 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngie Boggust
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Apr 04, 2024
Vision Transformers (ViTs), with their ability to model long-range dependencies through self-attention mechanisms, have become a standard architecture in computer vision. However, the interpretability of these models remains a challenge. To address this, we propose LeGrad, an explainability method specifically designed for ViTs. LeGrad computes the gradient with respect to the attention maps of ViT layers, considering the gradient itself as the explainability signal. We aggregate the signal over all layers, combining the activations of the last as well as intermediate tokens to produce the merged explainability map. This makes LeGrad a conceptually simple and an easy-to-implement tool for enhancing the transparency of ViTs. We evaluate LeGrad in challenging segmentation, perturbation, and open-vocabulary settings, showcasing its versatility compared to other SotA explainability methods demonstrating its superior spatial fidelity and robustness to perturbations. A demo and the code is available at https://github.com/WalBouss/LeGrad.
What is a Fair Diffusion Model? Designing Generative Text-To-Image Models to Incorporate Various Worldviews
Sep 18, 2023Generative text-to-image (GTI) models produce high-quality images from short textual descriptions and are widely used in academic and creative domains. However, GTI models frequently amplify biases from their training data, often producing prejudiced or stereotypical images. Yet, current bias mitigation strategies are limited and primarily focus on enforcing gender parity across occupations. To enhance GTI bias mitigation, we introduce DiffusionWorldViewer, a tool to analyze and manipulate GTI models' attitudes, values, stories, and expectations of the world that impact its generated images. Through an interactive interface deployed as a web-based GUI and Jupyter Notebook plugin, DiffusionWorldViewer categorizes existing demographics of GTI-generated images and provides interactive methods to align image demographics with user worldviews. In a study with 13 GTI users, we find that DiffusionWorldViewer allows users to represent their varied viewpoints about what GTI outputs are fair and, in doing so, challenges current notions of fairness that assume a universal worldview.
VisText: A Benchmark for Semantically Rich Chart Captioning
Jun 28, 2023
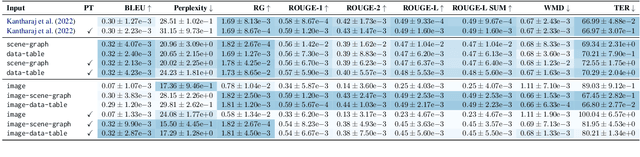
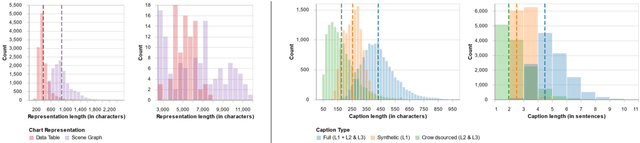
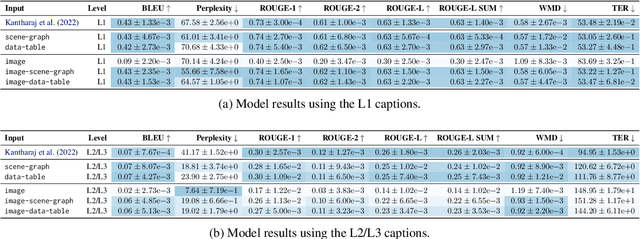
Captions that describe or explain charts help improve recall and comprehension of the depicted data and provide a more accessible medium for people with visual disabilities. However, current approaches for automatically generating such captions struggle to articulate the perceptual or cognitive features that are the hallmark of charts (e.g., complex trends and patterns). In response, we introduce VisText: a dataset of 12,441 pairs of charts and captions that describe the charts' construction, report key statistics, and identify perceptual and cognitive phenomena. In VisText, a chart is available as three representations: a rasterized image, a backing data table, and a scene graph -- a hierarchical representation of a chart's visual elements akin to a web page's Document Object Model (DOM). To evaluate the impact of VisText, we fine-tune state-of-the-art language models on our chart captioning task and apply prefix-tuning to produce captions that vary the semantic content they convey. Our models generate coherent, semantically rich captions and perform on par with state-of-the-art chart captioning models across machine translation and text generation metrics. Through qualitative analysis, we identify six broad categories of errors that our models make that can inform future work.
Beyond Faithfulness: A Framework to Characterize and Compare Saliency Methods
Jun 07, 2022
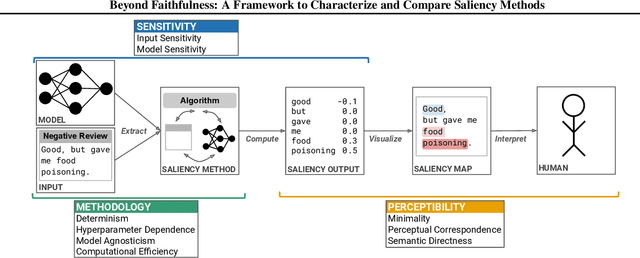
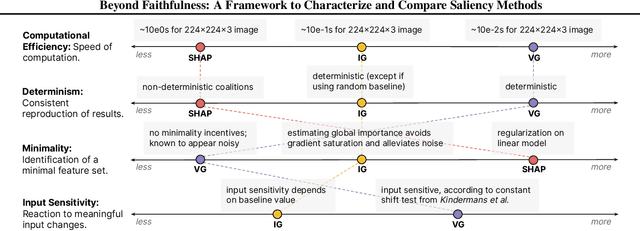

Saliency methods calculate how important each input feature is to a machine learning model's prediction, and are commonly used to understand model reasoning. "Faithfulness", or how fully and accurately the saliency output reflects the underlying model, is an oft-cited desideratum for these methods. However, explanation methods must necessarily sacrifice certain information in service of user-oriented goals such as simplicity. To that end, and akin to performance metrics, we frame saliency methods as abstractions: individual tools that provide insight into specific aspects of model behavior and entail tradeoffs. Using this framing, we describe a framework of nine dimensions to characterize and compare the properties of saliency methods. We group these dimensions into three categories that map to different phases of the interpretation process: methodology, or how the saliency is calculated; sensitivity, or relationships between the saliency result and the underlying model or input; and, perceptibility, or how a user interprets the result. As we show, these dimensions give us a granular vocabulary for describing and comparing saliency methods -- for instance, allowing us to develop "saliency cards" as a form of documentation, or helping downstream users understand tradeoffs and choose a method for a particular use case. Moreover, by situating existing saliency methods within this framework, we identify opportunities for future work, including filling gaps in the landscape and developing new evaluation metrics.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021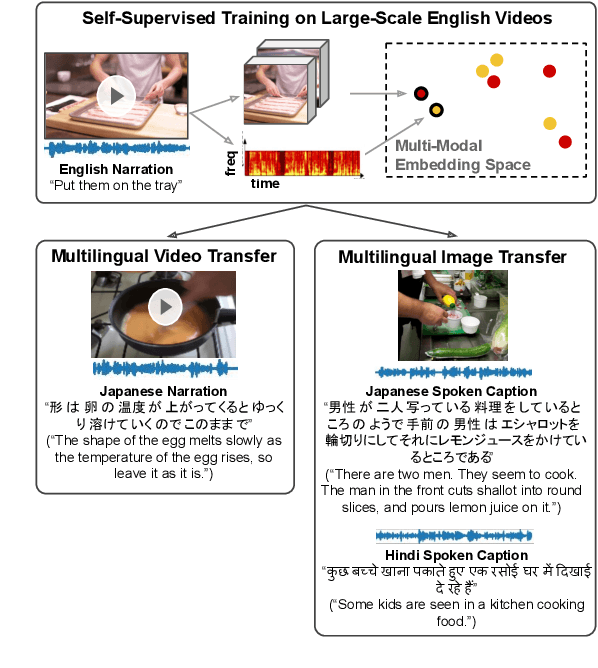
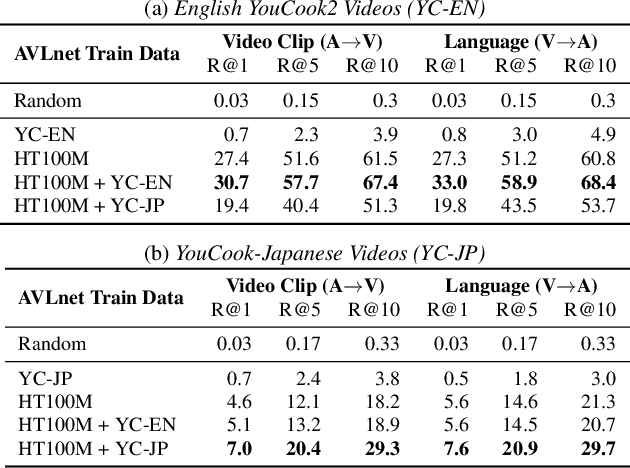

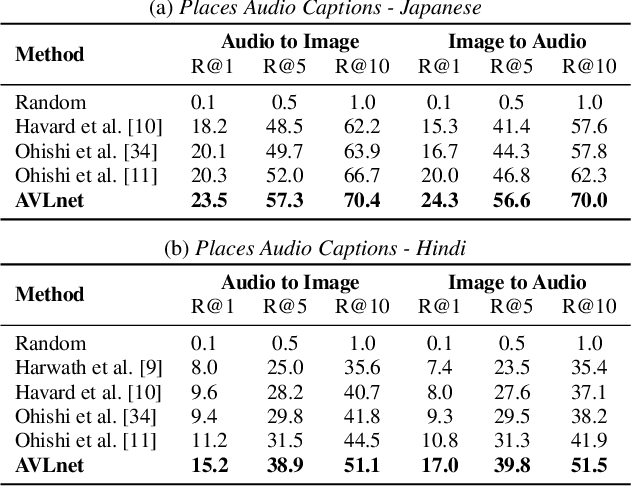
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Shared Interest: Large-Scale Visual Analysis of Model Behavior by Measuring Human-AI Alignment
Jul 20, 2021
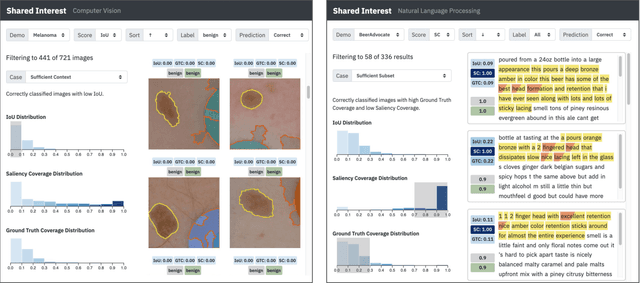

Saliency methods -- techniques to identify the importance of input features on a model's output -- are a common first step in understanding neural network behavior. However, interpreting saliency requires tedious manual inspection to identify and aggregate patterns in model behavior, resulting in ad hoc or cherry-picked analysis. To address these concerns, we present Shared Interest: a set of metrics for comparing saliency with human annotated ground truths. By providing quantitative descriptors, Shared Interest allows ranking, sorting, and aggregation of inputs thereby facilitating large-scale systematic analysis of model behavior. We use Shared Interest to identify eight recurring patterns in model behavior including focusing on a sufficient subset of ground truth features or being distracted by contextual features. Working with representative real-world users, we show how Shared Interest can be used to rapidly develop or lose trust in a model's reliability, uncover issues that are missed in manual analyses, and enable interactive probing of model behavior.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021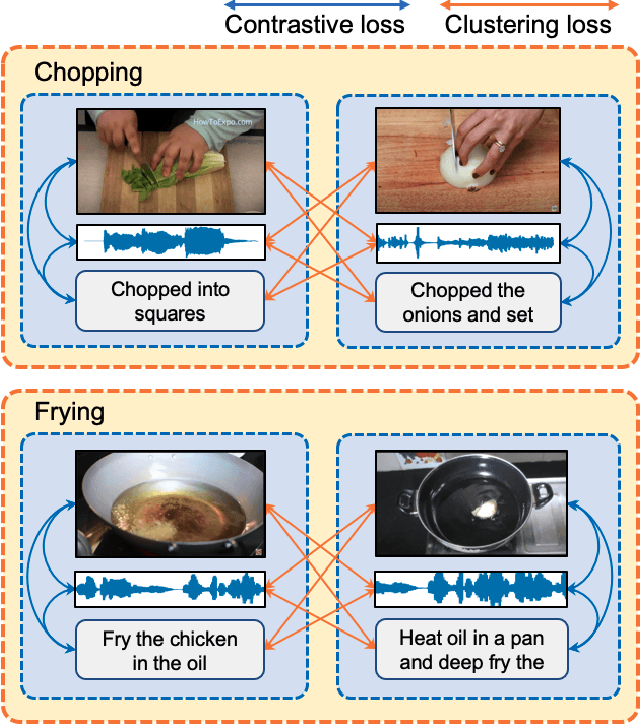
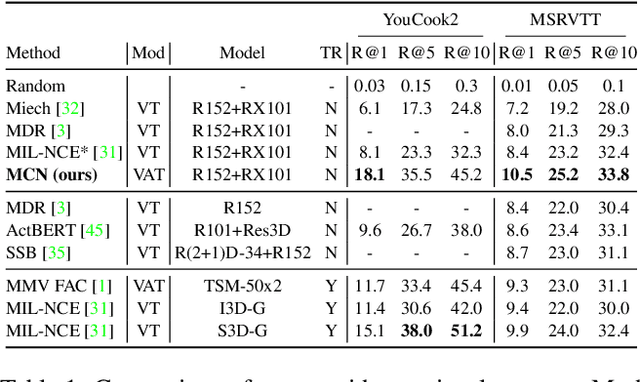
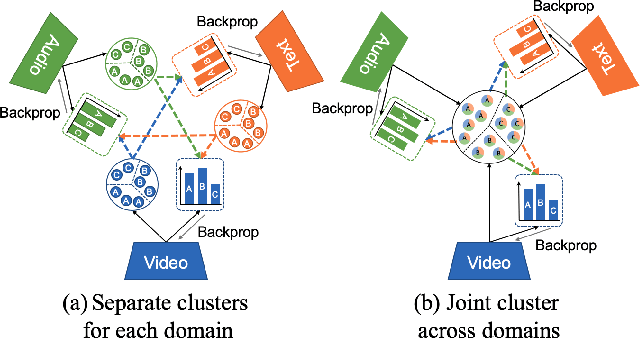
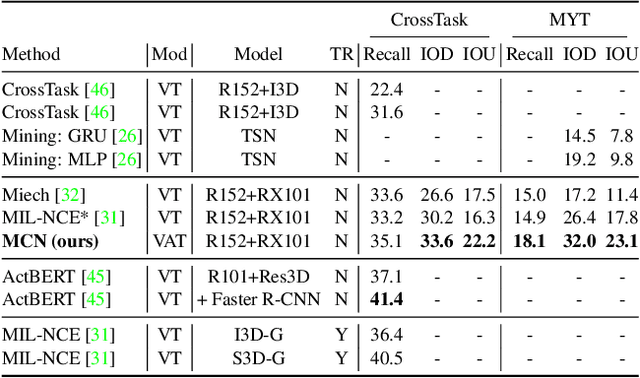
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Jun 16, 2020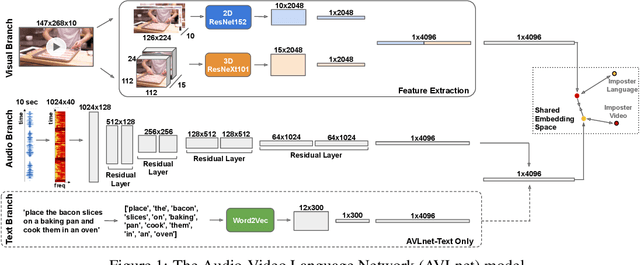
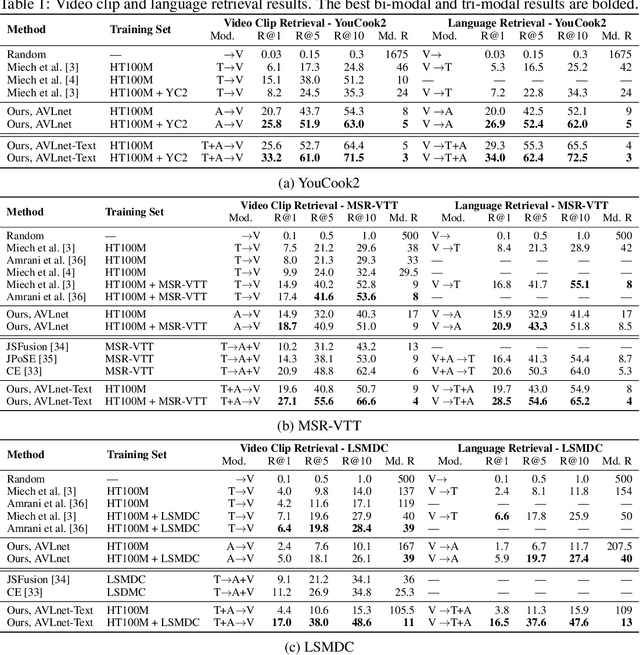
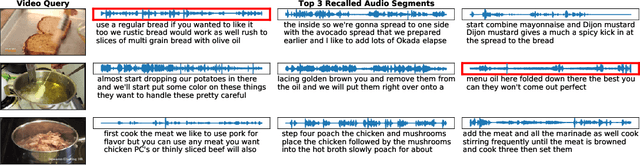
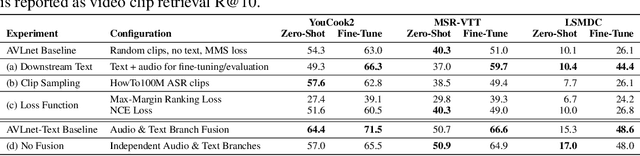
Current methods for learning visually grounded language from videos often rely on time-consuming and expensive data collection, such as human annotated textual summaries or machine generated automatic speech recognition transcripts. In this work, we introduce Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. We circumvent the need for annotation and instead learn audio-visual language representations directly from randomly segmented video clips and their raw audio waveforms. We train AVLnet on publicly available instructional videos and evaluate our model on video clip and language retrieval tasks on three video datasets. Our proposed model outperforms several state-of-the-art text-video baselines by up to 11.8% in a video clip retrieval task, despite operating on the raw audio instead of manually annotated text captions. Further, we show AVLnet is capable of integrating textual information, increasing its modularity and improving performance by up to 20.3% on the video clip retrieval task. Finally, we perform analysis of AVLnet's learned representations, showing our model has learned to relate visual objects with salient words and natural sounds.
Embedding Comparator: Visualizing Differences in Global Structure and Local Neighborhoods via Small Multiples
Dec 10, 2019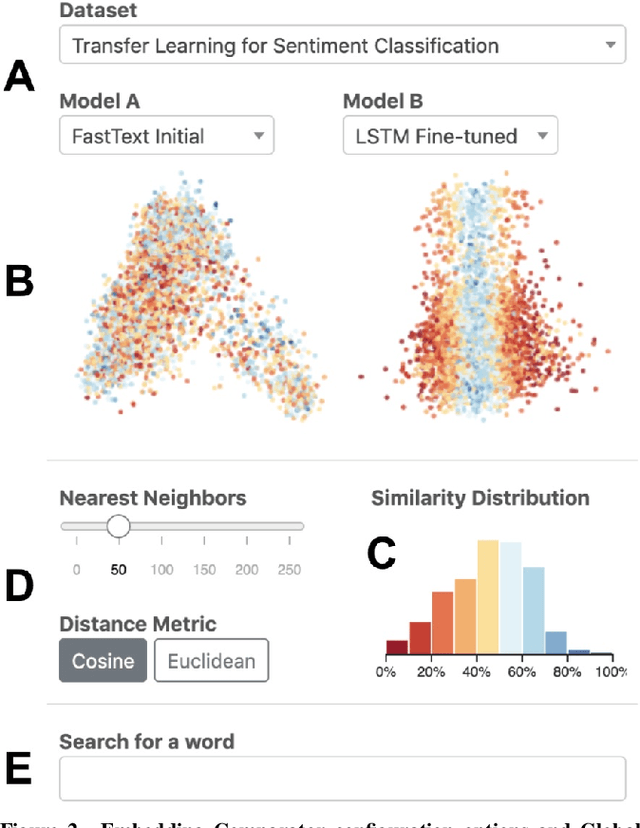
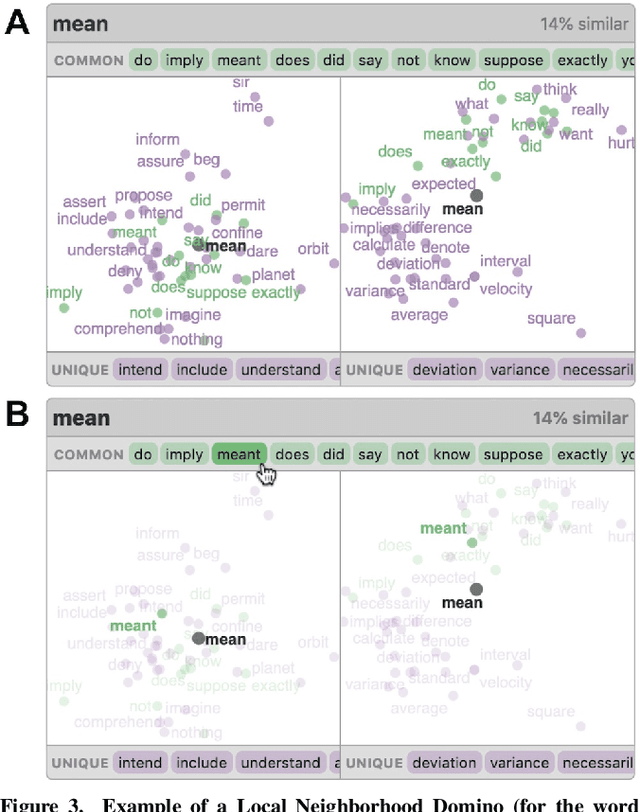

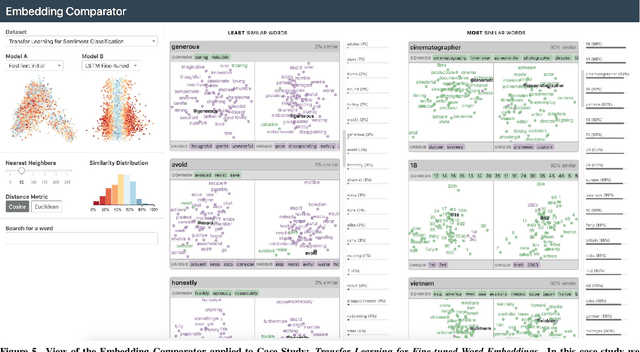
Embeddings -- mappings from high-dimensional discrete input to lower-dimensional continuous vector spaces -- have been widely adopted in machine learning, linguistics, and computational biology as they often surface interesting and unexpected domain semantics. Through semi-structured interviews with embedding model researchers and practitioners, we find that current tools poorly support a central concern: comparing different embeddings when developing fairer, more robust models. In response, we present the Embedding Comparator, an interactive system that balances gaining an overview of the embedding spaces with making fine-grained comparisons of local neighborhoods. For a pair of models, we compute the similarity of the k-nearest neighbors of every embedded object, and visualize the results as Local Neighborhood Dominoes: small multiples that facilitate rapid comparisons. Using case studies, we illustrate the types of insights the Embedding Comparator reveals including how fine-tuning embeddings changes semantics, how language changes over time, and how training data differences affect two seemingly similar models.