 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNakul Gopalan
Interactive Visual Task Learning for Robots
Dec 20, 2023
We present a framework for robots to learn novel visual concepts and tasks via in-situ linguistic interactions with human users. Previous approaches have either used large pre-trained visual models to infer novel objects zero-shot, or added novel concepts along with their attributes and representations to a concept hierarchy. We extend the approaches that focus on learning visual concept hierarchies by enabling them to learn novel concepts and solve unseen robotics tasks with them. To enable a visual concept learner to solve robotics tasks one-shot, we developed two distinct techniques. Firstly, we propose a novel approach, Hi-Viscont(HIerarchical VISual CONcept learner for Task), which augments information of a novel concept to its parent nodes within a concept hierarchy. This information propagation allows all concepts in a hierarchy to update as novel concepts are taught in a continual learning setting. Secondly, we represent a visual task as a scene graph with language annotations, allowing us to create novel permutations of a demonstrated task zero-shot in-situ. We present two sets of results. Firstly, we compare Hi-Viscont with the baseline model (FALCON) on visual question answering(VQA) in three domains. While being comparable to the baseline model on leaf level concepts, Hi-Viscont achieves an improvement of over 9% on non-leaf concepts on average. We compare our model's performance against the baseline FALCON model. Our framework achieves 33% improvements in success rate metric, and 19% improvements in the object level accuracy compared to the baseline model. With both of these results we demonstrate the ability of our model to learn tasks and concepts in a continual learning setting on the robot.
Improved Inference of Human Intent by Combining Plan Recognition and Language Feedback
Oct 03, 2023Conversational assistive robots can aid people, especially those with cognitive impairments, to accomplish various tasks such as cooking meals, performing exercises, or operating machines. However, to interact with people effectively, robots must recognize human plans and goals from noisy observations of human actions, even when the user acts sub-optimally. Previous works on Plan and Goal Recognition (PGR) as planning have used hierarchical task networks (HTN) to model the actor/human. However, these techniques are insufficient as they do not have user engagement via natural modes of interaction such as language. Moreover, they have no mechanisms to let users, especially those with cognitive impairments, know of a deviation from their original plan or about any sub-optimal actions taken towards their goal. We propose a novel framework for plan and goal recognition in partially observable domains -- Dialogue for Goal Recognition (D4GR) enabling a robot to rectify its belief in human progress by asking clarification questions about noisy sensor data and sub-optimal human actions. We evaluate the performance of D4GR over two simulated domains -- kitchen and blocks domain. With language feedback and the world state information in a hierarchical task model, we show that D4GR framework for the highest sensor noise performs 1% better than HTN in goal accuracy in both domains. For plan accuracy, D4GR outperforms by 4% in the kitchen domain and 2% in the blocks domain in comparison to HTN. The ALWAYS-ASK oracle outperforms our policy by 3% in goal recognition and 7%in plan recognition. D4GR does so by asking 68% fewer questions than an oracle baseline. We also demonstrate a real-world robot scenario in the kitchen domain, validating the improved plan and goal recognition of D4GR in a realistic setting.
Language-Conditioned Change-point Detection to Identify Sub-Tasks in Robotics Domains
Sep 01, 2023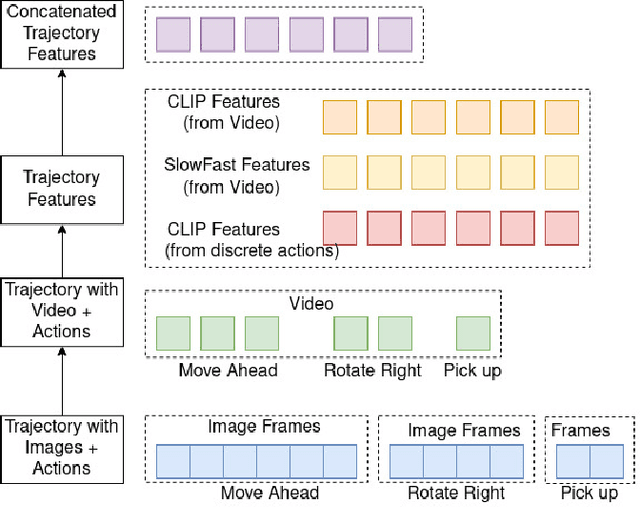



In this work, we present an approach to identify sub-tasks within a demonstrated robot trajectory using language instructions. We identify these sub-tasks using language provided during demonstrations as guidance to identify sub-segments of a longer robot trajectory. Given a sequence of natural language instructions and a long trajectory consisting of image frames and discrete actions, we want to map an instruction to a smaller fragment of the trajectory. Unlike previous instruction following works which directly learn the mapping from language to a policy, we propose a language-conditioned change-point detection method to identify sub-tasks in a problem. Our approach learns the relationship between constituent segments of a long language command and corresponding constituent segments of a trajectory. These constituent trajectory segments can be used to learn subtasks or sub-goals for planning or options as demonstrated by previous related work. Our insight in this work is that the language-conditioned robot change-point detection problem is similar to the existing video moment retrieval works used to identify sub-segments within online videos. Through extensive experimentation, we demonstrate a $1.78_{\pm 0.82}\%$ improvement over a baseline approach in accurately identifying sub-tasks within a trajectory using our proposed method. Moreover, we present a comprehensive study investigating sample complexity requirements on learning this mapping, between language and trajectory sub-segments, to understand if the video retrieval-based methods are realistic in real robot scenarios.
Learning Efficient Exploration through Human Seeded Rapidly-exploring Random Trees
Mar 23, 2022
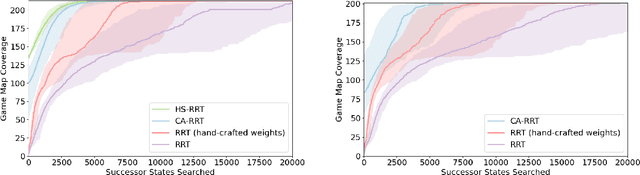
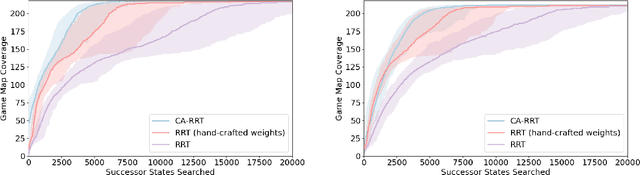
Modern day computer games have extremely large state and action spaces. To detect bugs in these games' models, human testers play the games repeatedly to explore the game and find errors in the games. Such game play is exhaustive and time consuming. Moreover, since robotics simulators depend on similar methods of model specification and debugging, the problem of finding errors in the model is of interest for the robotics community to ensure robot behaviors and interactions are consistent in simulators. Previous methods have used reinforcement learning and search based methods including Rapidly-exploring Random Trees (RRT) to explore a game's state-action space to find bugs. However, such search and exploration based methods are not efficient at exploring the state-action space without a pre-defined heuristic. In this work we attempt to combine a human-tester's expertise in solving games, and the exhaustiveness of RRT to search a game's state space efficiently with high coverage. This paper introduces human-seeded RRT (HS-RRT) and behavior-cloning-assisted RRT (CA-RRT) in testing the number of game states searched and the time taken to explore those game states. We compare our methods to an existing weighted RRT baseline for game exploration testing studied. We find HS-RRT and CA-RRT both explore more game states in fewer tree expansions/iterations when compared to the existing baseline. In each test, CA-RRT reached more states on average in the same number of iterations as RRT. In our tested environments, CA-RRT was able to reach the same number of states as RRT by more than 5000 fewer iterations on average, almost a 50% reduction.
Learning to Follow Language Instructions with Compositional Policies
Oct 09, 2021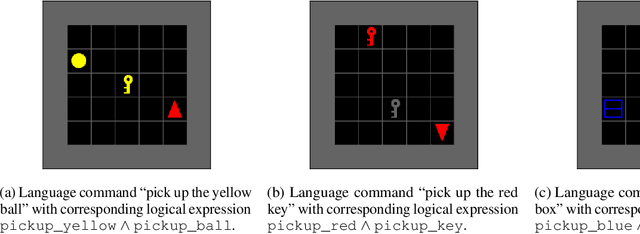

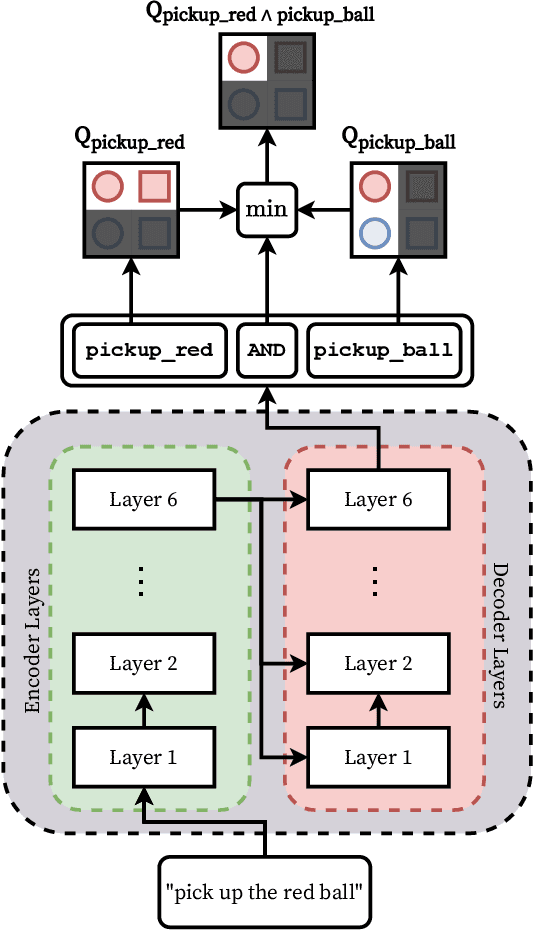

We propose a framework that learns to execute natural language instructions in an environment consisting of goal-reaching tasks that share components of their task descriptions. Our approach leverages the compositionality of both value functions and language, with the aim of reducing the sample complexity of learning novel tasks. First, we train a reinforcement learning agent to learn value functions that can be subsequently composed through a Boolean algebra to solve novel tasks. Second, we fine-tune a seq2seq model pretrained on web-scale corpora to map language to logical expressions that specify the required value function compositions. Evaluating our agent in the BabyAI domain, we observe a decrease of 86% in the number of training steps needed to learn a second task after mastering a single task. Results from ablation studies further indicate that it is the combination of compositional value functions and language representations that allows the agent to quickly generalize to new tasks.
Interpretable Policy Specification and Synthesis through Natural Language and RL
Jan 18, 2021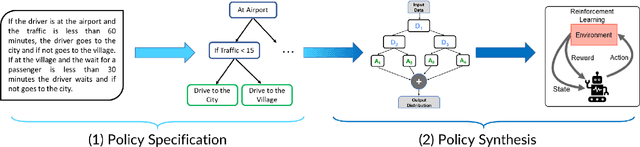
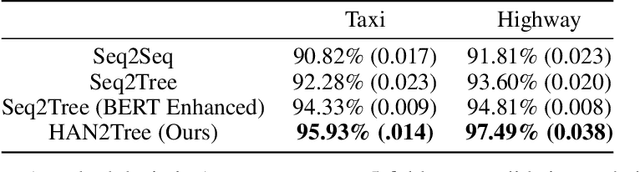
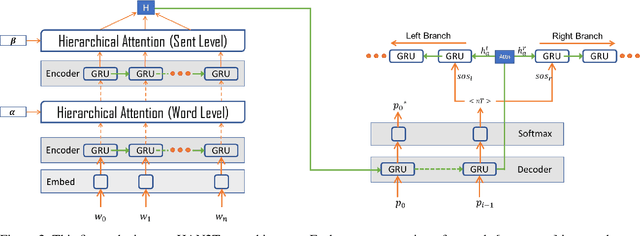

Policy specification is a process by which a human can initialize a robot's behaviour and, in turn, warm-start policy optimization via Reinforcement Learning (RL). While policy specification/design is inherently a collaborative process, modern methods based on Learning from Demonstration or Deep RL lack the model interpretability and accessibility to be classified as such. Current state-of-the-art methods for policy specification rely on black-box models, which are an insufficient means of collaboration for non-expert users: These models provide no means of inspecting policies learnt by the agent and are not focused on creating a usable modality for teaching robot behaviour. In this paper, we propose a novel machine learning framework that enables humans to 1) specify, through natural language, interpretable policies in the form of easy-to-understand decision trees, 2) leverage these policies to warm-start reinforcement learning and 3) outperform baselines that lack our natural language initialization mechanism. We train our approach by collecting a first-of-its-kind corpus mapping free-form natural language policy descriptions to decision tree-based policies. We show that our novel framework translates natural language to decision trees with a 96% and 97% accuracy on a held-out corpus across two domains, respectively. Finally, we validate that policies initialized with natural language commands are able to significantly outperform relevant baselines (p < 0.001) that do not benefit from our natural language-based warm-start technique.
Robot Object Retrieval with Contextual Natural Language Queries
Jun 23, 2020
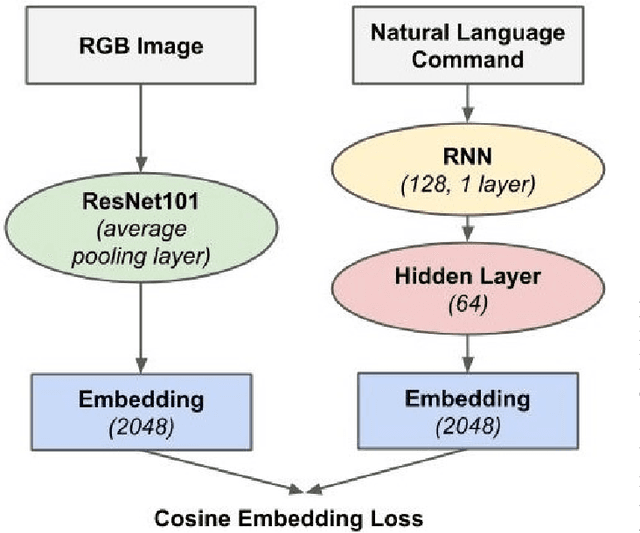
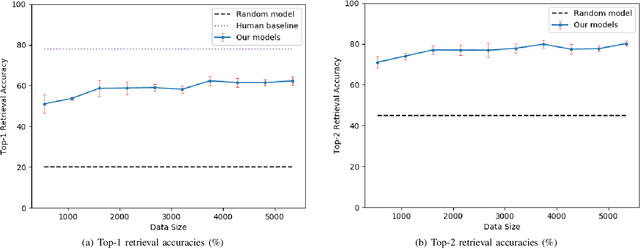

Natural language object retrieval is a highly useful yet challenging task for robots in human-centric environments. Previous work has primarily focused on commands specifying the desired object's type such as "scissors" and/or visual attributes such as "red," thus limiting the robot to only known object classes. We develop a model to retrieve objects based on descriptions of their usage. The model takes in a language command containing a verb, for example "Hand me something to cut," and RGB images of candidate objects and selects the object that best satisfies the task specified by the verb. Our model directly predicts an object's appearance from the object's use specified by a verb phrase. We do not need to explicitly specify an object's class label. Our approach allows us to predict high level concepts like an object's utility based on the language query. Based on contextual information present in the language commands, our model can generalize to unseen object classes and unknown nouns in the commands. Our model correctly selects objects out of sets of five candidates to fulfill natural language commands, and achieves an average accuracy of 62.3% on a held-out test set of unseen ImageNet object classes and 53.0% on unseen object classes and unknown nouns. Our model also achieves an average accuracy of 54.7% on unseen YCB object classes, which have a different image distribution from ImageNet objects. We demonstrate our model on a KUKA LBR iiwa robot arm, enabling the robot to retrieve objects based on natural language descriptions of their usage. We also present a new dataset of 655 verb-object pairs denoting object usage over 50 verbs and 216 object classes.
Grounding Language Attributes to Objects using Bayesian Eigenobjects
May 30, 2019
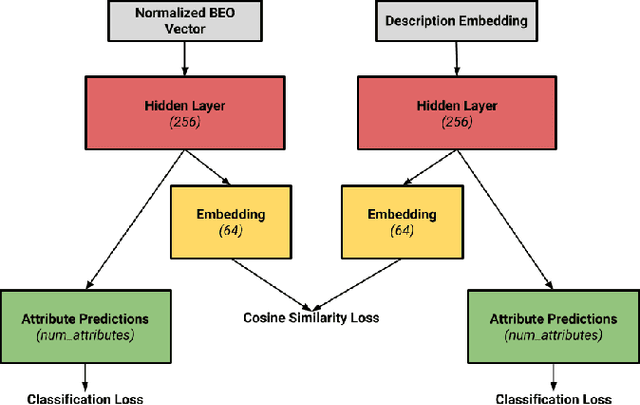
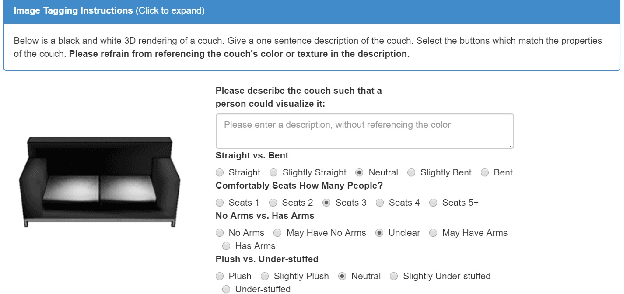
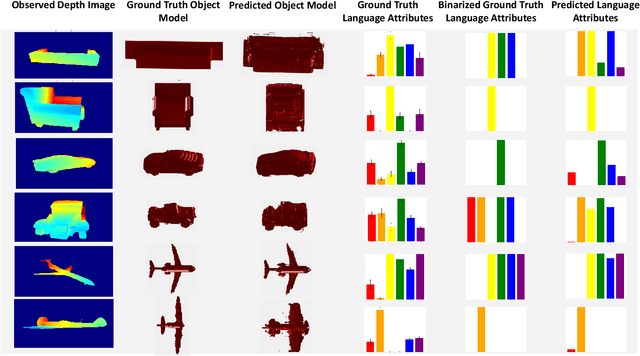
We develop a system to disambiguate objects based on simple physical descriptions. The system takes as input a natural language phrase and a depth image containing a segmented object and predicts how similar the observed object is to the described object. Our system is designed to learn from only a small amount of human-labeled language data and generalize to viewpoints not represented in the language-annotated depth-image training set. By decoupling 3D shape representation from language representation, our method is able to ground language to novel objects using a small amount of language-annotated depth-data and a larger corpus of unlabeled 3D object meshes, even when these objects are partially observed from unusual viewpoints. Our system is able to disambiguate between novel objects, observed via depth-images, based on natural language descriptions. Our method also enables view-point transfer; trained on human-annotated data on a small set of depth-images captured from frontal viewpoints, our system successfully predicted object attributes from rear views despite having no such depth images in its training set. Finally, we demonstrate our system on a Baxter robot, enabling it to pick specific objects based on human-provided natural language descriptions.
Mitigating Planner Overfitting in Model-Based Reinforcement Learning
Dec 03, 2018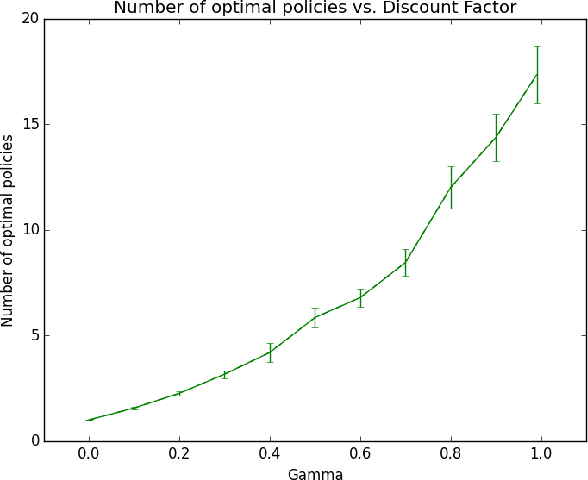
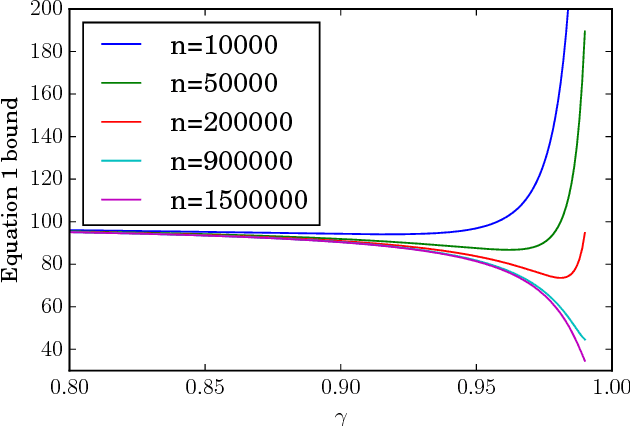
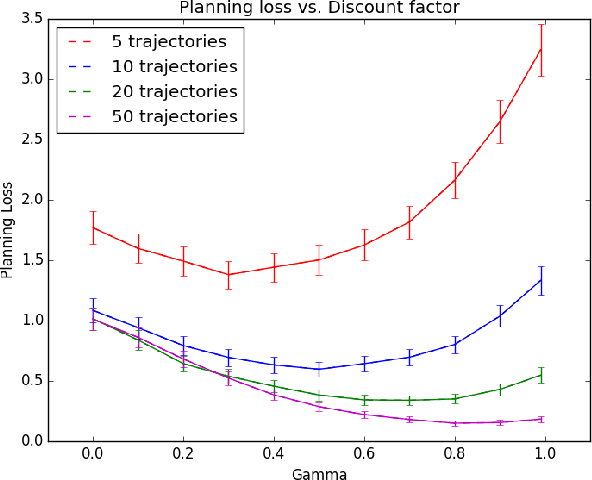
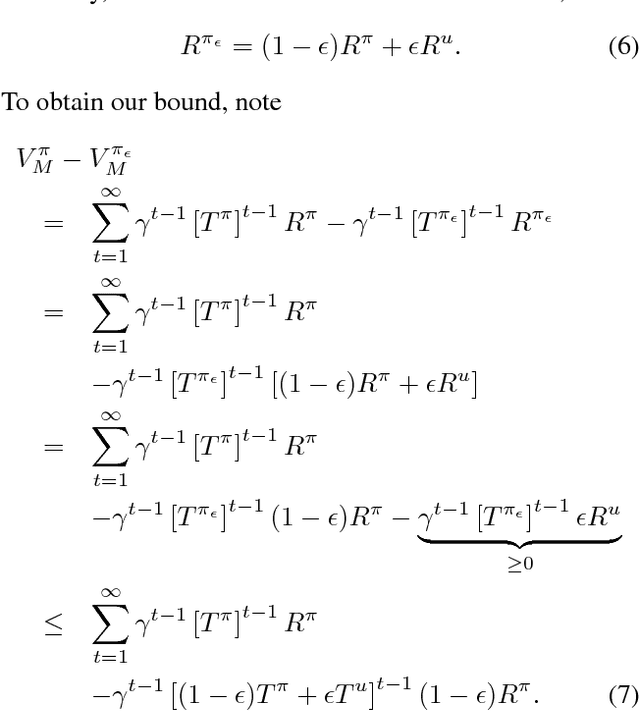
An agent with an inaccurate model of its environment faces a difficult choice: it can ignore the errors in its model and act in the real world in whatever way it determines is optimal with respect to its model. Alternatively, it can take a more conservative stance and eschew its model in favor of optimizing its behavior solely via real-world interaction. This latter approach can be exceedingly slow to learn from experience, while the former can lead to "planner overfitting" - aspects of the agent's behavior are optimized to exploit errors in its model. This paper explores an intermediate position in which the planner seeks to avoid overfitting through a kind of regularization of the plans it considers. We present three different approaches that demonstrably mitigate planner overfitting in reinforcement-learning environments.
Accurately and Efficiently Interpreting Human-Robot Instructions of Varying Granularities
Jun 19, 2018
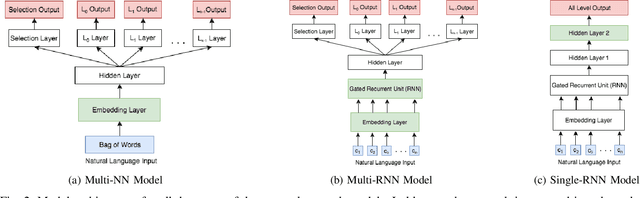


Humans can ground natural language commands to tasks at both abstract and fine-grained levels of specificity. For instance, a human forklift operator can be instructed to perform a high-level action, like "grab a pallet" or a low-level action like "tilt back a little bit." While robots are also capable of grounding language commands to tasks, previous methods implicitly assume that all commands and tasks reside at a single, fixed level of abstraction. Additionally, methods that do not use multiple levels of abstraction encounter inefficient planning and execution times as they solve tasks at a single level of abstraction with large, intractable state-action spaces closely resembling real world complexity. In this work, by grounding commands to all the tasks or subtasks available in a hierarchical planning framework, we arrive at a model capable of interpreting language at multiple levels of specificity ranging from coarse to more granular. We show that the accuracy of the grounding procedure is improved when simultaneously inferring the degree of abstraction in language used to communicate the task. Leveraging hierarchy also improves efficiency: our proposed approach enables a robot to respond to a command within one second on 90% of our tasks, while baselines take over twenty seconds on half the tasks. Finally, we demonstrate that a real, physical robot can ground commands at multiple levels of abstraction allowing it to efficiently plan different subtasks within the same planning hierarchy.