 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRAML: Reinforced Retrieval Augmented Machine Learning
Jul 27, 2023The emergence of large language models (LLMs) has revolutionized machine learning and related fields, showcasing remarkable abilities in comprehending, generating, and manipulating human language. However, their conventional usage through API-based text prompt submissions imposes certain limitations in terms of context constraints and external source availability. To address these challenges, we propose a novel framework called Reinforced Retrieval Augmented Machine Learning (RRAML). RRAML integrates the reasoning capabilities of LLMs with supporting information retrieved by a purpose-built retriever from a vast user-provided database. By leveraging recent advancements in reinforcement learning, our method effectively addresses several critical challenges. Firstly, it circumvents the need for accessing LLM gradients. Secondly, our method alleviates the burden of retraining LLMs for specific tasks, as it is often impractical or impossible due to restricted access to the model and the computational intensity involved. Additionally we seamlessly link the retriever's task with the reasoner, mitigating hallucinations and reducing irrelevant, and potentially damaging retrieved documents. We believe that the research agenda outlined in this paper has the potential to profoundly impact the field of AI, democratizing access to and utilization of LLMs for a wide range of entities.
Fauno: The Italian Large Language Model that will leave you senza parole!
Jun 26, 2023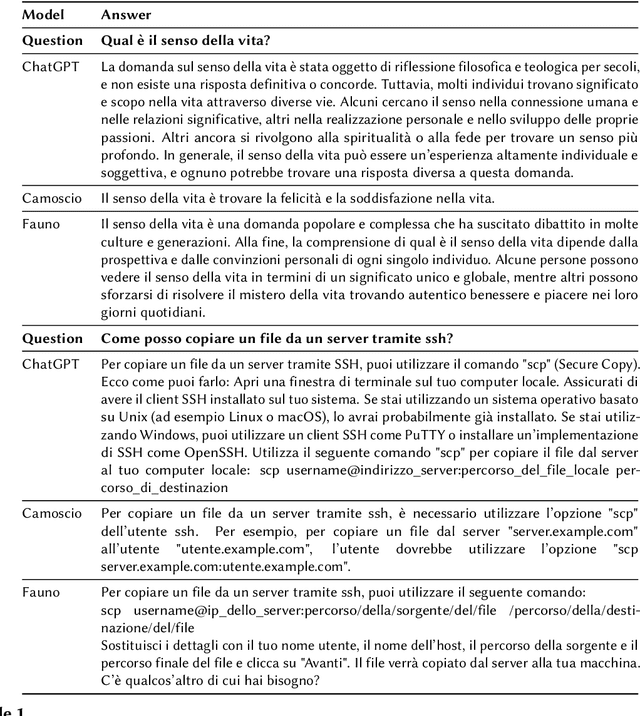
This paper presents Fauno, the first and largest open-source Italian conversational Large Language Model (LLM). Our goal with Fauno is to democratize the study of LLMs in Italian, demonstrating that obtaining a fine-tuned conversational bot with a single GPU is possible. In addition, we release a collection of datasets for conversational AI in Italian. The datasets on which we fine-tuned Fauno include various topics such as general question answering, computer science, and medical questions. We release our code and datasets on \url{https://github.com/RSTLess-research/Fauno-Italian-LLM}
Renormalized Graph Neural Networks
Jun 01, 2023

Graph Neural Networks (GNNs) have become essential for studying complex data, particularly when represented as graphs. Their value is underpinned by their ability to reflect the intricacies of numerous areas, ranging from social to biological networks. GNNs can grapple with non-linear behaviors, emerging patterns, and complex connections; these are also typical characteristics of complex systems. The renormalization group (RG) theory has emerged as the language for studying complex systems. It is recognized as the preferred lens through which to study complex systems, offering a framework that can untangle their intricate dynamics. Despite the clear benefits of integrating RG theory with GNNs, no existing methods have ventured into this promising territory. This paper proposes a new approach that applies RG theory to devise a novel graph rewiring to improve GNNs' performance on graph-related tasks. We support our proposal with extensive experiments on standard benchmarks and baselines. The results demonstrate the effectiveness of our method and its potential to remedy the current limitations of GNNs. Finally, this paper marks the beginning of a new research direction. This path combines the theoretical foundations of RG, the magnifying glass of complex systems, with the structural capabilities of GNNs. By doing so, we aim to enhance the potential of GNNs in modeling and unraveling the complexities inherent in diverse systems.
Integrating Item Relevance in Training Loss for Sequential Recommender Systems
May 25, 2023



Sequential Recommender Systems (SRSs) are a popular type of recommender system that learns from a user's history to predict the next item they are likely to interact with. However, user interactions can be affected by noise stemming from account sharing, inconsistent preferences, or accidental clicks. To address this issue, we (i) propose a new evaluation protocol that takes multiple future items into account and (ii) introduce a novel relevance-aware loss function to train a SRS with multiple future items to make it more robust to noise. Our relevance-aware models obtain an improvement of ~1.2% of NDCG@10 and 0.88% in the traditional evaluation protocol, while in the new evaluation protocol, the improvement is ~1.63% of NDCG@10 and ~1.5% of HR w.r.t the best performing models.
Study on Transfer Learning Capabilities for Pneumonia Classification in Chest-X-Rays Image
Oct 06, 2021



Over the last year, the severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2) and its variants have highlighted the importance of screening tools with high diagnostic accuracy for new illnesses such as COVID-19. To that regard, deep learning approaches have proven as effective solutions for pneumonia classification, especially when considering chest-x-rays images. However, this lung infection can also be caused by other viral, bacterial or fungi pathogens. Consequently, efforts are being poured toward distinguishing the infection source to help clinicians to diagnose the correct disease origin. Following this tendency, this study further explores the effectiveness of established neural network architectures on the pneumonia classification task through the transfer learning paradigm. To present a comprehensive comparison, 12 well-known ImageNet pre-trained models were fine-tuned and used to discriminate among chest-x-rays of healthy people, and those showing pneumonia symptoms derived from either a viral (i.e., generic or SARS-CoV-2) or bacterial source. Furthermore, since a common public collection distinguishing between such categories is currently not available, two distinct datasets of chest-x-rays images, describing the aforementioned sources, were combined and employed to evaluate the various architectures. The experiments were performed using a total of 6330 images split between train, validation and test sets. For all models, common classification metrics were computed (e.g., precision, f1-score) and most architectures obtained significant performances, reaching, among the others, up to 84.46% average f1-score when discriminating the 4 identified classes. Moreover, confusion matrices and activation maps computed via the Grad-CAM algorithm were also reported to present an informed discussion on the networks classifications.