 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Wen
Multimodal Fusion on Low-quality Data: A Comprehensive Survey
Apr 27, 2024
Multimodal fusion focuses on integrating information from multiple modalities with the goal of more accurate prediction, which has achieved remarkable progress in a wide range of scenarios, including autonomous driving and medical diagnosis. However, the reliability of multimodal fusion remains largely unexplored especially under low-quality data settings. This paper surveys the common challenges and recent advances of multimodal fusion in the wild and presents them in a comprehensive taxonomy. From a data-centric view, we identify four main challenges that are faced by multimodal fusion on low-quality data, namely (1) noisy multimodal data that are contaminated with heterogeneous noises, (2) incomplete multimodal data that some modalities are missing, (3) imbalanced multimodal data that the qualities or properties of different modalities are significantly different and (4) quality-varying multimodal data that the quality of each modality dynamically changes with respect to different samples. This new taxonomy will enable researchers to understand the state of the field and identify several potential directions. We also provide discussion for the open problems in this field together with interesting future research directions.
Masked Two-channel Decoupling Framework for Incomplete Multi-view Weak Multi-label Learning
Apr 26, 2024Multi-view learning has become a popular research topic in recent years, but research on the cross-application of classic multi-label classification and multi-view learning is still in its early stages. In this paper, we focus on the complex yet highly realistic task of incomplete multi-view weak multi-label learning and propose a masked two-channel decoupling framework based on deep neural networks to solve this problem. The core innovation of our method lies in decoupling the single-channel view-level representation, which is common in deep multi-view learning methods, into a shared representation and a view-proprietary representation. We also design a cross-channel contrastive loss to enhance the semantic property of the two channels. Additionally, we exploit supervised information to design a label-guided graph regularization loss, helping the extracted embedding features preserve the geometric structure among samples. Inspired by the success of masking mechanisms in image and text analysis, we develop a random fragment masking strategy for vector features to improve the learning ability of encoders. Finally, it is important to emphasize that our model is fully adaptable to arbitrary view and label absences while also performing well on the ideal full data. We have conducted sufficient and convincing experiments to confirm the effectiveness and advancement of our model.
CDIMC-net: Cognitive Deep Incomplete Multi-view Clustering Network
Mar 28, 2024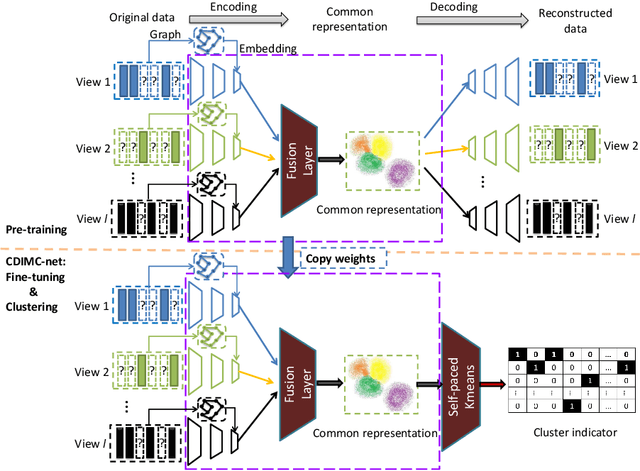

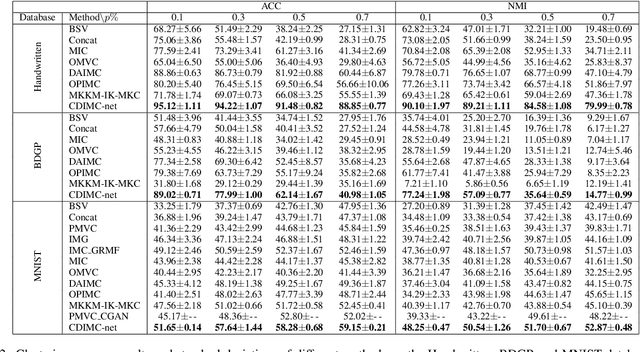
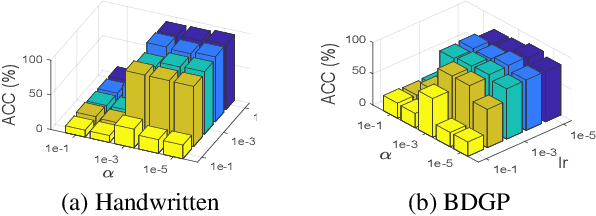
In recent years, incomplete multi-view clustering, which studies the challenging multi-view clustering problem on missing views, has received growing research interests. Although a series of methods have been proposed to address this issue, the following problems still exist: 1) Almost all of the existing methods are based on shallow models, which is difficult to obtain discriminative common representations. 2) These methods are generally sensitive to noise or outliers since the negative samples are treated equally as the important samples. In this paper, we propose a novel incomplete multi-view clustering network, called Cognitive Deep Incomplete Multi-view Clustering Network (CDIMC-net), to address these issues. Specifically, it captures the high-level features and local structure of each view by incorporating the view-specific deep encoders and graph embedding strategy into a framework. Moreover, based on the human cognition, i.e., learning from easy to hard, it introduces a self-paced strategy to select the most confident samples for model training, which can reduce the negative influence of outliers. Experimental results on several incomplete datasets show that CDIMC-net outperforms the state-of-the-art incomplete multi-view clustering methods.
Information Recovery-Driven Deep Incomplete Multi-view Clustering Network
Apr 02, 2023



Incomplete multi-view clustering is a hot and emerging topic. It is well known that unavoidable data incompleteness greatly weakens the effective information of multi-view data. To date, existing incomplete multi-view clustering methods usually bypass unavailable views according to prior missing information, which is considered as a second-best scheme based on evasion. Other methods that attempt to recover missing information are mostly applicable to specific two-view datasets. To handle these problems, in this paper, we propose an information recovery-driven deep incomplete multi-view clustering network, termed as RecFormer. Concretely, a two-stage autoencoder network with the self-attention structure is built to synchronously extract high-level semantic representations of multiple views and recover the missing data. Besides, we develop a recurrent graph reconstruction mechanism that cleverly leverages the restored views to promote the representation learning and the further data reconstruction. Visualization of recovery results are given and sufficient experimental results confirm that our RecFormer has obvious advantages over other top methods.
Learning Reliable Representations for Incomplete Multi-View Partial Multi-Label Classification
Mar 30, 2023



As a cross-topic of multi-view learning and multi-label classification, multi-view multi-label classification has gradually gained traction in recent years. The application of multi-view contrastive learning has further facilitated this process, however, the existing multi-view contrastive learning methods crudely separate the so-called negative pair, which largely results in the separation of samples belonging to the same category or similar ones. Besides, plenty of multi-view multi-label learning methods ignore the possible absence of views and labels. To address these issues, in this paper, we propose an incomplete multi-view partial multi-label classification network named RANK. In this network, a label-driven multi-view contrastive learning strategy is proposed to leverage supervised information to preserve the structure within view and perform consistent alignment across views. Furthermore, we break through the view-level weights inherent in existing methods and propose a quality-aware sub-network to dynamically assign quality scores to each view of each sample. The label correlation information is fully utilized in the final multi-label cross-entropy classification loss, effectively improving the discriminative power. Last but not least, our model is not only able to handle complete multi-view multi-label datasets, but also works on datasets with missing instances and labels. Extensive experiments confirm that our RANK outperforms existing state-of-the-art methods.
DICNet: Deep Instance-Level Contrastive Network for Double Incomplete Multi-View Multi-Label Classification
Mar 23, 2023



In recent years, multi-view multi-label learning has aroused extensive research enthusiasm. However, multi-view multi-label data in the real world is commonly incomplete due to the uncertain factors of data collection and manual annotation, which means that not only multi-view features are often missing, and label completeness is also difficult to be satisfied. To deal with the double incomplete multi-view multi-label classification problem, we propose a deep instance-level contrastive network, namely DICNet. Different from conventional methods, our DICNet focuses on leveraging deep neural network to exploit the high-level semantic representations of samples rather than shallow-level features. First, we utilize the stacked autoencoders to build an end-to-end multi-view feature extraction framework to learn the view-specific representations of samples. Furthermore, in order to improve the consensus representation ability, we introduce an incomplete instance-level contrastive learning scheme to guide the encoders to better extract the consensus information of multiple views and use a multi-view weighted fusion module to enhance the discrimination of semantic features. Overall, our DICNet is adept in capturing consistent discriminative representations of multi-view multi-label data and avoiding the negative effects of missing views and missing labels. Extensive experiments performed on five datasets validate that our method outperforms other state-of-the-art methods.
Incomplete Multi-View Multi-Label Learning via Label-Guided Masked View- and Category-Aware Transformers
Mar 13, 2023



As we all know, multi-view data is more expressive than single-view data and multi-label annotation enjoys richer supervision information than single-label, which makes multi-view multi-label learning widely applicable for various pattern recognition tasks. In this complex representation learning problem, three main challenges can be characterized as follows: i) How to learn consistent representations of samples across all views? ii) How to exploit and utilize category correlations of multi-label to guide inference? iii) How to avoid the negative impact resulting from the incompleteness of views or labels? To cope with these problems, we propose a general multi-view multi-label learning framework named label-guided masked view- and category-aware transformers in this paper. First, we design two transformer-style based modules for cross-view features aggregation and multi-label classification, respectively. The former aggregates information from different views in the process of extracting view-specific features, and the latter learns subcategory embedding to improve classification performance. Second, considering the imbalance of expressive power among views, an adaptively weighted view fusion module is proposed to obtain view-consistent embedding features. Third, we impose a label manifold constraint in sample-level representation learning to maximize the utilization of supervised information. Last but not least, all the modules are designed under the premise of incomplete views and labels, which makes our method adaptable to arbitrary multi-view and multi-label data. Extensive experiments on five datasets confirm that our method has clear advantages over other state-of-the-art methods.
Cross-view Graph Contrastive Representation Learning on Partially Aligned Multi-view Data
Nov 08, 2022



Multi-view representation learning has developed rapidly over the past decades and has been applied in many fields. However, most previous works assumed that each view is complete and aligned. This leads to an inevitable deterioration in their performance when encountering practical problems such as missing or unaligned views. To address the challenge of representation learning on partially aligned multi-view data, we propose a new cross-view graph contrastive learning framework, which integrates multi-view information to align data and learn latent representations. Compared with current approaches, the proposed method has the following merits: (1) our model is an end-to-end framework that simultaneously performs view-specific representation learning via view-specific autoencoders and cluster-level data aligning by combining multi-view information with the cross-view graph contrastive learning; (2) it is easy to apply our model to explore information from three or more modalities/sources as the cross-view graph contrastive learning is devised. Extensive experiments conducted on several real datasets demonstrate the effectiveness of the proposed method on the clustering and classification tasks.
A Survey on Incomplete Multi-view Clustering
Aug 17, 2022
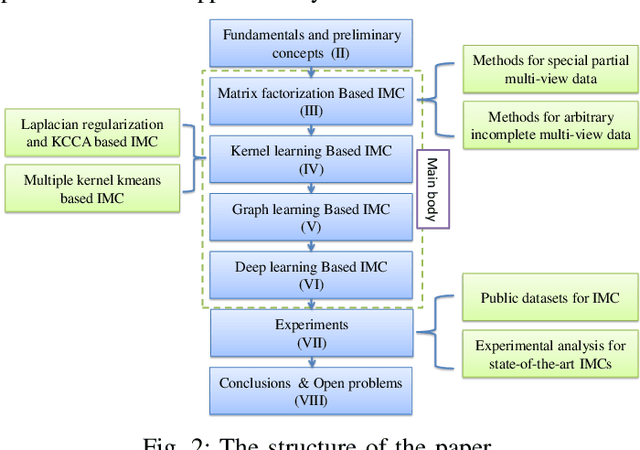
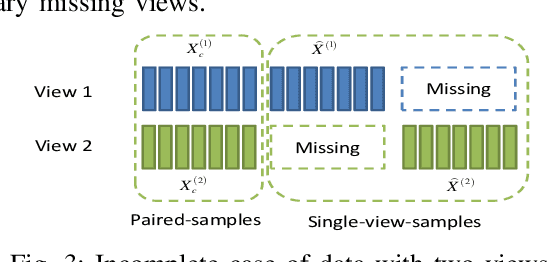
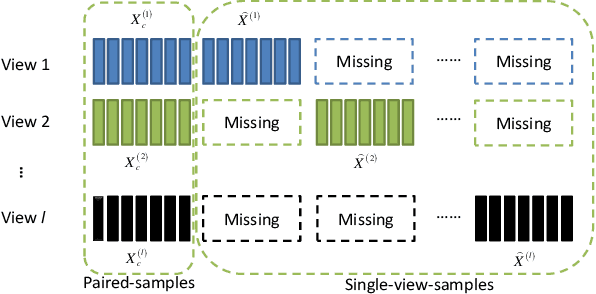
Conventional multi-view clustering seeks to partition data into respective groups based on the assumption that all views are fully observed. However, in practical applications, such as disease diagnosis, multimedia analysis, and recommendation system, it is common to observe that not all views of samples are available in many cases, which leads to the failure of the conventional multi-view clustering methods. Clustering on such incomplete multi-view data is referred to as incomplete multi-view clustering. In view of the promising application prospects, the research of incomplete multi-view clustering has noticeable advances in recent years. However, there is no survey to summarize the current progresses and point out the future research directions. To this end, we review the recent studies of incomplete multi-view clustering. Importantly, we provide some frameworks to unify the corresponding incomplete multi-view clustering methods, and make an in-depth comparative analysis for some representative methods from theoretical and experimental perspectives. Finally, some open problems in the incomplete multi-view clustering field are offered for researchers.
Localized Sparse Incomplete Multi-view Clustering
Aug 05, 2022



Incomplete multi-view clustering, which aims to solve the clustering problem on the incomplete multi-view data with partial view missing, has received more and more attention in recent years. Although numerous methods have been developed, most of the methods either cannot flexibly handle the incomplete multi-view data with arbitrary missing views or do not consider the negative factor of information imbalance among views. Moreover, some methods do not fully explore the local structure of all incomplete views. To tackle these problems, this paper proposes a simple but effective method, named localized sparse incomplete multi-view clustering (LSIMVC). Different from the existing methods, LSIMVC intends to learn a sparse and structured consensus latent representation from the incomplete multi-view data by optimizing a sparse regularized and novel graph embedded multi-view matrix factorization model. Specifically, in such a novel model based on the matrix factorization, a l1 norm based sparse constraint is introduced to obtain the sparse low-dimensional individual representations and the sparse consensus representation. Moreover, a novel local graph embedding term is introduced to learn the structured consensus representation. Different from the existing works, our local graph embedding term aggregates the graph embedding task and consensus representation learning task into a concise term. Furthermore, to reduce the imbalance factor of incomplete multi-view learning, an adaptive weighted learning scheme is introduced to LSIMVC. Finally, an efficient optimization strategy is given to solve the optimization problem of our proposed model. Comprehensive experimental results performed on six incomplete multi-view databases verify that the performance of our LSIMVC is superior to the state-of-the-art IMC approaches. The code is available in https://github.com/justsmart/LSIMVC.