 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBob Zhang
CDIMC-net: Cognitive Deep Incomplete Multi-view Clustering Network
Mar 28, 2024
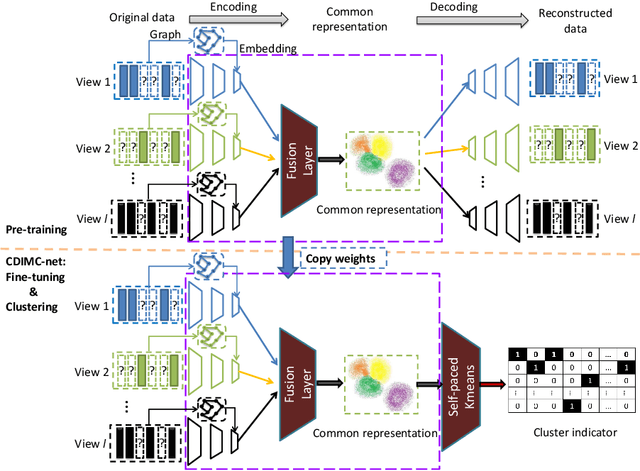

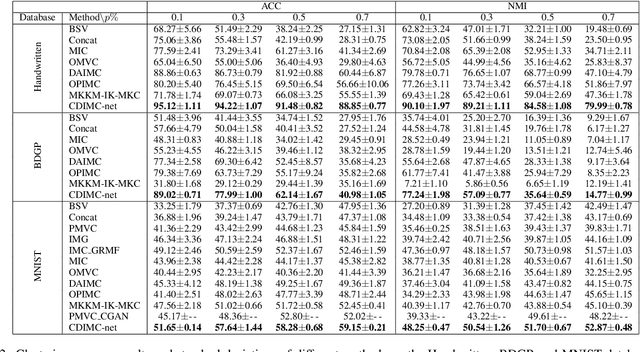
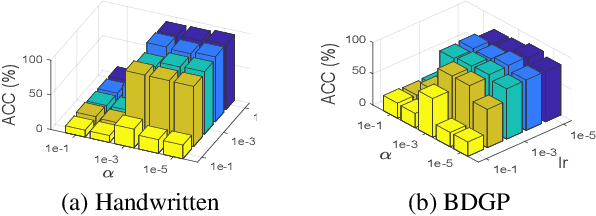
In recent years, incomplete multi-view clustering, which studies the challenging multi-view clustering problem on missing views, has received growing research interests. Although a series of methods have been proposed to address this issue, the following problems still exist: 1) Almost all of the existing methods are based on shallow models, which is difficult to obtain discriminative common representations. 2) These methods are generally sensitive to noise or outliers since the negative samples are treated equally as the important samples. In this paper, we propose a novel incomplete multi-view clustering network, called Cognitive Deep Incomplete Multi-view Clustering Network (CDIMC-net), to address these issues. Specifically, it captures the high-level features and local structure of each view by incorporating the view-specific deep encoders and graph embedding strategy into a framework. Moreover, based on the human cognition, i.e., learning from easy to hard, it introduces a self-paced strategy to select the most confident samples for model training, which can reduce the negative influence of outliers. Experimental results on several incomplete datasets show that CDIMC-net outperforms the state-of-the-art incomplete multi-view clustering methods.
Open-Vocabulary Calibration for Vision-Language Models
Feb 15, 2024Vision-language models (VLMs) have emerged as formidable tools, showing their strong capability in handling various open-vocabulary tasks in image recognition, text-driven visual content generation, and visual chatbots, to name a few. In recent years, considerable efforts and resources have been devoted to adaptation methods for improving downstream performance of VLMs, particularly on parameter-efficient fine-tuning methods like prompt learning. However, a crucial aspect that has been largely overlooked is the confidence calibration problem in fine-tuned VLMs, which could greatly reduce reliability when deploying such models in the real world. This paper bridges the gap by systematically investigating the confidence calibration problem in the context of prompt learning and reveals that existing calibration methods are insufficient to address the problem, especially in the open-vocabulary setting. To solve the problem, we present a simple and effective approach called Distance-Aware Calibration (DAC), which is based on scaling the temperature using as guidance the distance between predicted text labels and base classes. The experiments with 7 distinct prompt learning methods applied across 11 diverse downstream datasets demonstrate the effectiveness of DAC, which achieves high efficacy without sacrificing the inference speed.
Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition
Oct 28, 2023



Human Activity Recognition (HAR) models often suffer from performance degradation in real-world applications due to distribution shifts in activity patterns across individuals. Test-Time Adaptation (TTA) is an emerging learning paradigm that aims to utilize the test stream to adjust predictions in real-time inference, which has not been explored in HAR before. However, the high computational cost of optimization-based TTA algorithms makes it intractable to run on resource-constrained edge devices. In this paper, we propose an Optimization-Free Test-Time Adaptation (OFTTA) framework for sensor-based HAR. OFTTA adjusts the feature extractor and linear classifier simultaneously in an optimization-free manner. For the feature extractor, we propose Exponential DecayTest-time Normalization (EDTN) to replace the conventional batch normalization (CBN) layers. EDTN combines CBN and Test-time batch Normalization (TBN) to extract reliable features against domain shifts with TBN's influence decreasing exponentially in deeper layers. For the classifier, we adjust the prediction by computing the distance between the feature and the prototype, which is calculated by a maintained support set. In addition, the update of the support set is based on the pseudo label, which can benefit from reliable features extracted by EDTN. Extensive experiments on three public cross-person HAR datasets and two different TTA settings demonstrate that OFTTA outperforms the state-of-the-art TTA approaches in both classification performance and computational efficiency. Finally, we verify the superiority of our proposed OFTTA on edge devices, indicating possible deployment in real applications. Our code is available at \href{https://github.com/Claydon-Wang/OFTTA}{this https URL}.
Physics-Driven Spectrum-Consistent Federated Learning for Palmprint Verification
Aug 01, 2023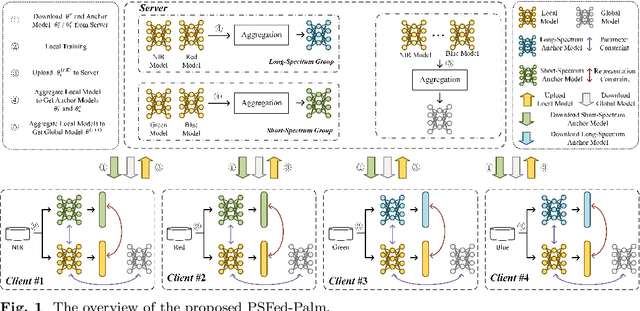

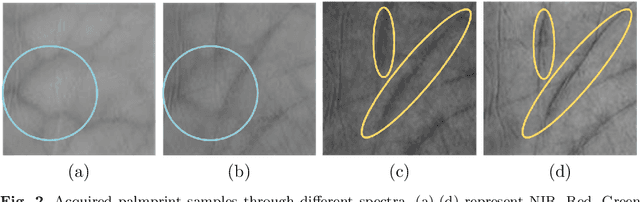
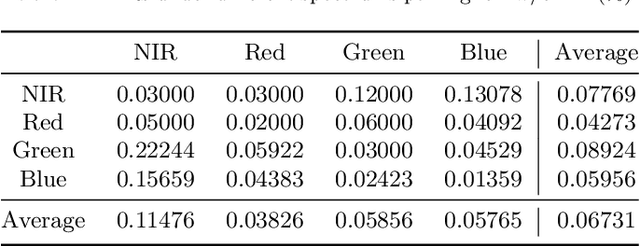
Palmprint as biometrics has gained increasing attention recently due to its discriminative ability and robustness. However, existing methods mainly improve palmprint verification within one spectrum, which is challenging to verify across different spectrums. Additionally, in distributed server-client-based deployment, palmprint verification systems predominantly necessitate clients to transmit private data for model training on the centralized server, thereby engendering privacy apprehensions. To alleviate the above issues, in this paper, we propose a physics-driven spectrum-consistent federated learning method for palmprint verification, dubbed as PSFed-Palm. PSFed-Palm draws upon the inherent physical properties of distinct wavelength spectrums, wherein images acquired under similar wavelengths display heightened resemblances. Our approach first partitions clients into short- and long-spectrum groups according to the wavelength range of their local spectrum images. Subsequently, we introduce anchor models for short- and long-spectrum, which constrain the optimization directions of local models associated with long- and short-spectrum images. Specifically, a spectrum-consistent loss that enforces the model parameters and feature representation to align with their corresponding anchor models is designed. Finally, we impose constraints on the local models to ensure their consistency with the global model, effectively preventing model drift. This measure guarantees spectrum consistency while protecting data privacy, as there is no need to share local data. Extensive experiments are conducted to validate the efficacy of our proposed PSFed-Palm approach. The proposed PSFed-Palm demonstrates compelling performance despite only a limited number of training data. The codes will be released at https://github.com/Zi-YuanYang/PSFed-Palm.
A Distributed Computation Model Based on Federated Learning Integrates Heterogeneous models and Consortium Blockchain for Solving Time-Varying Problems
Jun 28, 2023The recurrent neural network has been greatly developed for effectively solving time-varying problems corresponding to complex environments. However, limited by the way of centralized processing, the model performance is greatly affected by factors like the silos problems of the models and data in reality. Therefore, the emergence of distributed artificial intelligence such as federated learning (FL) makes it possible for the dynamic aggregation among models. However, the integration process of FL is still server-dependent, which may cause a great risk to the overall model. Also, it only allows collaboration between homogeneous models, and does not have a good solution for the interaction between heterogeneous models. Therefore, we propose a Distributed Computation Model (DCM) based on the consortium blockchain network to improve the credibility of the overall model and effective coordination among heterogeneous models. In addition, a Distributed Hierarchical Integration (DHI) algorithm is also designed for the global solution process. Within a group, permissioned nodes collect the local models' results from different permissionless nodes and then sends the aggregated results back to all the permissionless nodes to regularize the processing of the local models. After the iteration is completed, the secondary integration of the local results will be performed between permission nodes to obtain the global results. In the experiments, we verify the efficiency of DCM, where the results show that the proposed model outperforms many state-of-the-art models based on a federated learning framework.
Multi-stage image denoising with the wavelet transform
Oct 03, 2022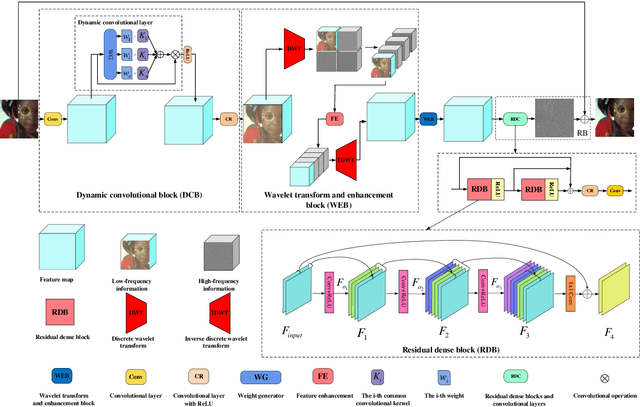

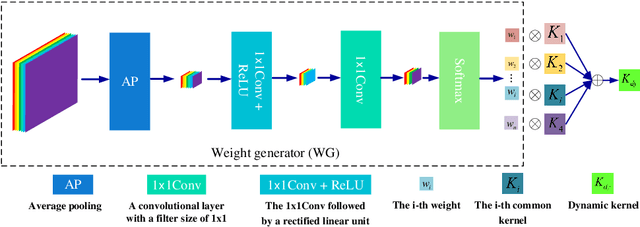
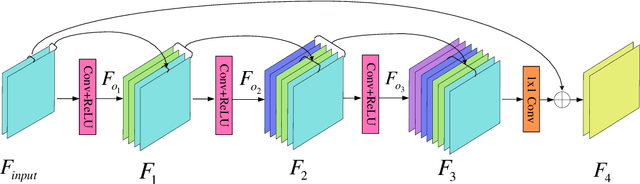
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and a residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
A Survey on Incomplete Multi-view Clustering
Aug 17, 2022
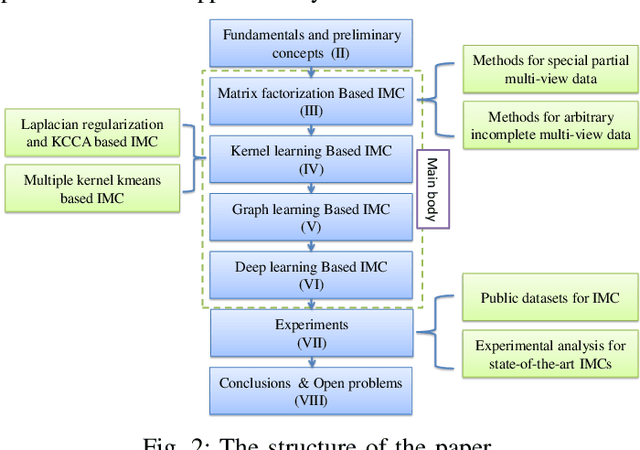
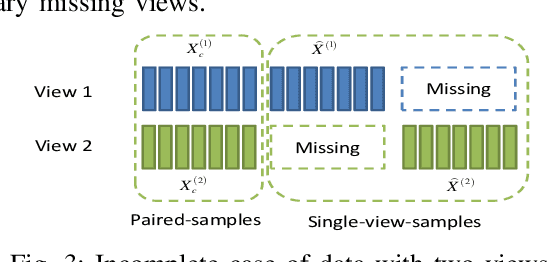
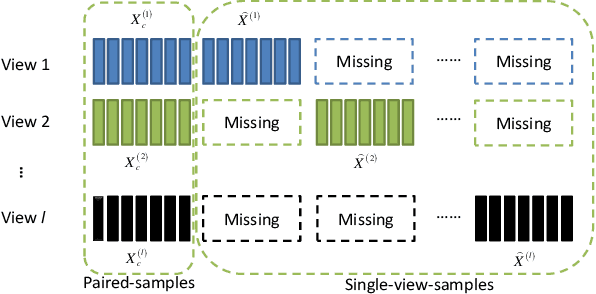
Conventional multi-view clustering seeks to partition data into respective groups based on the assumption that all views are fully observed. However, in practical applications, such as disease diagnosis, multimedia analysis, and recommendation system, it is common to observe that not all views of samples are available in many cases, which leads to the failure of the conventional multi-view clustering methods. Clustering on such incomplete multi-view data is referred to as incomplete multi-view clustering. In view of the promising application prospects, the research of incomplete multi-view clustering has noticeable advances in recent years. However, there is no survey to summarize the current progresses and point out the future research directions. To this end, we review the recent studies of incomplete multi-view clustering. Importantly, we provide some frameworks to unify the corresponding incomplete multi-view clustering methods, and make an in-depth comparative analysis for some representative methods from theoretical and experimental perspectives. Finally, some open problems in the incomplete multi-view clustering field are offered for researchers.
NFANet: A Novel Method for Weakly Supervised Water Extraction from High-Resolution Remote Sensing Imagery
Jan 10, 2022



The use of deep learning for water extraction requires precise pixel-level labels. However, it is very difficult to label high-resolution remote sensing images at the pixel level. Therefore, we study how to utilize point labels to extract water bodies and propose a novel method called the neighbor feature aggregation network (NFANet). Compared with pixellevel labels, point labels are much easier to obtain, but they will lose much information. In this paper, we take advantage of the similarity between the adjacent pixels of a local water-body, and propose a neighbor sampler to resample remote sensing images. Then, the sampled images are sent to the network for feature aggregation. In addition, we use an improved recursive training algorithm to further improve the extraction accuracy, making the water boundary more natural. Furthermore, our method utilizes neighboring features instead of global or local features to learn more representative features. The experimental results show that the proposed NFANet method not only outperforms other studied weakly supervised approaches, but also obtains similar results as the state-of-the-art ones.
Noise Homogenization via Multi-Channel Wavelet Filtering for High-Fidelity Sample Generation in GANs
May 14, 2020



In the generator of typical Generative Adversarial Networks (GANs), a noise is inputted to generate fake samples via a series of convolutional operations. However, current noise generation models merely relies on the information from the pixel space, which increases the difficulty to approach the target distribution. Fortunately, the long proven wavelet transformation is able to decompose multiple spectral information from the images. In this work, we propose a novel multi-channel wavelet-based filtering method for GANs, to cope with this problem. When embedding a wavelet deconvolution layer in the generator, the resultant GAN, called WaveletGAN, takes advantage of the wavelet deconvolution to learn a filtering with multiple channels, which can efficiently homogenize the generated noise via an averaging operation, so as to generate high-fidelity samples. We conducted benchmark experiments on the Fashion-MNIST, KMNIST and SVHN datasets through an open GAN benchmark tool. The results show that WaveletGAN has excellent performance in generating high-fidelity samples, thanks to the smallest FIDs obtained on these datasets.
Two-stage Image Classification Supervised by a Single Teacher Single Student Model
Sep 26, 2019



The two-stage strategy has been widely used in image classification. However, these methods barely take the classification criteria of the first stage into consideration in the second prediction stage. In this paper, we propose a novel two-stage representation method (TSR), and convert it to a Single-Teacher Single-Student (STSS) problem in our two-stage image classification framework. We seek the nearest neighbours of the test sample to choose candidate target classes. Meanwhile, the first stage classifier is formulated as the teacher, which holds the classification scores. The samples of the candidate classes are utilized to learn a student classifier based on L2-minimization in the second stage. The student will be supervised by the teacher classifier, which approves the student only if it obtains a higher score. In actuality, the proposed framework generates a stronger classifier by staging two weaker classifiers in a novel way. The experiments conducted on several face and object databases show that our proposed framework is effective and outperforms multiple popular classification methods.