 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndong Deng
Sports-QA: A Large-Scale Video Question Answering Benchmark for Complex and Professional Sports
Jan 07, 2024
Reasoning over sports videos for question answering is an important task with numerous applications, such as player training and information retrieval. However, this task has not been explored due to the lack of relevant datasets and the challenging nature it presents. Most datasets for video question answering (VideoQA) focus mainly on general and coarse-grained understanding of daily-life videos, which is not applicable to sports scenarios requiring professional action understanding and fine-grained motion analysis. In this paper, we introduce the first dataset, named Sports-QA, specifically designed for the sports VideoQA task. The Sports-QA dataset includes various types of questions, such as descriptions, chronologies, causalities, and counterfactual conditions, covering multiple sports. Furthermore, to address the characteristics of the sports VideoQA task, we propose a new Auto-Focus Transformer (AFT) capable of automatically focusing on particular scales of temporal information for question answering. We conduct extensive experiments on Sports-QA, including baseline studies and the evaluation of different methods. The results demonstrate that our AFT achieves state-of-the-art performance.
Robust Cross-Modal Knowledge Distillation for Unconstrained Videos
Apr 27, 2023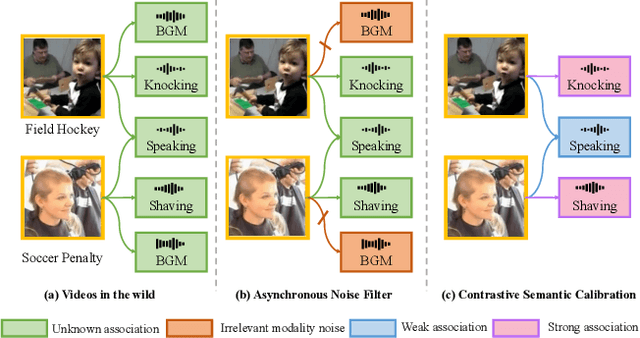
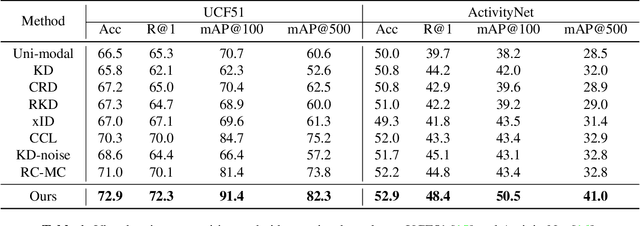
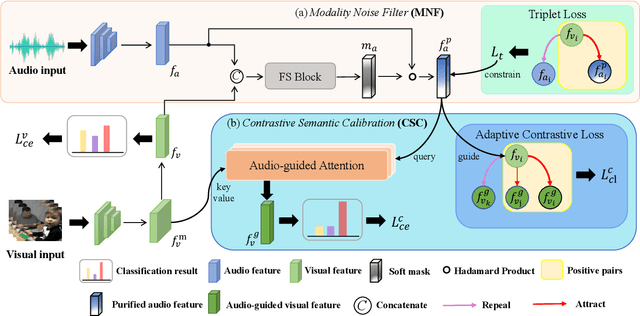
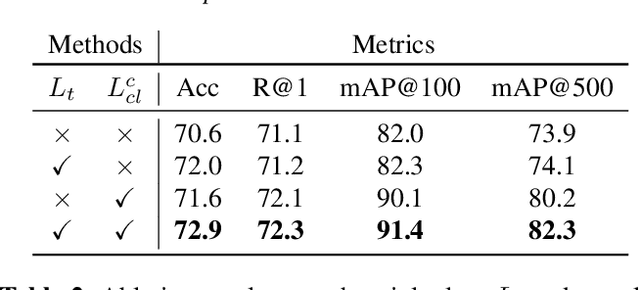
Cross-modal distillation has been widely used to transfer knowledge across different modalities, enriching the representation of the target unimodal one. Recent studies highly relate the temporal synchronization between vision and sound to the semantic consistency for cross-modal distillation. However, such semantic consistency from the synchronization is hard to guarantee in unconstrained videos, due to the irrelevant modality noise and differentiated semantic correlation. To this end, we first propose a \textit{Modality Noise Filter} (MNF) module to erase the irrelevant noise in teacher modality with cross-modal context. After this purification, we then design a \textit{Contrastive Semantic Calibration} (CSC) module to adaptively distill useful knowledge for target modality, by referring to the differentiated sample-wise semantic correlation in a contrastive fashion. Extensive experiments show that our method could bring a performance boost compared with other distillation methods in both visual action recognition and video retrieval task. We also extend to the audio tagging task to prove the generalization of our method. The source code is available at \href{https://github.com/GeWu-Lab/cross-modal-distillation}{https://github.com/GeWu-Lab/cross-modal-distillation}.
A Large-scale Study of Spatiotemporal Representation Learning with a New Benchmark on Action Recognition
Mar 23, 2023
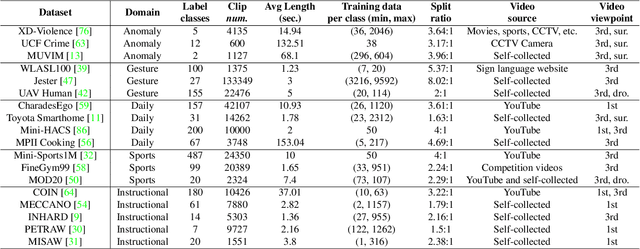


The goal of building a benchmark (suite of datasets) is to provide a unified protocol for fair evaluation and thus facilitate the evolution of a specific area. Nonetheless, we point out that existing protocols of action recognition could yield partial evaluations due to several limitations. To comprehensively probe the effectiveness of spatiotemporal representation learning, we introduce BEAR, a new BEnchmark on video Action Recognition. BEAR is a collection of 18 video datasets grouped into 5 categories (anomaly, gesture, daily, sports, and instructional), which covers a diverse set of real-world applications. With BEAR, we thoroughly evaluate 6 common spatiotemporal models pre-trained by both supervised and self-supervised learning. We also report transfer performance via standard finetuning, few-shot finetuning, and unsupervised domain adaptation. Our observation suggests that current state-of-the-art cannot solidly guarantee high performance on datasets close to real-world applications, and we hope BEAR can serve as a fair and challenging evaluation benchmark to gain insights on building next-generation spatiotemporal learners. Our dataset, code, and models are released at: https://github.com/AndongDeng/BEAR
Problem Behaviors Recognition in Videos using Language-Assisted Deep Learning Model for Children with Autism
Nov 17, 2022

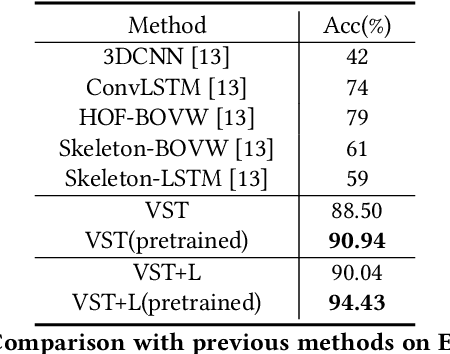

Correctly recognizing the behaviors of children with Autism Spectrum Disorder (ASD) is of vital importance for the diagnosis of Autism and timely early intervention. However, the observation and recording during the treatment from the parents of autistic children may not be accurate and objective. In such cases, automatic recognition systems based on computer vision and machine learning (in particular deep learning) technology can alleviate this issue to a large extent. Existing human action recognition models can now achieve persuasive performance on challenging activity datasets, e.g. daily activity, and sports activity. However, problem behaviors in children with ASD are very different from these general activities, and recognizing these problem behaviors via computer vision is less studied. In this paper, we first evaluate a strong baseline for action recognition, i.e. Video Swin Transformer, on two autism behaviors datasets (SSBD and ESBD) and show that it can achieve high accuracy and outperform the previous methods by a large margin, demonstrating the feasibility of vision-based problem behaviors recognition. Moreover, we propose language-assisted training to further enhance the action recognition performance. Specifically, we develop a two-branch multimodal deep learning framework by incorporating the "freely available" language description for each type of problem behavior. Experimental results demonstrate that incorporating additional language supervision can bring an obvious performance boost for the autism problem behaviors recognition task as compared to using the video information only (i.e. 3.49% improvement on ESBD and 1.46% on SSBD).
Balanced Multimodal Learning via On-the-fly Gradient Modulation
Mar 29, 2022



Multimodal learning helps to comprehensively understand the world, by integrating different senses. Accordingly, multiple input modalities are expected to boost model performance, but we actually find that they are not fully exploited even when the multimodal model outperforms its uni-modal counterpart. Specifically, in this paper we point out that existing multimodal discriminative models, in which uniform objective is designed for all modalities, could remain under-optimized uni-modal representations, caused by another dominated modality in some scenarios, e.g., sound in blowing wind event, vision in drawing picture event, etc. To alleviate this optimization imbalance, we propose on-the-fly gradient modulation to adaptively control the optimization of each modality, via monitoring the discrepancy of their contribution towards the learning objective. Further, an extra Gaussian noise that changes dynamically is introduced to avoid possible generalization drop caused by gradient modulation. As a result, we achieve considerable improvement over common fusion methods on different multimodal tasks, and this simple strategy can also boost existing multimodal methods, which illustrates its efficacy and versatility. The source code is available at \url{https://github.com/GeWu-Lab/OGM-GE_CVPR2022}.
Inadequately Pre-trained Models are Better Feature Extractors
Mar 09, 2022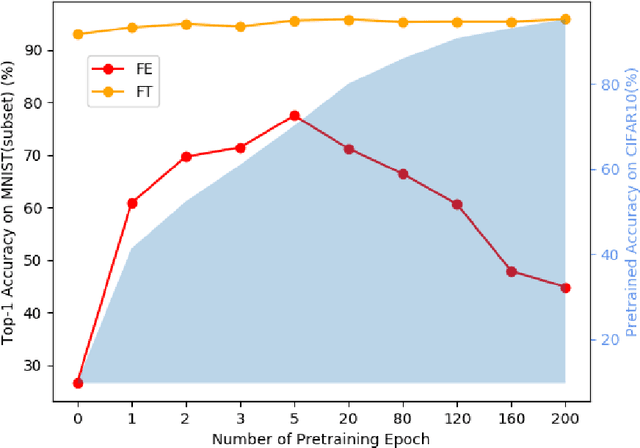
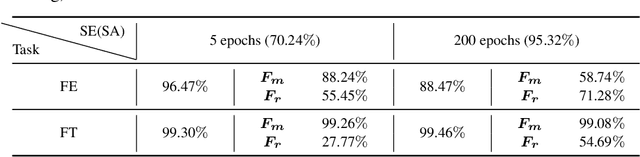
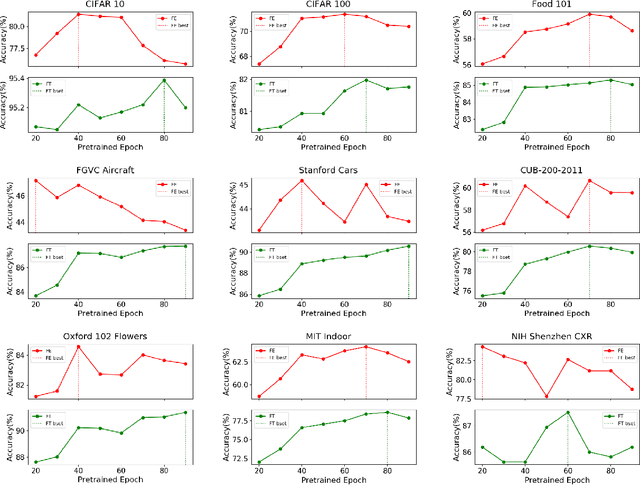
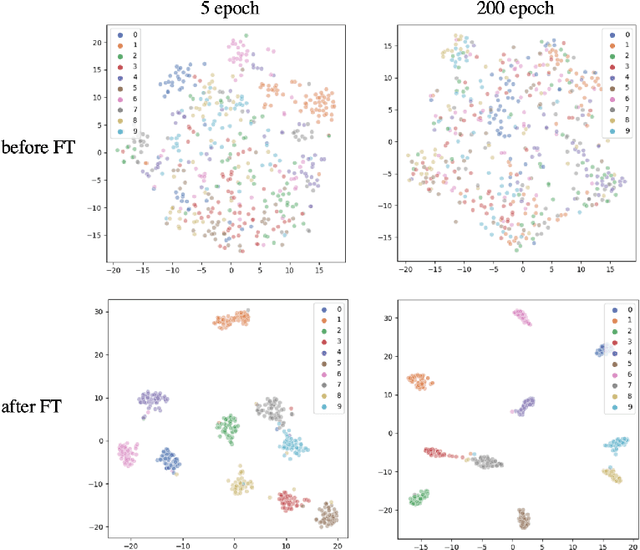
Pre-training has been a popular learning paradigm in deep learning era, especially in annotation-insufficient scenario. Better ImageNet pre-trained models have been demonstrated, from the perspective of architecture, by previous research to have better transferability to downstream tasks. However, in this paper, we found that during the same pre-training process, models at middle epochs, which is inadequately pre-trained, can outperform fully trained models when used as feature extractors (FE), while the fine-tuning (FT) performance still grows with the source performance. This reveals that there is not a solid positive correlation between top-1 accuracy on ImageNet and the transferring result on target data. Based on the contradictory phenomenon between FE and FT that better feature extractor fails to be fine-tuned better accordingly, we conduct comprehensive analyses on features before softmax layer to provide insightful explanations. Our discoveries suggest that, during pre-training, models tend to first learn spectral components corresponding to large singular values and the residual components contribute more when fine-tuning.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021



Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.