 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenjamin Burchfiel
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Feb 19, 2024
We present Universal Manipulation Interface (UMI) -- a data collection and policy learning framework that allows direct skill transfer from in-the-wild human demonstrations to deployable robot policies. UMI employs hand-held grippers coupled with careful interface design to enable portable, low-cost, and information-rich data collection for challenging bimanual and dynamic manipulation demonstrations. To facilitate deployable policy learning, UMI incorporates a carefully designed policy interface with inference-time latency matching and a relative-trajectory action representation. The resulting learned policies are hardware-agnostic and deployable across multiple robot platforms. Equipped with these features, UMI framework unlocks new robot manipulation capabilities, allowing zero-shot generalizable dynamic, bimanual, precise, and long-horizon behaviors, by only changing the training data for each task. We demonstrate UMI's versatility and efficacy with comprehensive real-world experiments, where policies learned via UMI zero-shot generalize to novel environments and objects when trained on diverse human demonstrations. UMI's hardware and software system is open-sourced at https://umi-gripper.github.io.
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Mar 10, 2023
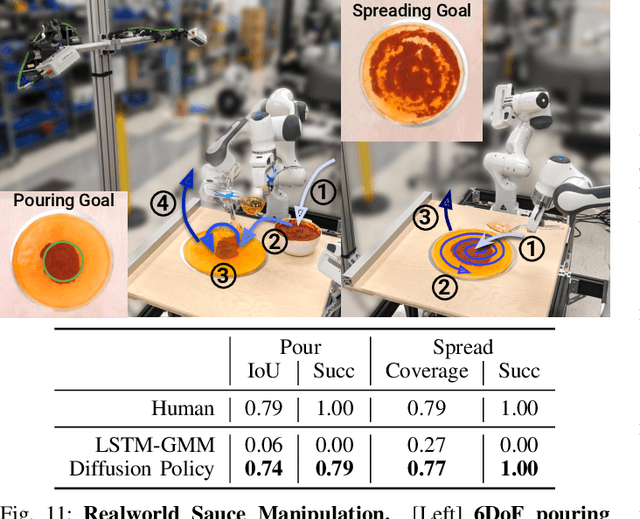
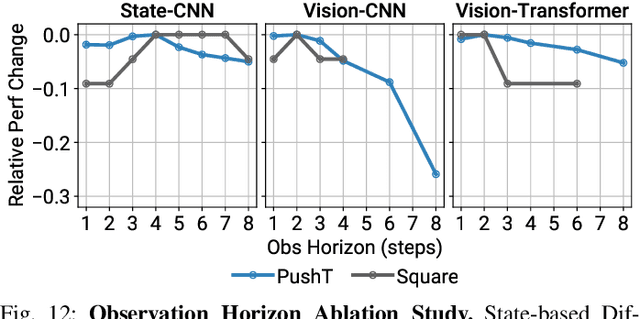
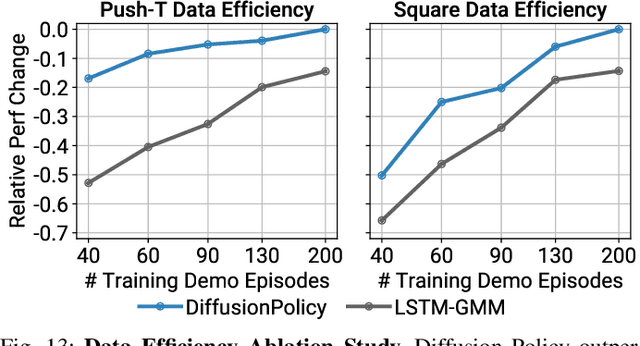
This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 11 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available.
AdaptSim: Task-Driven Simulation Adaptation for Sim-to-Real Transfer
Feb 09, 2023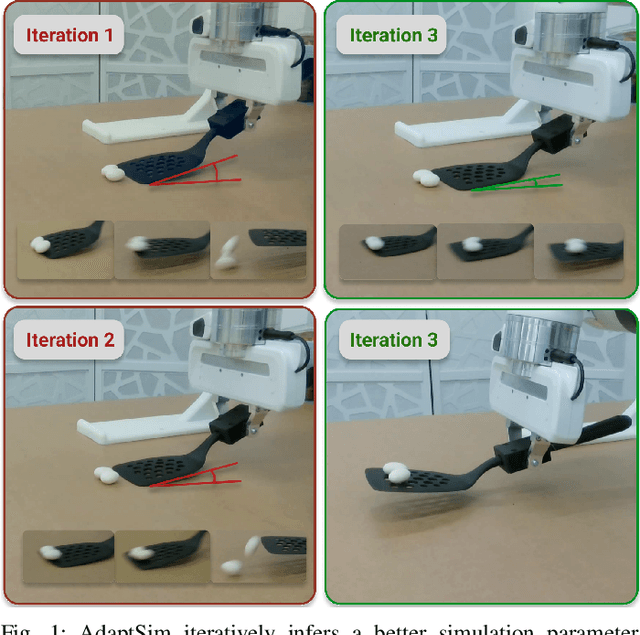
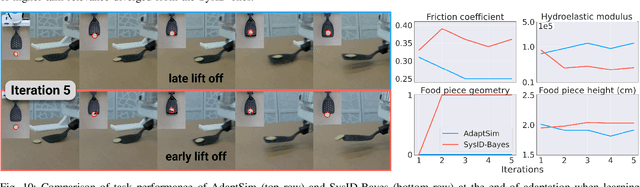

Simulation parameter settings such as contact models and object geometry approximations are critical to training robust robotic policies capable of transferring from simulation to real-world deployment. Previous approaches typically handcraft distributions over such parameters (domain randomization), or identify parameters that best match the dynamics of the real environment (system identification). However, there is often an irreducible gap between simulation and reality: attempting to match the dynamics between simulation and reality across all states and tasks may be infeasible and may not lead to policies that perform well in reality for a specific task. Addressing this issue, we propose AdaptSim, a new task-driven adaptation framework for sim-to-real transfer that aims to optimize task performance in target (real) environments -- instead of matching dynamics between simulation and reality. First, we meta-learn an adaptation policy in simulation using reinforcement learning for adjusting the simulation parameter distribution based on the current policy's performance in a target environment. We then perform iterative real-world adaptation by inferring new simulation parameter distributions for policy training, using a small amount of real data. We perform experiments in three robotic tasks: (1) swing-up of linearized double pendulum, (2) dynamic table-top pushing of a bottle, and (3) dynamic scooping of food pieces with a spatula. Our extensive simulation and hardware experiments demonstrate AdaptSim achieving 1-3x asymptotic performance and $\sim$2x real data efficiency when adapting to different environments, compared to methods based on Sys-ID and directly training the task policy in target environments.
Bag All You Need: Learning a Generalizable Bagging Strategy for Heterogeneous Objects
Oct 18, 2022
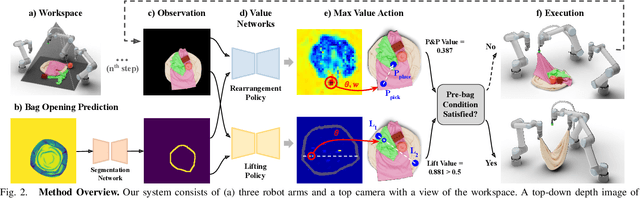
We introduce a practical robotics solution for the task of heterogeneous bagging, requiring the placement of multiple rigid and deformable objects into a deformable bag. This is a difficult task as it features complex interactions between multiple highly deformable objects under limited observability. To tackle these challenges, we propose a robotic system consisting of two learned policies: a rearrangement policy that learns to place multiple rigid objects and fold deformable objects in order to achieve desirable pre-bagging conditions, and a lifting policy to infer suitable grasp points for bi-manual bag lifting. We evaluate these learned policies on a real-world three-arm robot platform that achieves a 70% heterogeneous bagging success rate with novel objects. To facilitate future research and comparison, we also develop a novel heterogeneous bagging simulation benchmark that will be made publicly available.
Cloth Funnels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation
Oct 17, 2022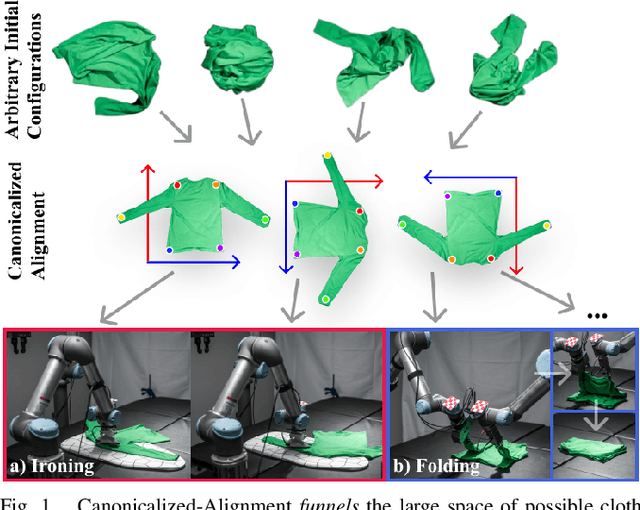
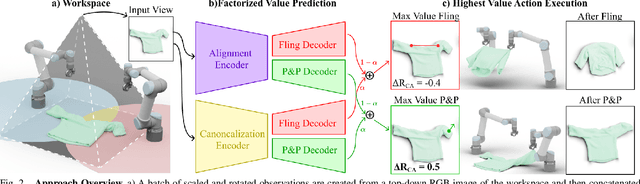
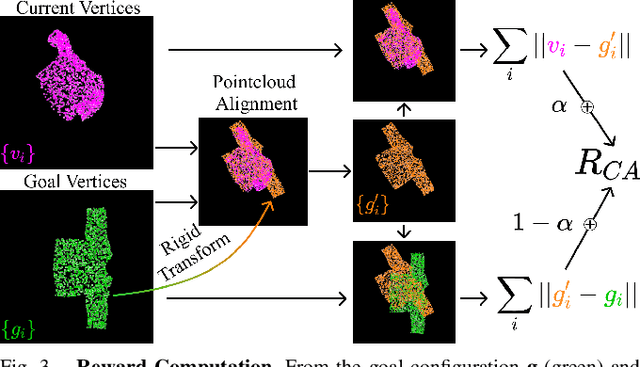
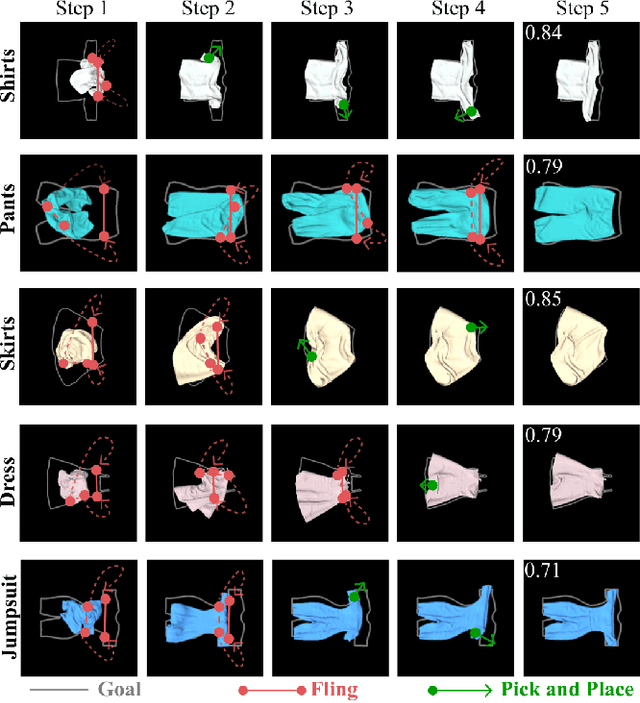
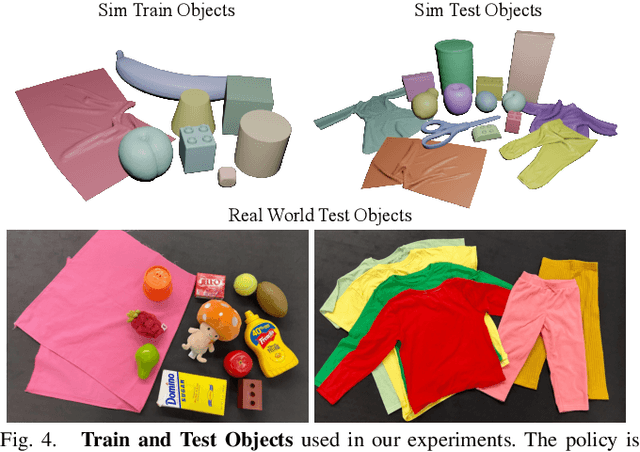
Automating garment manipulation is challenging due to extremely high variability in object configurations. To reduce this intrinsic variation, we introduce the task of "canonicalized-alignment" that simplifies downstream applications by reducing the possible garment configurations. This task can be considered as "cloth state funnel" that manipulates arbitrarily configured clothing items into a predefined deformable configuration (i.e. canonicalization) at an appropriate rigid pose (i.e. alignment). In the end, the cloth items will result in a compact set of structured and highly visible configurations - which are desirable for downstream manipulation skills. To enable this task, we propose a novel canonicalized-alignment objective that effectively guides learning to avoid adverse local minima during learning. Using this objective, we learn a multi-arm, multi-primitive policy that strategically chooses between dynamic flings and quasi-static pick and place actions to achieve efficient canonicalized-alignment. We evaluate this approach on a real-world ironing and folding system that relies on this learned policy as the common first step. Empirically, we demonstrate that our task-agnostic canonicalized-alignment can enable even simple manually-designed policies to work well where they were previously inadequate, thus bridging the gap between automated non-deformable manufacturing and deformable manipulation. Code and qualitative visualizations are available at https://clothfunnels.cs.columbia.edu/. Video can be found at https://www.youtube.com/watch?v=TkUn0b7mbj0.
DextAIRity: Deformable Manipulation Can be a Breeze
Mar 08, 2022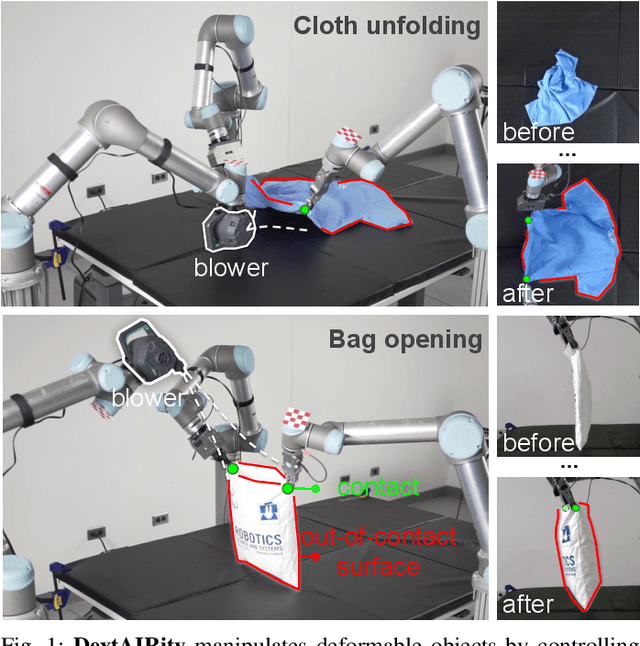



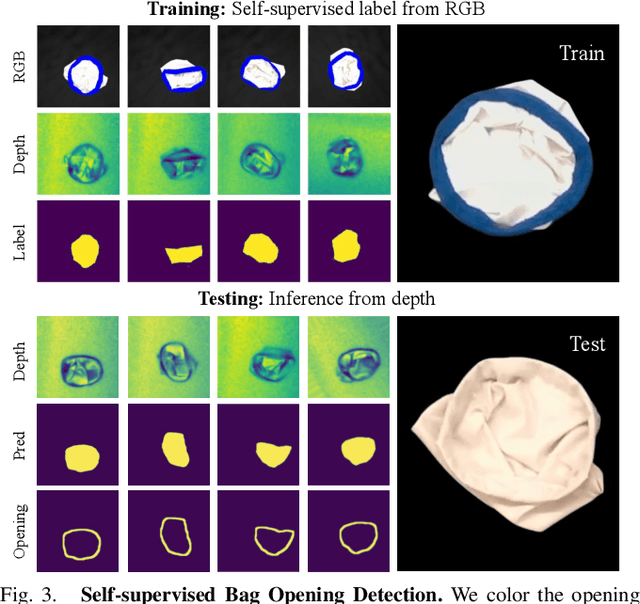
This paper introduces DextAIRity, an approach to manipulate deformable objects using active airflow. In contrast to conventional contact-based quasi-static manipulations, DextAIRity allows the system to apply dense forces on out-of-contact surfaces, expands the system's reach range, and provides safe high-speed interactions. These properties are particularly advantageous when manipulating under-actuated deformable objects with large surface areas or volumes. We demonstrate the effectiveness of DextAIRity through two challenging deformable object manipulation tasks: cloth unfolding and bag opening. We present a self-supervised learning framework that learns to effectively perform a target task through a sequence of grasping or air-based blowing actions. By using a closed-loop formulation for blowing, the system continuously adjusts its blowing direction based on visual feedback in a way that is robust to the highly stochastic dynamics. We deploy our algorithm on a real-world three-arm system and present evidence suggesting that DextAIRity can improve system efficiency for challenging deformable manipulation tasks, such as cloth unfolding, and enable new applications that are impractical to solve with quasi-static contact-based manipulations (e.g., bag opening). Video is available at https://youtu.be/_B0TpAa5tVo
Iterative Residual Policy: for Goal-Conditioned Dynamic Manipulation of Deformable Objects
Mar 01, 2022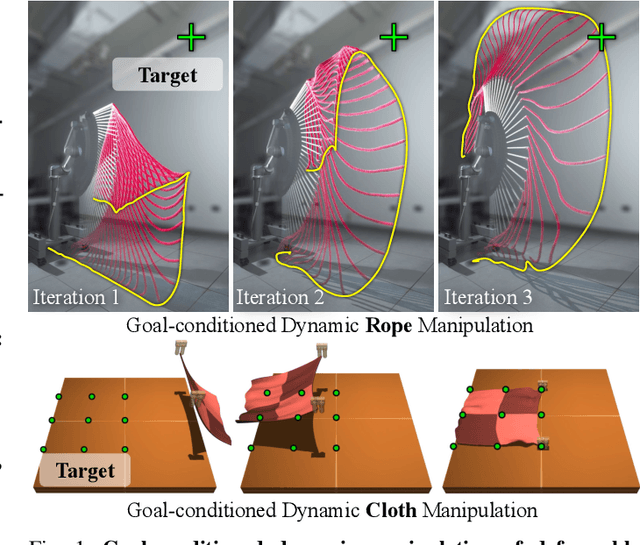
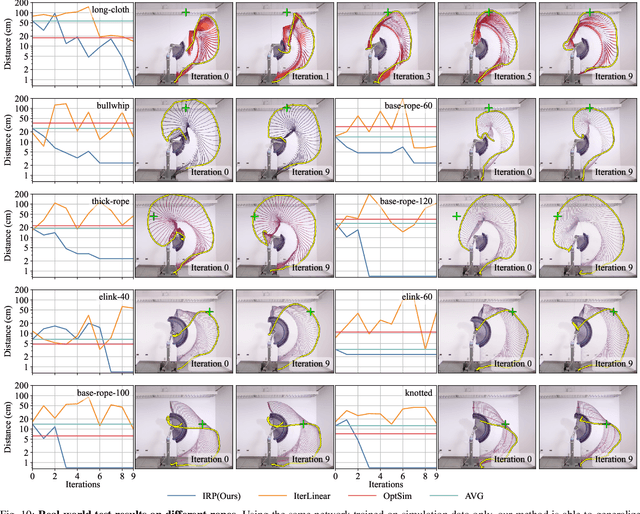
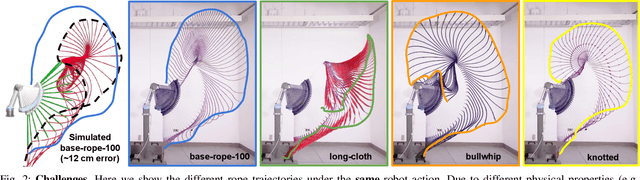
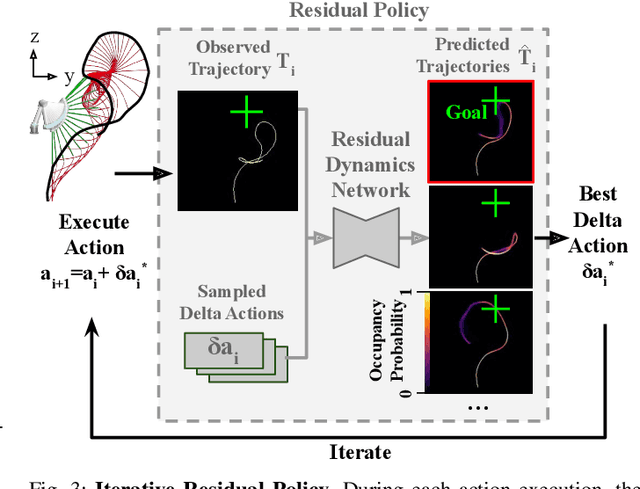
This paper tackles the task of goal-conditioned dynamic manipulation of deformable objects. This task is highly challenging due to its complex dynamics (introduced by object deformation and high-speed action) and strict task requirements (defined by a precise goal specification). To address these challenges, we present Iterative Residual Policy (IRP), a general learning framework applicable to repeatable tasks with complex dynamics. IRP learns an implicit policy via residual dynamics -- instead of modeling the entire dynamical system and inferring actions from that model, IRP learns residual dynamics that predict the effects of delta action on the previously-observed trajectory. When combined with adaptive action sampling, the system can quickly optimize its actions online to reach a specified goal. We demonstrate the effectiveness of IRP on two tasks: whipping a rope to hit a target point and swinging a cloth to reach a target pose. Despite being trained only in simulation on a fixed robot setup, IRP is able to efficiently generalize to noisy real-world dynamics, new objects with unseen physical properties, and even different robot hardware embodiments, demonstrating its excellent generalization capability relative to alternative approaches. Video is available at https://youtu.be/7h3SZ3La-oA
Grounding Language Attributes to Objects using Bayesian Eigenobjects
May 30, 2019
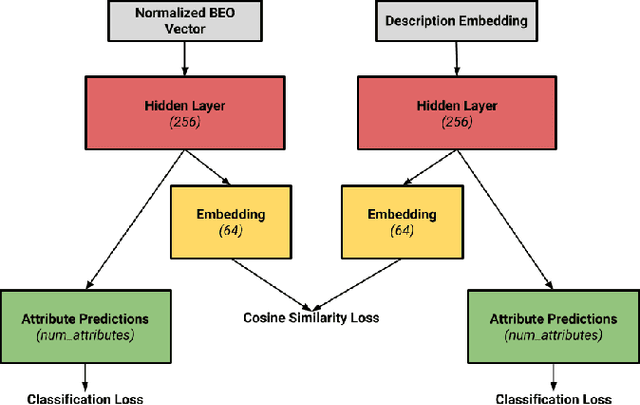
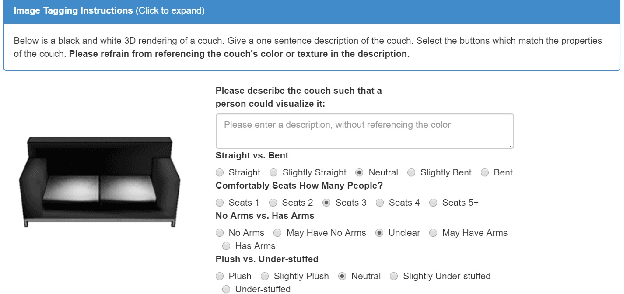
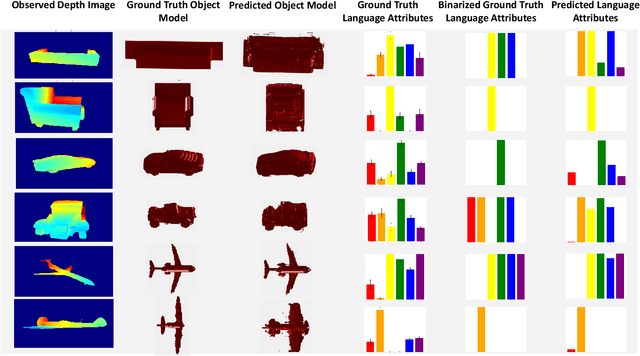
We develop a system to disambiguate objects based on simple physical descriptions. The system takes as input a natural language phrase and a depth image containing a segmented object and predicts how similar the observed object is to the described object. Our system is designed to learn from only a small amount of human-labeled language data and generalize to viewpoints not represented in the language-annotated depth-image training set. By decoupling 3D shape representation from language representation, our method is able to ground language to novel objects using a small amount of language-annotated depth-data and a larger corpus of unlabeled 3D object meshes, even when these objects are partially observed from unusual viewpoints. Our system is able to disambiguate between novel objects, observed via depth-images, based on natural language descriptions. Our method also enables view-point transfer; trained on human-annotated data on a small set of depth-images captured from frontal viewpoints, our system successfully predicted object attributes from rear views despite having no such depth images in its training set. Finally, we demonstrate our system on a Baxter robot, enabling it to pick specific objects based on human-provided natural language descriptions.
Probabilistic Category-Level Pose Estimation via Segmentation and Predicted-Shape Priors
May 28, 2019
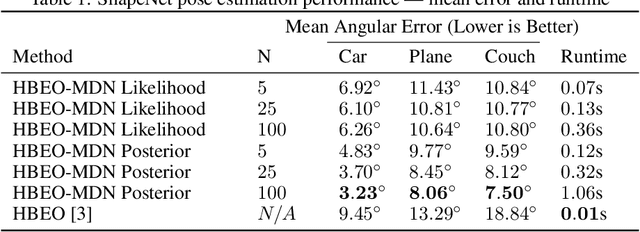
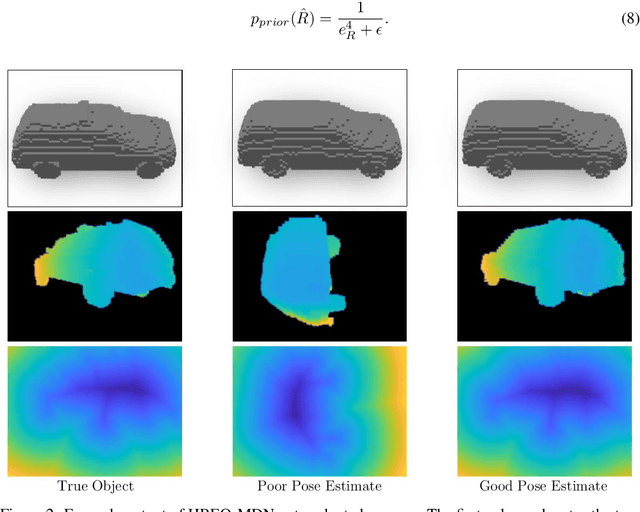
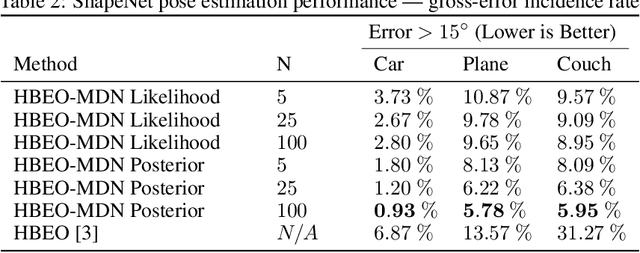
We introduce a new method for category-level pose estimation which produces a distribution over predicted poses by integrating 3D shape estimates from a generative object model with segmentation information. Given an input depth-image of an object, our variable-time method uses a mixture density network architecture to produce a multi-modal distribution over 3DOF poses; this distribution is then combined with a prior probability encouraging silhouette agreement between the observed input and predicted object pose. Our approach significantly outperforms the current state-of-the-art in category-level 3DOF pose estimation---which outputs a point estimate and does not explicitly incorporate shape and segmentation information---as measured on the Pix3D and ShapeNet datasets.