 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanya Cohen
Planning with Large Language Models via Corrective Re-prompting
Nov 17, 2022
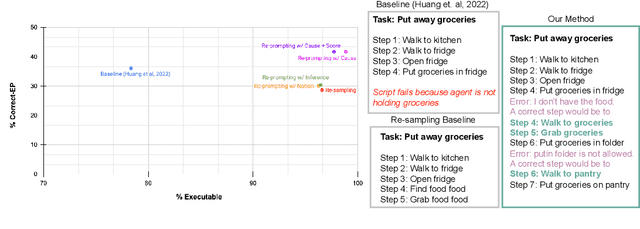
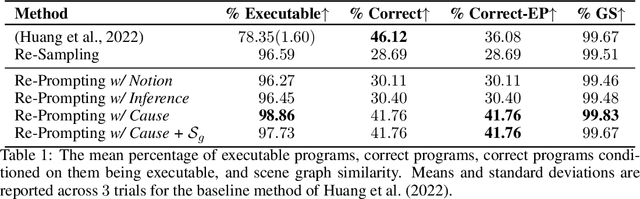
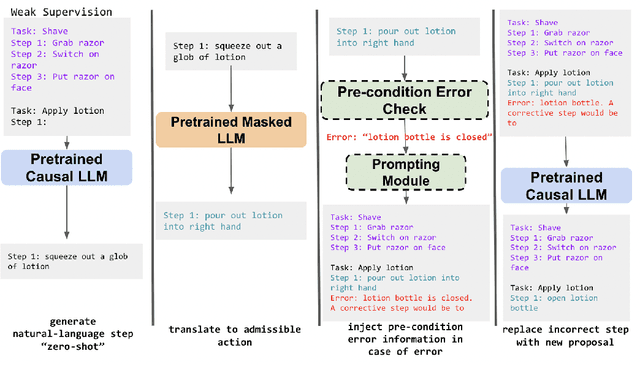
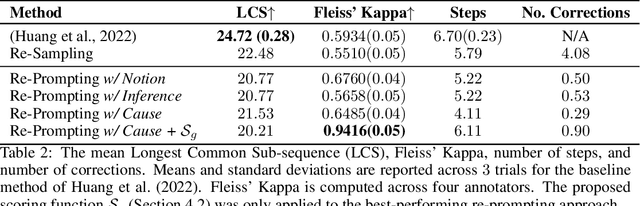
Extracting the common sense knowledge present in Large Language Models (LLMs) offers a path to designing intelligent, embodied agents. Related works have queried LLMs with a wide-range of contextual information, such as goals, sensor observations and scene descriptions, to generate high-level action plans for specific tasks; however these approaches often involve human intervention or additional machinery to enable sensor-motor interactions. In this work, we propose a prompting-based strategy for extracting executable plans from an LLM, which leverages a novel and readily-accessible source of information: precondition errors. Our approach assumes that actions are only afforded execution in certain contexts, i.e., implicit preconditions must be met for an action to execute (e.g., a door must be unlocked to open it), and that the embodied agent has the ability to determine if the action is/is not executable in the current context (e.g., detect if a precondition error is present). When an agent is unable to execute an action, our approach re-prompts the LLM with precondition error information to extract an executable corrective action to achieve the intended goal in the current context. We evaluate our approach in the VirtualHome simulation environment on 88 different tasks and 7 scenes. We evaluate different prompt templates and compare to methods that naively re-sample actions from the LLM. Our approach, using precondition errors, improves executability and semantic correctness of plans, while also reducing the number of re-prompts required when querying actions.
Learning to Follow Language Instructions with Compositional Policies
Oct 09, 2021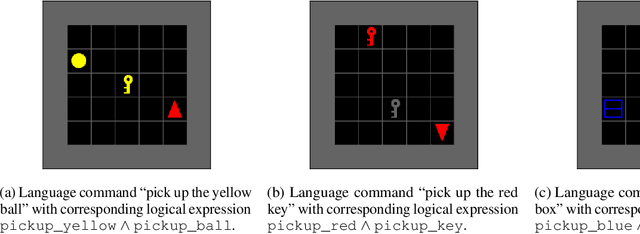

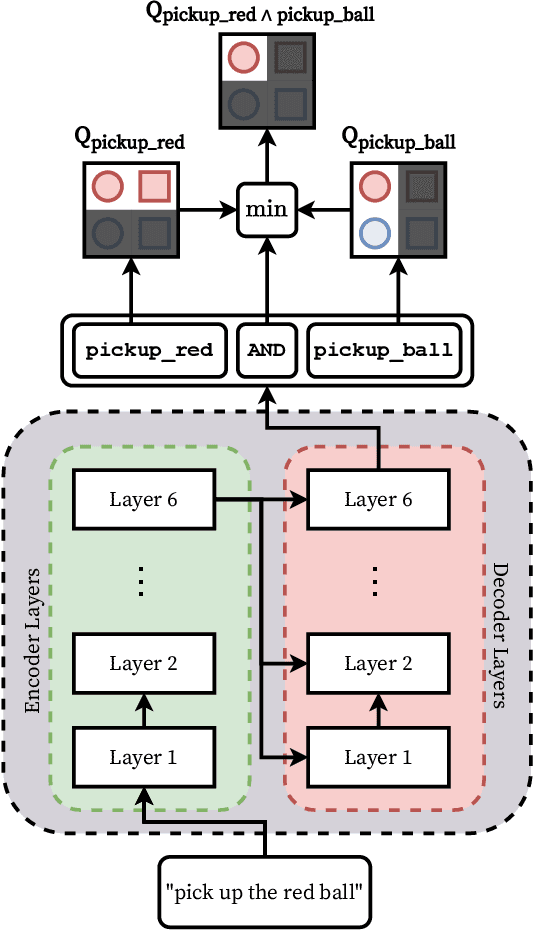

We propose a framework that learns to execute natural language instructions in an environment consisting of goal-reaching tasks that share components of their task descriptions. Our approach leverages the compositionality of both value functions and language, with the aim of reducing the sample complexity of learning novel tasks. First, we train a reinforcement learning agent to learn value functions that can be subsequently composed through a Boolean algebra to solve novel tasks. Second, we fine-tune a seq2seq model pretrained on web-scale corpora to map language to logical expressions that specify the required value function compositions. Evaluating our agent in the BabyAI domain, we observe a decrease of 86% in the number of training steps needed to learn a second task after mastering a single task. Results from ablation studies further indicate that it is the combination of compositional value functions and language representations that allows the agent to quickly generalize to new tasks.
Grounding Language Attributes to Objects using Bayesian Eigenobjects
May 30, 2019
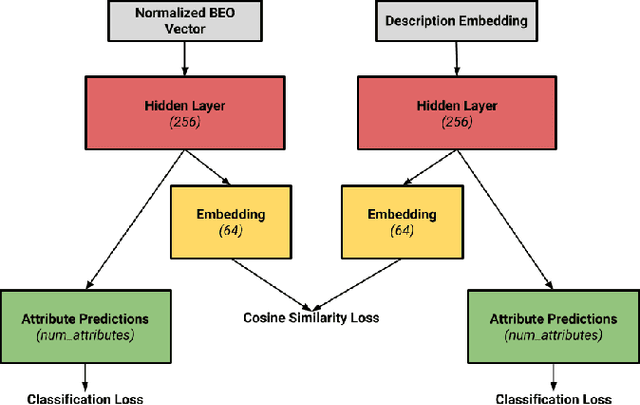
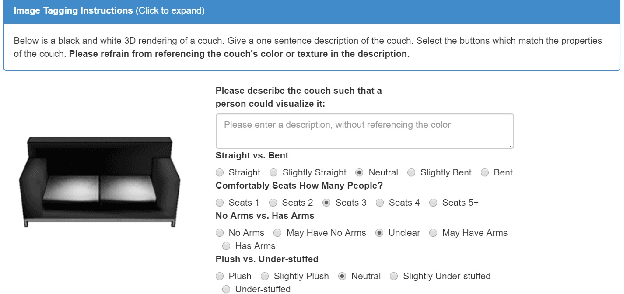
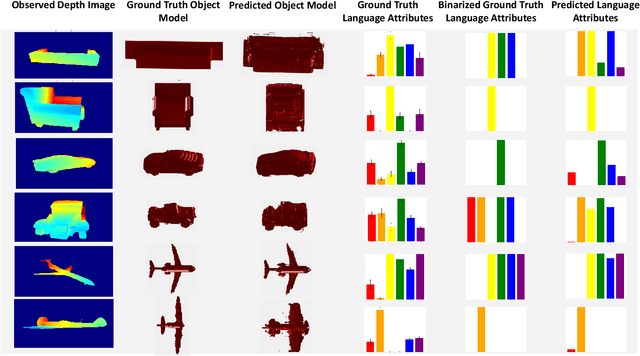
We develop a system to disambiguate objects based on simple physical descriptions. The system takes as input a natural language phrase and a depth image containing a segmented object and predicts how similar the observed object is to the described object. Our system is designed to learn from only a small amount of human-labeled language data and generalize to viewpoints not represented in the language-annotated depth-image training set. By decoupling 3D shape representation from language representation, our method is able to ground language to novel objects using a small amount of language-annotated depth-data and a larger corpus of unlabeled 3D object meshes, even when these objects are partially observed from unusual viewpoints. Our system is able to disambiguate between novel objects, observed via depth-images, based on natural language descriptions. Our method also enables view-point transfer; trained on human-annotated data on a small set of depth-images captured from frontal viewpoints, our system successfully predicted object attributes from rear views despite having no such depth images in its training set. Finally, we demonstrate our system on a Baxter robot, enabling it to pick specific objects based on human-provided natural language descriptions.