the mistake bound model, is one of the most fundamental concepts in learning theory. Differential privacy, instead, is the most widely used statistical concept of privacy in the machine learning community. It is thus clear that defining learning problems that are online differentially privately learnable is of great interest. In this paper, we pose the question on if the two problems are equivalent from a learning perspective, i.e., is privacy for free in the online learning framework?
A law of adversarial risk, interpolation, and label noise
Jul 08, 2022


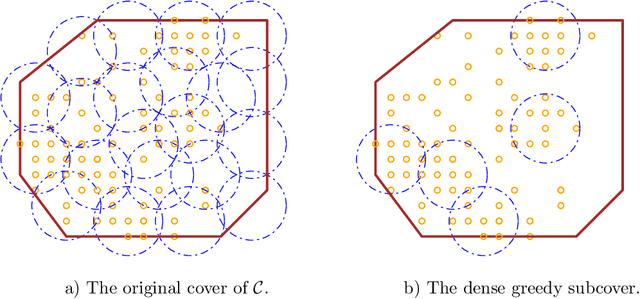
In supervised learning, it has been shown that label noise in the data can be interpolated without penalties on test accuracy under many circumstances. We show that interpolating label noise induces adversarial vulnerability, and prove the first theorem showing the dependence of label noise and adversarial risk in terms of the data distribution. Our results are almost sharp without accounting for the inductive bias of the learning algorithm. We also show that inductive bias makes the effect of label noise much stronger.
How robust are pre-trained models to distribution shift?
Jun 17, 2022

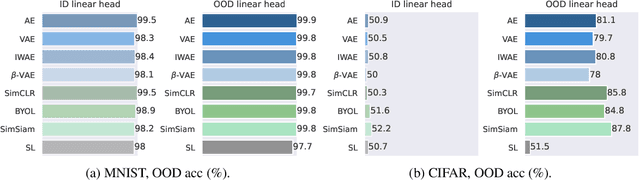

The vulnerability of machine learning models to spurious correlations has mostly been discussed in the context of supervised learning (SL). However, there is a lack of insight on how spurious correlations affect the performance of popular self-supervised learning (SSL) and auto-encoder based models (AE). In this work, we shed light on this by evaluating the performance of these models on both real world and synthetic distribution shift datasets. Following observations that the linear head itself can be susceptible to spurious correlations, we develop a novel evaluation scheme with the linear head trained on out-of-distribution (OOD) data, to isolate the performance of the pre-trained models from a potential bias of the linear head used for evaluation. With this new methodology, we show that SSL models are consistently more robust to distribution shifts and thus better at OOD generalisation than AE and SL models.