 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiovanni Trappolini
TEXT2TASTE: A Versatile Egocentric Vision System for Intelligent Reading Assistance Using Large Language Model
Apr 14, 2024
The ability to read, understand and find important information from written text is a critical skill in our daily lives for our independence, comfort and safety. However, a significant part of our society is affected by partial vision impairment, which leads to discomfort and dependency in daily activities. To address the limitations of this part of society, we propose an intelligent reading assistant based on smart glasses with embedded RGB cameras and a Large Language Model (LLM), whose functionality goes beyond corrective lenses. The video recorded from the egocentric perspective of a person wearing the glasses is processed to localise text information using object detection and optical character recognition methods. The LLM processes the data and allows the user to interact with the text and responds to a given query, thus extending the functionality of corrective lenses with the ability to find and summarize knowledge from the text. To evaluate our method, we create a chat-based application that allows the user to interact with the system. The evaluation is conducted in a real-world setting, such as reading menus in a restaurant, and involves four participants. The results show robust accuracy in text retrieval. The system not only provides accurate meal suggestions but also achieves high user satisfaction, highlighting the potential of smart glasses and LLMs in assisting people with special needs.
The Power of Noise: Redefining Retrieval for RAG Systems
Jan 29, 2024Retrieval-Augmented Generation (RAG) systems represent a significant advancement over traditional Large Language Models (LLMs). RAG systems enhance their generation ability by incorporating external data retrieved through an Information Retrieval (IR) phase, overcoming the limitations of standard LLMs, which are restricted to their pre-trained knowledge and limited context window. Most research in this area has predominantly concentrated on the generative aspect of LLMs within RAG systems. Our study fills this gap by thoroughly and critically analyzing the influence of IR components on RAG systems. This paper analyzes which characteristics a retriever should possess for an effective RAG's prompt formulation, focusing on the type of documents that should be retrieved. We evaluate various elements, such as the relevance of the documents to the prompt, their position, and the number included in the context. Our findings reveal, among other insights, that including irrelevant documents can unexpectedly enhance performance by more than 30% in accuracy, contradicting our initial assumption of diminished quality. These results underscore the need for developing specialized strategies to integrate retrieval with language generation models, thereby laying the groundwork for future research in this field.
Prompt-to-OS (P2OS): Revolutionizing Operating Systems and Human-Computer Interaction with Integrated AI Generative Models
Oct 07, 2023In this paper, we present a groundbreaking paradigm for human-computer interaction that revolutionizes the traditional notion of an operating system. Within this innovative framework, user requests issued to the machine are handled by an interconnected ecosystem of generative AI models that seamlessly integrate with or even replace traditional software applications. At the core of this paradigm shift are large generative models, such as language and diffusion models, which serve as the central interface between users and computers. This pioneering approach leverages the abilities of advanced language models, empowering users to engage in natural language conversations with their computing devices. Users can articulate their intentions, tasks, and inquiries directly to the system, eliminating the need for explicit commands or complex navigation. The language model comprehends and interprets the user's prompts, generating and displaying contextual and meaningful responses that facilitate seamless and intuitive interactions. This paradigm shift not only streamlines user interactions but also opens up new possibilities for personalized experiences. Generative models can adapt to individual preferences, learning from user input and continuously improving their understanding and response generation. Furthermore, it enables enhanced accessibility, as users can interact with the system using speech or text, accommodating diverse communication preferences. However, this visionary concept raises significant challenges, including privacy, security, trustability, and the ethical use of generative models. Robust safeguards must be in place to protect user data and prevent potential misuse or manipulation of the language model. While the full realization of this paradigm is still far from being achieved, this paper serves as a starting point for envisioning this transformative potential.
RRAML: Reinforced Retrieval Augmented Machine Learning
Jul 27, 2023The emergence of large language models (LLMs) has revolutionized machine learning and related fields, showcasing remarkable abilities in comprehending, generating, and manipulating human language. However, their conventional usage through API-based text prompt submissions imposes certain limitations in terms of context constraints and external source availability. To address these challenges, we propose a novel framework called Reinforced Retrieval Augmented Machine Learning (RRAML). RRAML integrates the reasoning capabilities of LLMs with supporting information retrieved by a purpose-built retriever from a vast user-provided database. By leveraging recent advancements in reinforcement learning, our method effectively addresses several critical challenges. Firstly, it circumvents the need for accessing LLM gradients. Secondly, our method alleviates the burden of retraining LLMs for specific tasks, as it is often impractical or impossible due to restricted access to the model and the computational intensity involved. Additionally we seamlessly link the retriever's task with the reasoner, mitigating hallucinations and reducing irrelevant, and potentially damaging retrieved documents. We believe that the research agenda outlined in this paper has the potential to profoundly impact the field of AI, democratizing access to and utilization of LLMs for a wide range of entities.
Fauno: The Italian Large Language Model that will leave you senza parole!
Jun 26, 2023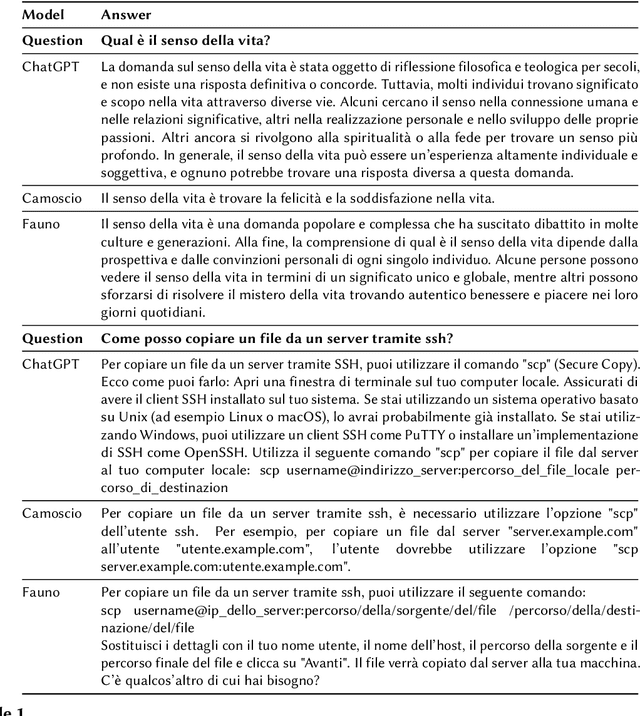
This paper presents Fauno, the first and largest open-source Italian conversational Large Language Model (LLM). Our goal with Fauno is to democratize the study of LLMs in Italian, demonstrating that obtaining a fine-tuned conversational bot with a single GPU is possible. In addition, we release a collection of datasets for conversational AI in Italian. The datasets on which we fine-tuned Fauno include various topics such as general question answering, computer science, and medical questions. We release our code and datasets on \url{https://github.com/RSTLess-research/Fauno-Italian-LLM}
Renormalized Graph Neural Networks
Jun 01, 2023

Graph Neural Networks (GNNs) have become essential for studying complex data, particularly when represented as graphs. Their value is underpinned by their ability to reflect the intricacies of numerous areas, ranging from social to biological networks. GNNs can grapple with non-linear behaviors, emerging patterns, and complex connections; these are also typical characteristics of complex systems. The renormalization group (RG) theory has emerged as the language for studying complex systems. It is recognized as the preferred lens through which to study complex systems, offering a framework that can untangle their intricate dynamics. Despite the clear benefits of integrating RG theory with GNNs, no existing methods have ventured into this promising territory. This paper proposes a new approach that applies RG theory to devise a novel graph rewiring to improve GNNs' performance on graph-related tasks. We support our proposal with extensive experiments on standard benchmarks and baselines. The results demonstrate the effectiveness of our method and its potential to remedy the current limitations of GNNs. Finally, this paper marks the beginning of a new research direction. This path combines the theoretical foundations of RG, the magnifying glass of complex systems, with the structural capabilities of GNNs. By doing so, we aim to enhance the potential of GNNs in modeling and unraveling the complexities inherent in diverse systems.
Multimodal Neural Databases
May 02, 2023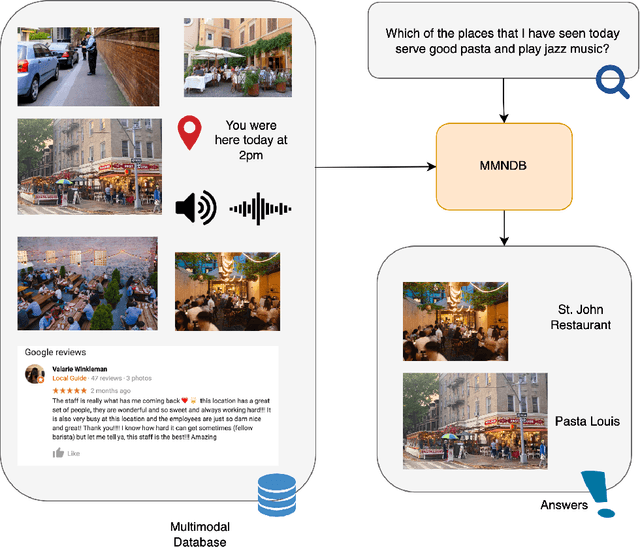
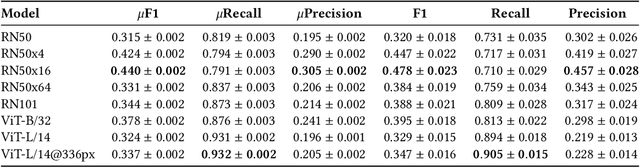

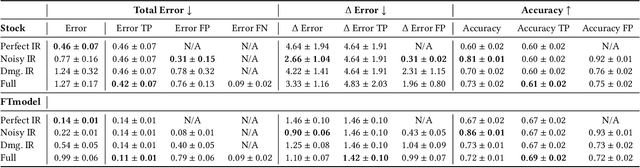
The rise in loosely-structured data available through text, images, and other modalities has called for new ways of querying them. Multimedia Information Retrieval has filled this gap and has witnessed exciting progress in recent years. Tasks such as search and retrieval of extensive multimedia archives have undergone massive performance improvements, driven to a large extent by recent developments in multimodal deep learning. However, methods in this field remain limited in the kinds of queries they support and, in particular, their inability to answer database-like queries. For this reason, inspired by recent work on neural databases, we propose a new framework, which we name Multimodal Neural Databases (MMNDBs). MMNDBs can answer complex database-like queries that involve reasoning over different input modalities, such as text and images, at scale. In this paper, we present the first architecture able to fulfill this set of requirements and test it with several baselines, showing the limitations of currently available models. The results show the potential of these new techniques to process unstructured data coming from different modalities, paving the way for future research in the area. Code to replicate the experiments will be released at https://github.com/GiovanniTRA/MultimodalNeuralDatabases
Sparse Vicious Attacks on Graph Neural Networks
Sep 20, 2022



Graph Neural Networks (GNNs) have proven to be successful in several predictive modeling tasks for graph-structured data. Amongst those tasks, link prediction is one of the fundamental problems for many real-world applications, such as recommender systems. However, GNNs are not immune to adversarial attacks, i.e., carefully crafted malicious examples that are designed to fool the predictive model. In this work, we focus on a specific, white-box attack to GNN-based link prediction models, where a malicious node aims to appear in the list of recommended nodes for a given target victim. To achieve this goal, the attacker node may also count on the cooperation of other existing peers that it directly controls, namely on the ability to inject a number of ``vicious'' nodes in the network. Specifically, all these malicious nodes can add new edges or remove existing ones, thereby perturbing the original graph. Thus, we propose SAVAGE, a novel framework and a method to mount this type of link prediction attacks. SAVAGE formulates the adversary's goal as an optimization task, striking the balance between the effectiveness of the attack and the sparsity of malicious resources required. Extensive experiments conducted on real-world and synthetic datasets demonstrate that adversarial attacks implemented through SAVAGE indeed achieve high attack success rate yet using a small amount of vicious nodes. Finally, despite those attacks require full knowledge of the target model, we show that they are successfully transferable to other black-box methods for link prediction.
Shape registration in the time of transformers
Jun 28, 2021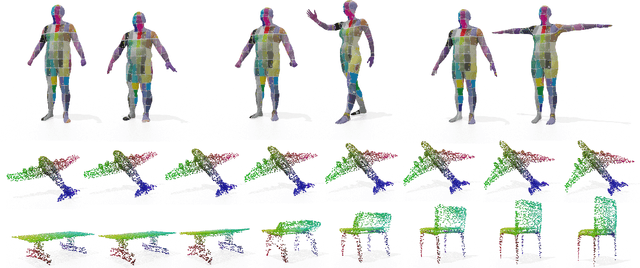

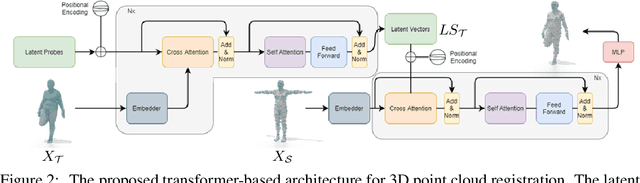
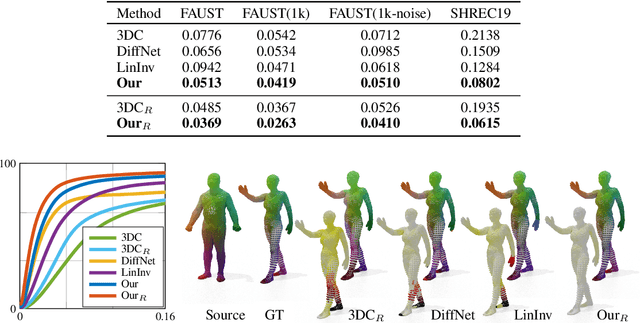
In this paper, we propose a transformer-based procedure for the efficient registration of non-rigid 3D point clouds. The proposed approach is data-driven and adopts for the first time the transformer architecture in the registration task. Our method is general and applies to different settings. Given a fixed template with some desired properties (e.g. skinning weights or other animation cues), we can register raw acquired data to it, thereby transferring all the template properties to the input geometry. Alternatively, given a pair of shapes, our method can register the first onto the second (or vice-versa), obtaining a high-quality dense correspondence between the two. In both contexts, the quality of our results enables us to target real applications such as texture transfer and shape interpolation. Furthermore, we also show that including an estimation of the underlying density of the surface eases the learning process. By exploiting the potential of this architecture, we can train our model requiring only a sparse set of ground truth correspondences ($10\sim20\%$ of the total points). The proposed model and the analysis that we perform pave the way for future exploration of transformer-based architectures for registration and matching applications. Qualitative and quantitative evaluations demonstrate that our pipeline outperforms state-of-the-art methods for deformable and unordered 3D data registration on different datasets and scenarios.
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021



The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.