 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrew Rouditchenko
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023
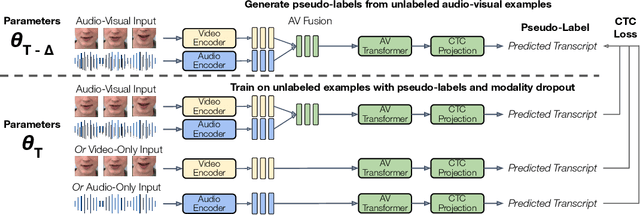
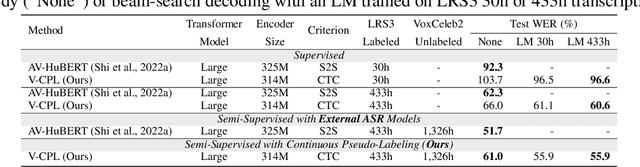
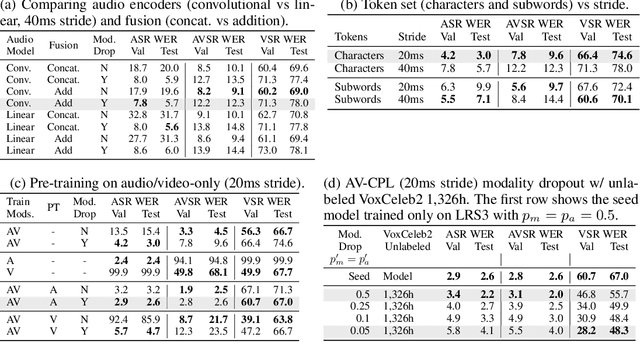
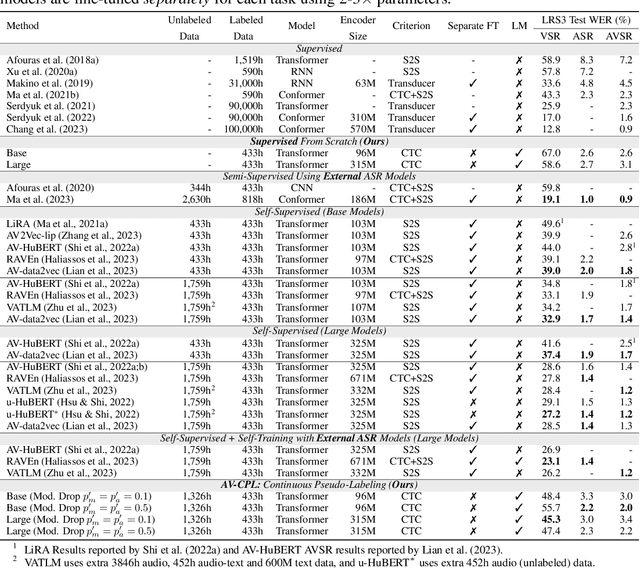
Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages
May 21, 2023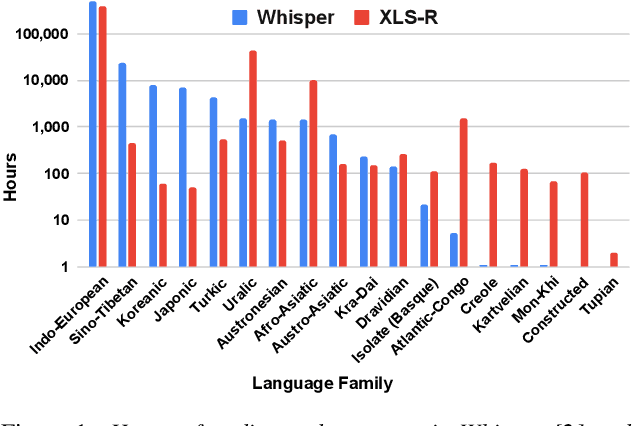
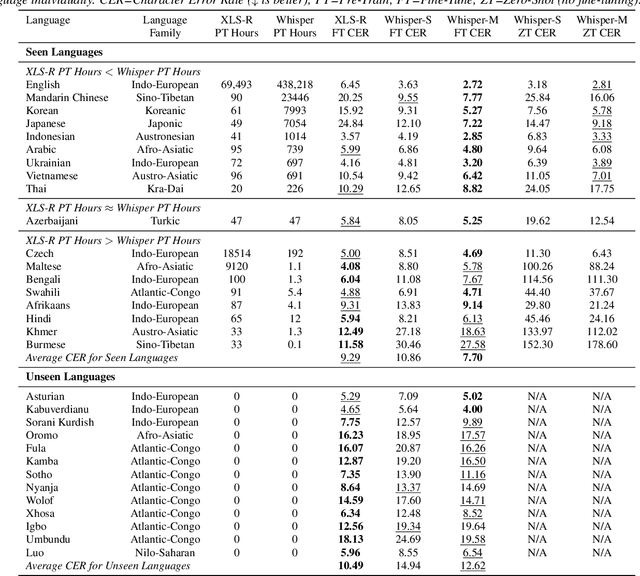
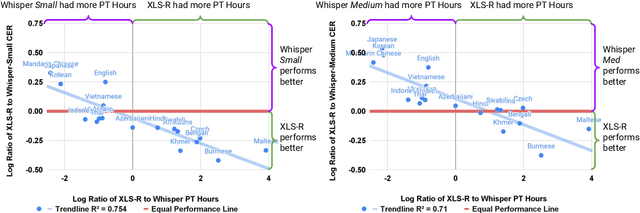
Recent models such as XLS-R and Whisper have made multilingual speech technologies more accessible by pre-training on audio from around 100 spoken languages each. However, there are thousands of spoken languages worldwide, and adapting to new languages is an important problem. In this work, we aim to understand which model adapts better to languages unseen during pre-training. We fine-tune both models on 13 unseen languages and 18 seen languages. Our results show that the number of hours seen per language and language family during pre-training is predictive of how the models compare, despite the significant differences in the pre-training methods.
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023
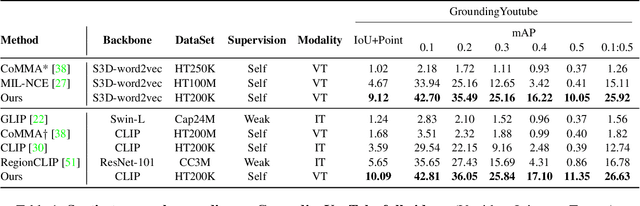
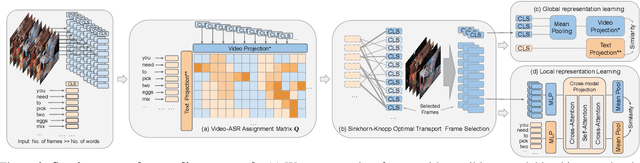
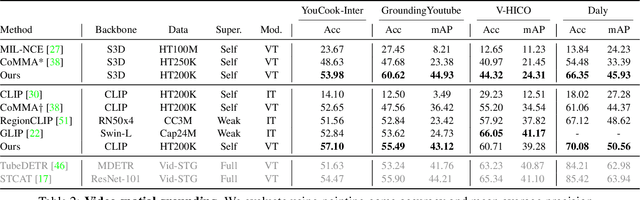
Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022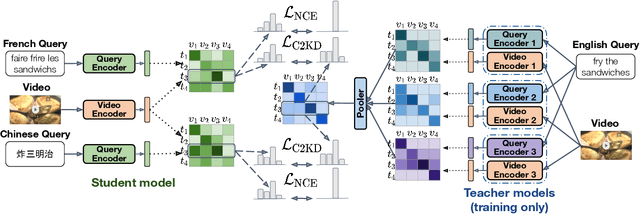
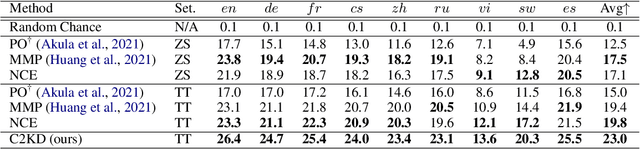

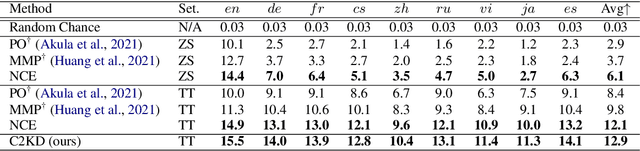
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
UAVM: A Unified Model for Audio-Visual Learning
Jul 29, 2022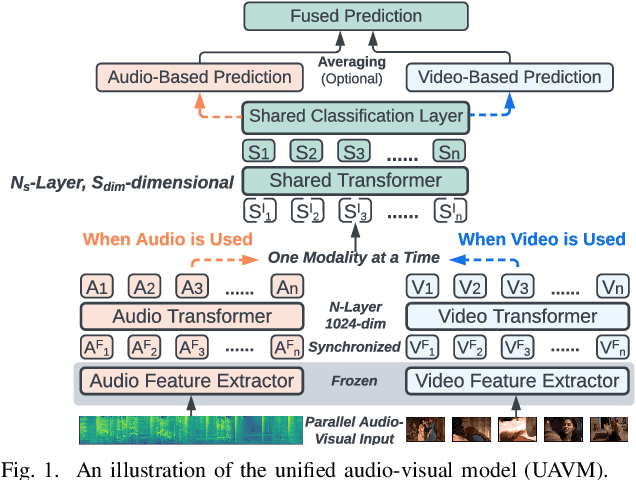
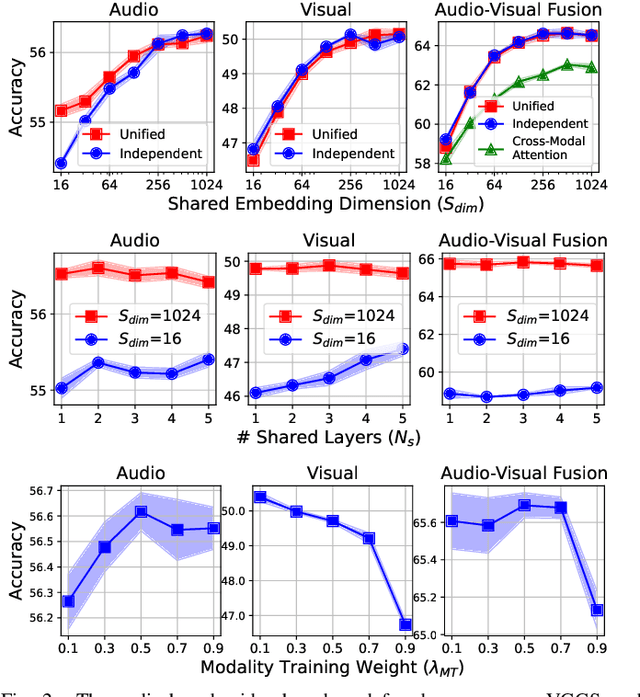
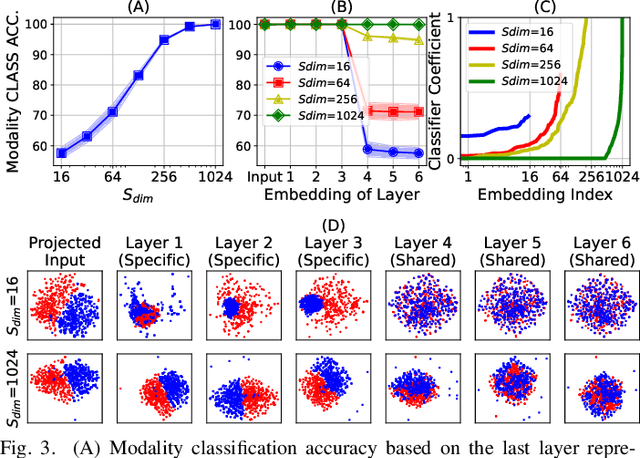
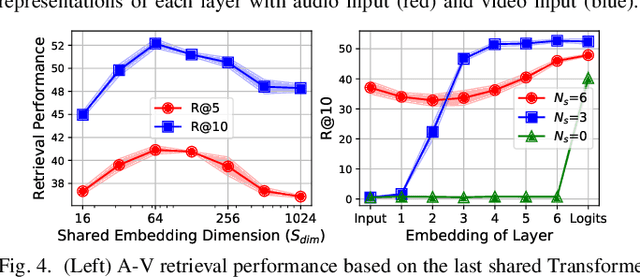
Conventional audio-visual models have independent audio and video branches. We design a unified model for audio and video processing called Unified Audio-Visual Model (UAVM). In this paper, we describe UAVM, report its new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound, and describe the intriguing properties of the model.
CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
Mar 13, 2022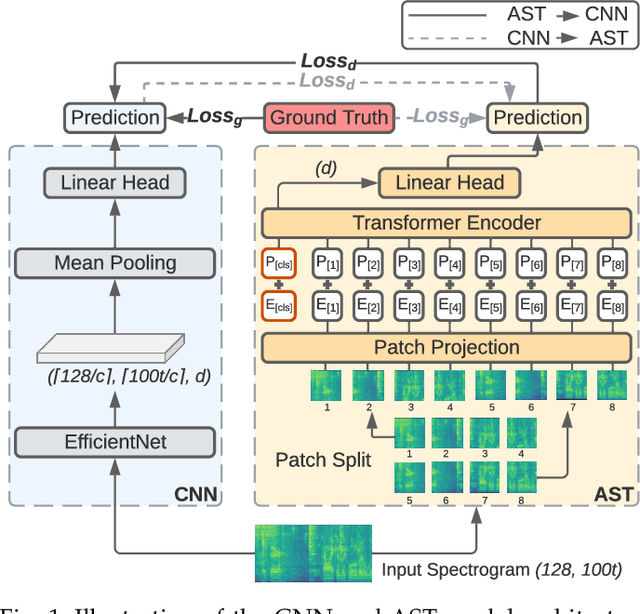
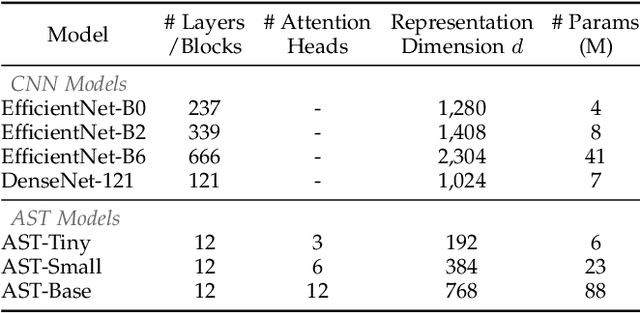
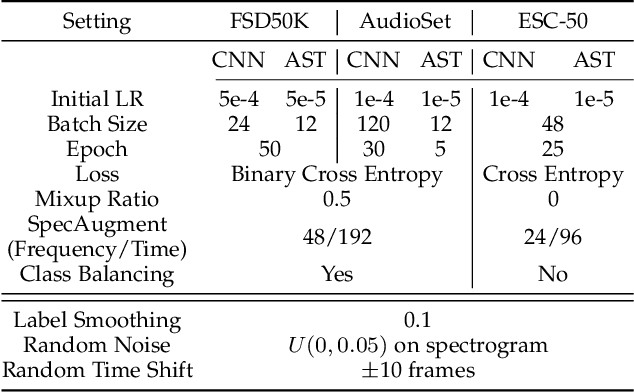
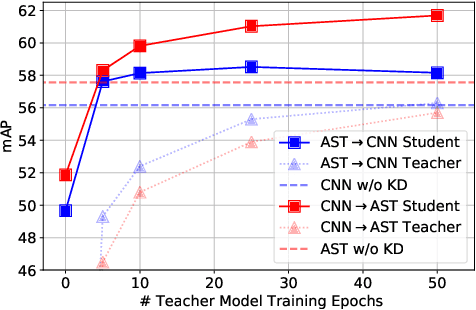
Audio classification is an active research area with a wide range of applications. Over the past decade, convolutional neural networks (CNNs) have been the de-facto standard building block for end-to-end audio classification models. Recently, neural networks based solely on self-attention mechanisms such as the Audio Spectrogram Transformer (AST) have been shown to outperform CNNs. In this paper, we find an intriguing interaction between the two very different models - CNN and AST models are good teachers for each other. When we use either of them as the teacher and train the other model as the student via knowledge distillation (KD), the performance of the student model noticeably improves, and in many cases, is better than the teacher model. In our experiments with this CNN/Transformer Cross-Model Knowledge Distillation (CMKD) method we achieve new state-of-the-art performance on FSD50K, AudioSet, and ESC-50.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021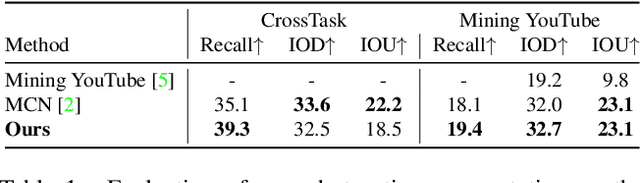

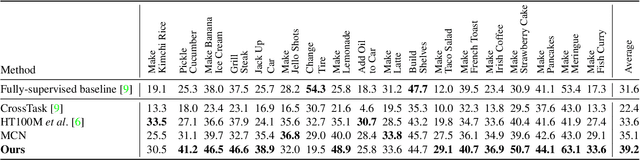
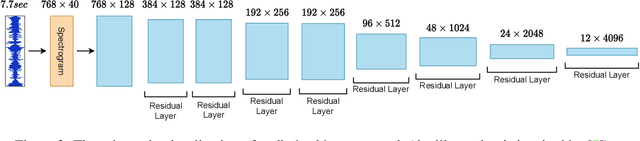
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
Routing with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021
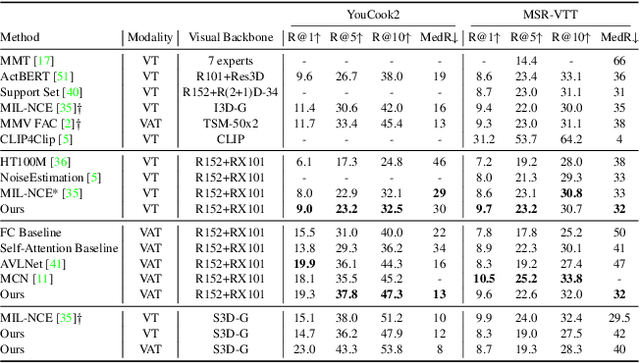
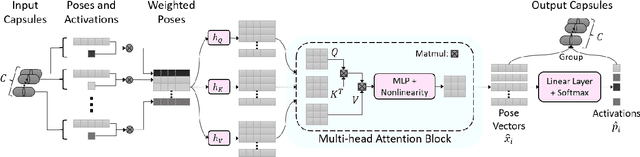
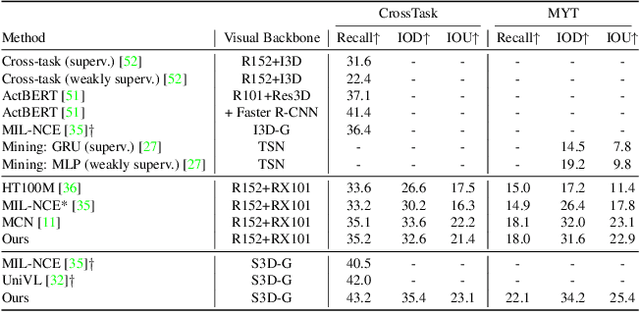
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021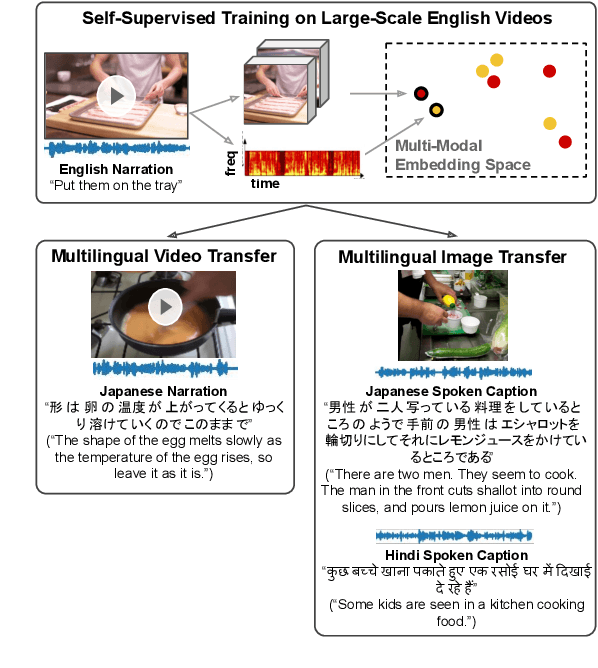
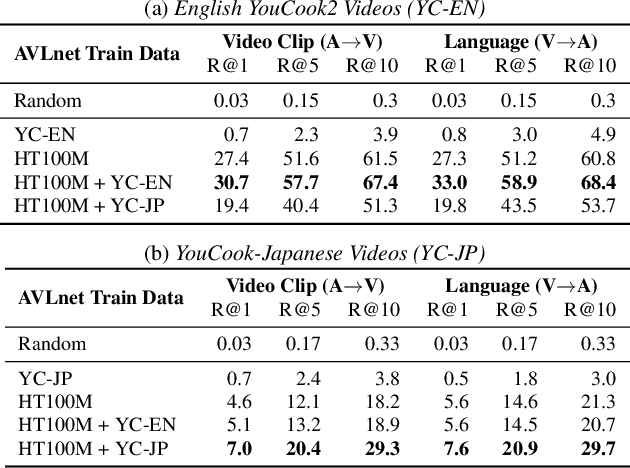

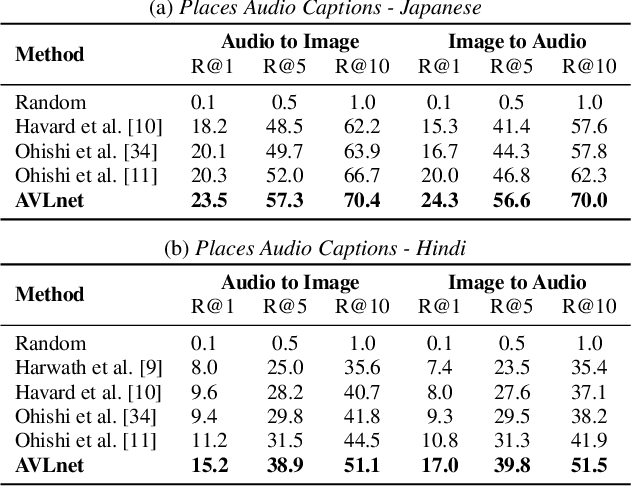
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Oct 14, 2021
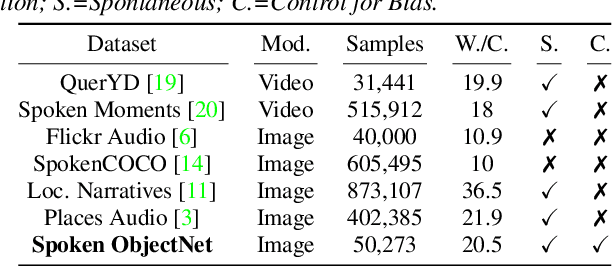


Visually-grounded spoken language datasets can enable models to learn cross-modal correspondences with very weak supervision. However, modern audio-visual datasets contain biases that undermine the real-world performance of models trained on that data. We introduce Spoken ObjectNet, which is designed to remove some of these biases and provide a way to better evaluate how effectively models will perform in real-world scenarios. This dataset expands upon ObjectNet, which is a bias-controlled image dataset that features similar image classes to those present in ImageNet. We detail our data collection pipeline, which features several methods to improve caption quality, including automated language model checks. Lastly, we show baseline results on image retrieval and audio retrieval tasks. These results show that models trained on other datasets and then evaluated on Spoken ObjectNet tend to perform poorly due to biases in other datasets that the models have learned. We also show evidence that the performance decrease is due to the dataset controls, and not the transfer setting.